Introducing Pharia-1-LLM: transparent and compliant

Pharia-1-LLM-7B
We are pleased to announce our new foundation model family that includes Pharia-1-LLM-7B-control and Pharia-1-LLM-7B-control-aligned, now publicly available under the Open Aleph License, which explicitly allows for non-commercial research and educational use. Pharia-1-LLM-7B-control is engineered to deliver concise, length-controlled responses that match the performance of leading open-source models in the 7B to 8B parameter range and is culturally and linguistically optimized for German, French, and Spanish by being trained on a multilingual base corpus. Pharia-1-LLM-7B-control is trained on carefully curated data in compliance with applicable EU and national regulations, including copyright and data privacy laws. With improved token efficiency, Pharia-1-LLM-7B-control excels in domain-specific applications, particularly in the automotive and engineering industries, and can be aligned to user preferences, making it suitable for critical applications without the risk of shutdown behavior. As such, it serves as a valuable addition to the community’s selection of weight-available foundation models. Pharia-1-LLM-7B-control-aligned has been added with additional safety guardrails via alignment methods.
Accompanying the model card, this blog post details our approach to building the Pharia-1-LLM-7B-control model.
Dataset
We disclose details of the data used for training Pharia-1-LLM-7B-control in the model card.
Model architecture & hyperparameters
For our choice of architecture and hyperparameters, we conducted several ablations that we describe in this section. If not mentioned otherwise, experiments were conducted on a model scale of 1B parameters. Ablations were evaluated on the standard pre-training benchmarks lambada, triviaqa, hellaswag, winogrande, webqs, arc, and boolq. Performance on other benchmarks remained negligible or showed mostly noisy behavior.
Hyperparameter scheme & scaling strategy
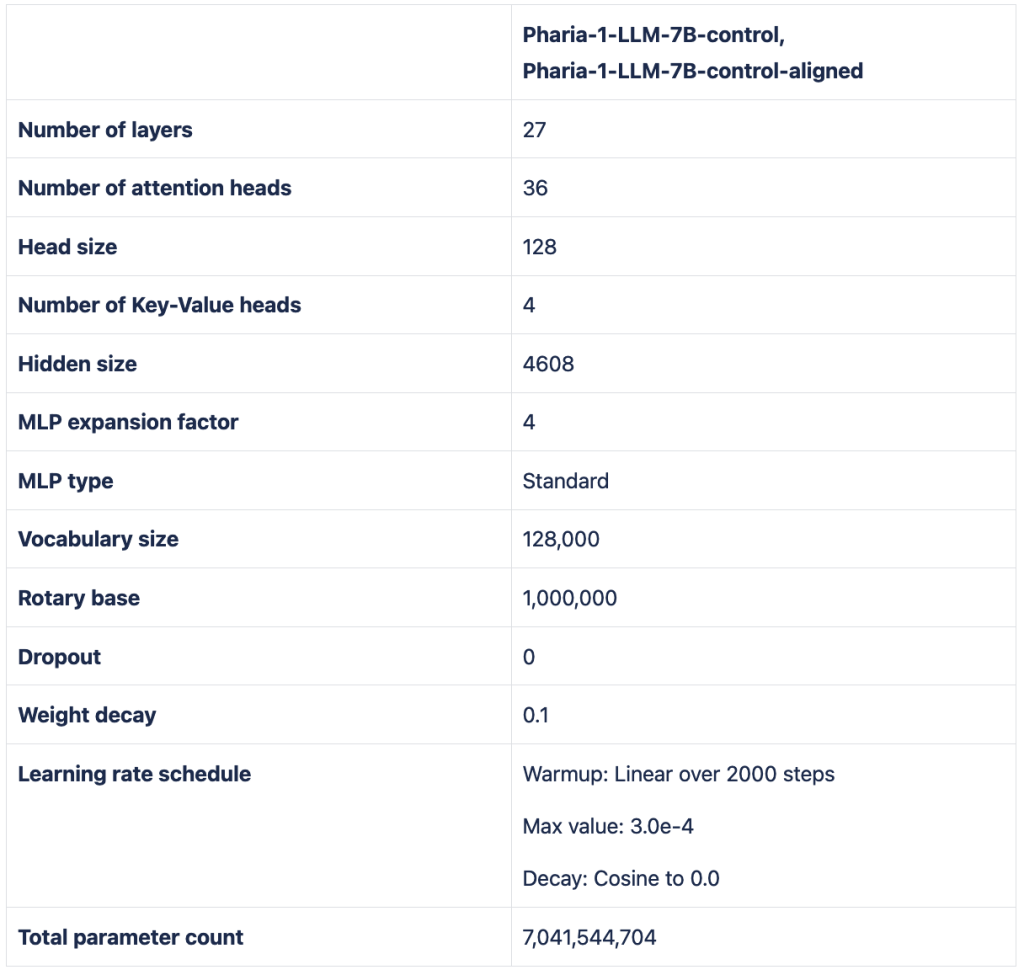
Our initial plan was to sweep the values for learning rate, global init std gain, embedding multiplier, and output multiplier on a small proxy model with hidden size 256 and 27 layers (matching the number of layers in the target model) and then upscale these to the target hidden size in accordance with the rules of Maximal Update Parametrization (MuP).
We used this method to find our hyperparameters for the 1B size ablations and performed a short 7B sanity check run that turned out positive.
However, we encountered severe training instabilities on the 7B scale when only slightly deviating from the original config (for example swapping the dataset or changing sequence length).
While not all contributing factors of the instabilities are comprehensively known and fully understood, MuP seems to be one of them. Therefore, we decided not to use it for this model training. By now we have a better understanding of how to make MuP work for transformers and have published this paper introducing a slightly modified and numerically stable version of MuP.
Instead of MuP we relied on heuristics for our pre-training runs. We used the same learning rate as Llama 2 while using a standard initialization scheme for the weights.
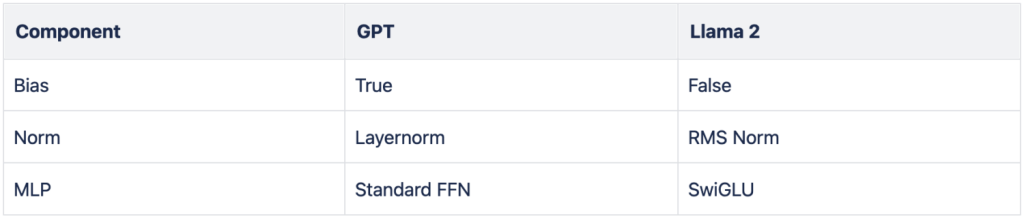
GPT vs Llama 2
We compared the classical GPT transformer architecture to the one popularized by the Llama 2 architecture, with the differences between the two listed in the table below. For both architectures, we used RoPE positional embeddings. In this setting, both architectures perform very similarly in terms of loss and downstream scores. On benchmarks, we observed one notable outlier, TriviaQA, where the GPT architecture performed considerably better. We reproduced this behavior on the 7B scale, although with a smaller number of training iterations, and concluded that the standard GPT architecture has a slight edge. Hence, we settled on this architecture for Pharia-1-LLM-7B models.
Group-Query-Attention (GQA)
With the goal of improving inference-time performance, we performed ablations on the use of Group-Query-Attention. We first investigated how model performance is impacted by fewer kv heads. Since models with more parameters usually perform better when trained on the same amount of data, we tried to keep the total parameter count in our experiments constant for a fair comparison. We achieved this by adding extra layers to compensate for removed kv parameters. In doing so, the parameter count of the models we compared differed by maximally 5% of the total parameter count. In this parameter-normalized setting, we did not observe any significant degradation when using fewer kv heads.
At the same time, we measured substantial advantages in memory consumption and increased throughput up to a kv-q ratio of 1/8, after which we did not measure substantial gains. We therefore decided to use group query attention at a ratio not too far from 1/8, settling on 1/9 for our final 7B model.
Rotary base
For increased long-context ability, Code Llama suggests using a larger base of 1e6 for the rotary embeddings. We investigated whether a larger base is harmful for pre-training. On the 1B scale, this is not the case, with downstream scores even slightly better than using the default base of 1e4. We therefore applied the larger base of 1e6 during pre-training.
Tokenizer
We trained a family of tokenizers with different vocabulary sizes (64k, 96k, 128k, 160k, and 192k) and training algorithms (BPE and Unigram). For both algorithms, we used the SentencePiece library. For the training set, we subsampled our high-quality dataset. With each tokenizer we trained a 1B model, only altering the embedding and head dimensions. Every model was trained for 380B tokens at a token batch size of 2M. On downstream tasks, BPE was mostly outperformed by Unigram. As for vocabulary size, we found an increase in scores up to 128k, after which performance reached a plateau. We therefore chose a Unigram tokenizer with 128k vocabulary size as our final tokenizer.
In parallel to these established efforts at better tokenization, we have begun a more innovative work stream “tokenizer-free” that we are investigating further for future model releases.
Weight decay & Dropout
Assuming a thorough data pre-processing, in large-scale pre-training there are no repeated training data samples, and hence there is no real potential for overfitting and regularization techniques are less important. For this reason, we a priori decided not to use any dropout. As for weight decay, literature and tribal knowledge suggest that a non-zero value can stabilize training with AdamW and lead to better convergence in pre-training scenarios. To test this claim, we evaluated three values of weight decay, 0, 1e-2, and 1e-1, and confirmed that 1e-1 weight decay leads to the best downstream scores on the 1B scale, so we decided to use this value.
Learning rate decay
We briefly revisited the decay schedule (keeping the decay style constant to a cosine decay), ablating decaying to 0 vs. 10% of the learning rate. Decaying to 0 yielded slightly better downstream scores, so we chose this value. We acknowledge that this is probably a more complex topic that is also entangled with questions of data mix and data curriculum. A comprehensive study in this direction was out of scope for this model training.
Pre-training
Training of our Pharia-1-LLM-7B base model was performed using our Scaling code base, which we release alongside the models. We leveraged Scaling’s parallelization capabilities and performance optimizations: We used the bfloat16 format and trained with a standard mixed-precision strategy, keeping a master copy of the weights as well as optimizer states in full precision. We shared the full-precision tensors across data-parallel workers (ZeRO stage 1).
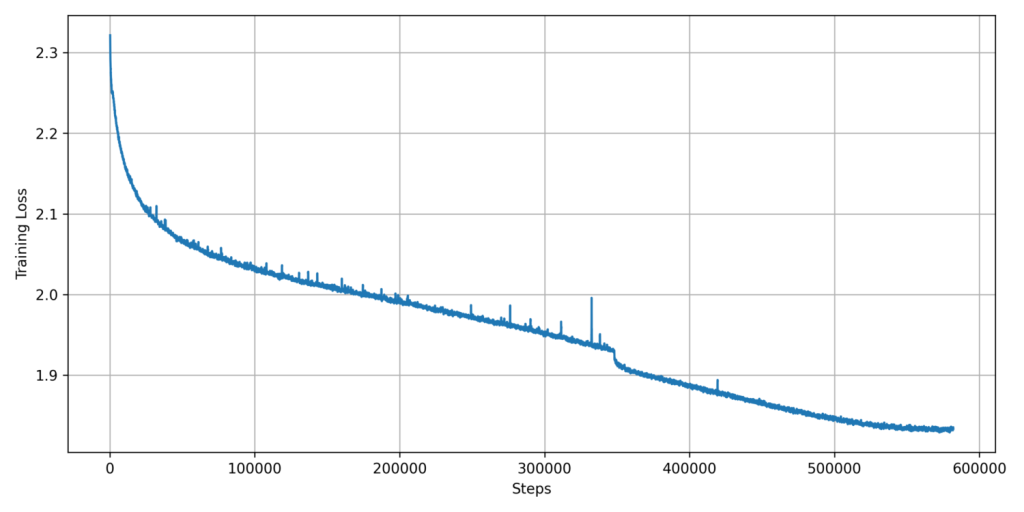
We performed pre-training at a sequence length of 8192 tokens to achieve reasonable baseline long-context abilities during the pre-training phase. Please note that we will perform long-context adaptations for later iterations of the model family. In our experiments, when scaling up the sequence length, we observed instabilities early in training. Therefore, we employed a sequence length warm-up strategy, scaling the sequence length from 512 to 2048, and then to the target of 8192 over a few thousand steps. The exact schedule was chosen ad hoc. We trained at a global batch size of 1024 for a total amount of 4.7T tokens, which is a single epoch of our first pre-training dataset part.
After the initial pre-training concluded, we decided to train for another epoch on a different data mix, leveraging additional data that had become available to us at this later stage of model development. We performed experiments with different data mixes, trying to expand on the newly available high-quality English data but ensuring that the model retains multi-lingual performance by mixing in non-English data from our first pre-training step.
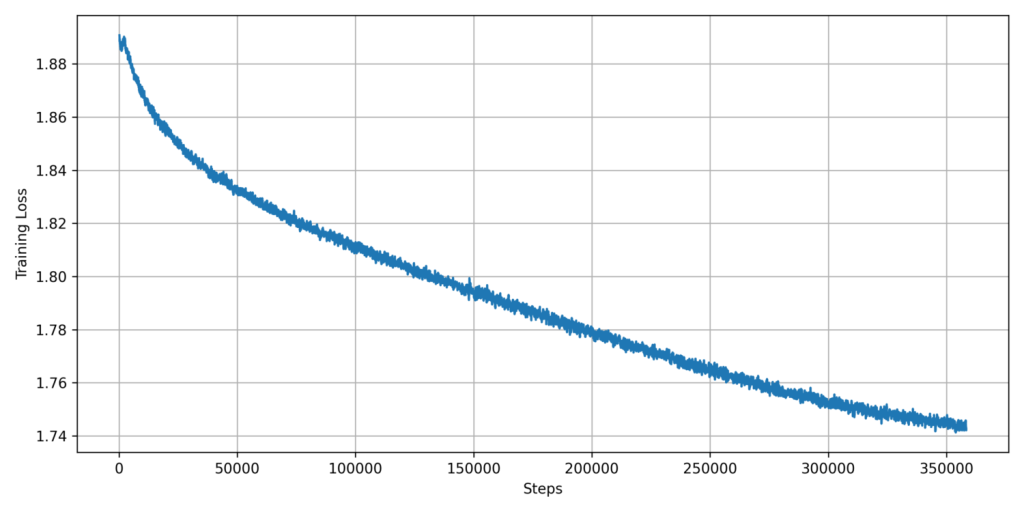
We trained Pharia-1-LLM-7B base model on a single epoch of the second data mix for another 3T tokens. Since the learning rate decayed to 0 after the first pre-training, we performed another warmup phase for 2000 iterations to a learning rate of 3e-5, which is 10% of our original maximum learning rate, and decayed this value to 3e-6 throughout training, following a cosine schedule.
With both pre-training phases, Pharia-1-LLM-7B base was trained for a total of 7.7T tokens.
We used 256 A100 GPUs for the training on our first data mix and 256 H100 GPUs for training on the second data mix. The layout of the model was optimized for throughput.

We did not use activation checkpointing, since we found other memory reduction techniques (PP, low micro-batch size) to result in better throughput.
Overall, we achieved the following step durations and average MFU:

The pre-training loss curves for the two training phases of Pharia-1-LLM-7B base are depicted in the following figures. They display a rolling median over the per-batch training loss with a window size of 200 steps. The drop in the loss around 350k steps resulted from an ad-hoc reduction in the learning rate.
Fine-tuning
We optimized Pharia-1-LLM-7B-control for instruction following using a full model fine-tuning approach. We trained using a curriculum strategy where the model was first training using a blend of instruction datasets, including source available, self-created and procured proprietary datasets. To ensure optimal performance across languages, we included fine-tuning data for all English, German, Spanish & French. Instructions included multi-turn as well as single-turn interactions. In order to limit data to the bare minimum required to train performant models, all metadata, e.g., EXIF, and other potentially personalized information on the people who created the data has been removed in the early stages of our data pipeline.
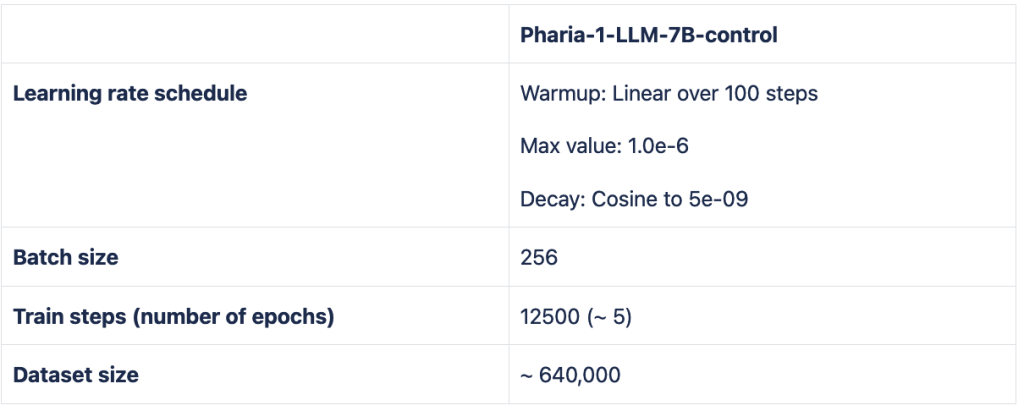
The resulting model was further fine-tuned using a curriculum strategy, whereby more difficult instructions are shown at the end of training. Here, we used a blend of high-quality proprietary datasets in English only.
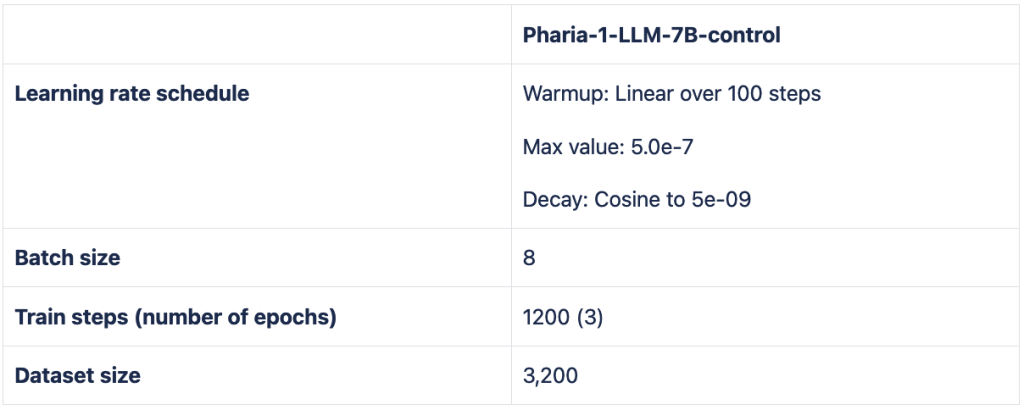
The data used for instruction fine-tuning contains source-available, commercially usable datasets, as well as self-created and procured proprietary datasets.
As part of our upcoming Model Suite release, we are introducing two distinct variants of the 7B model.
Pharia-1-LLM-7B-control-aligned is an instruction-tuned model that has been further refined through human and LLM preferences. In this alignment process, we employed KTO with a learning rate of 1e-6 and a beta parameter of 0.1. During initial training, we observed that the model began to produce partial repetitions. To address this, we filtered out generated samples with repetitions and included them as negative preferences in the data mix. Additionally, we incorporated a safety dataset, which helps the model reject unsafe prompts by treating safe responses as positive examples and unsafe responses from the Pharia-1-LLM-7B-control model as negative examples.
Pharia-1-LLM-7B-control is the instruction-tuned model without any preference alignment. This variant did not undergo additional safety training. We found that adding the KTO step made the model produce more verbose, generic answers. The KTO-aligned model also became less responsive to specific instructions, such as adhering to a desired output length, even though it showed improved scores across common instruction-tuning benchmarks. We believe this is due to the increased use of synthetic data in the datasets and the tendency of LLM-based evaluation methods to favor verbosity.
The Pharia-1-LLM-7B-control-aligned model, with its preference alignment and safety training, is well-suited for conversational use cases where clarity, safety, and adherence to user intent are crucial. Its refined responses make it ideal for interactive applications like chatbots or virtual assistants. On the other hand, Pharia-1-LLM-7B-control, without the added alignment, excels in tasks like extraction and summarization, where more direct and less verbose outputs are often preferred.
Evaluation
Evaluation in Generative AI (GenAI) is inherently complex due to the ambiguous nature of language. Unlike other areas of AI, where tasks have clearly defined metrics, language is subjective and open to multiple interpretations. This makes it difficult to create standardized evaluation metrics that can reliably assess the performance of GenAI models. Ambiguity in language means that a single output can be judged differently depending on the context or the evaluation method, making the evaluation process, especially automated, not straightforward. Even when evaluation criteria are clear, it is shown that human annotators value assertiveness and length more than factuality and faithfulness.
Evaluations also suffer from several shortcomings traceable to the training and architecture of models resulting in a lack of robustness of evaluation scores. The performance of a model is often highly dependent on minute details of the implementation. This can include details on the composition of the prompt, ordering of answers & positional bias of the model, the bias introduced via few-shot examples, the choice of evaluation metric, and even details of the inference engine. For instance, Alzahrani, Alyahya et al. show that changing the order of choices in the MMLU benchmark can cause a significant decrease in accuracy of up to 8 percentage points.
Further, when comparing evaluation scores with results seen on other models, one should keep in mind that in some cases evaluation data might have leaked into the pre-training or even fine-tuning data, causing models to overfit on these previously seen examples. Evidence for this was provided by Zhang et al., who created a dataset to mirror the complexity and style of the popular GSM8K benchmark and found that some models score up to 13 percentage points lower on their dataset compared to GSM8K. This level of noise makes a true verdict on the propensity of a model inherently challenging.
In addition, tasks in GenAI are often poorly defined or not representative of real-world scenarios. Many existing evaluation tasks for GenAI do not adequately reflect the complexity and variability of real-world use cases. This misalignment between test cases and actual applications leads to models being evaluated on criteria that may not be relevant when deployed in real-world scenarios. As a result, performance on these tasks may not accurately predict a model’s usefulness in practical applications. In the following table we provide one example each from MMLU and Alpaca Eval as typical discrepancies between benchmark evaluation tasks & equivalent real-world use-cases:
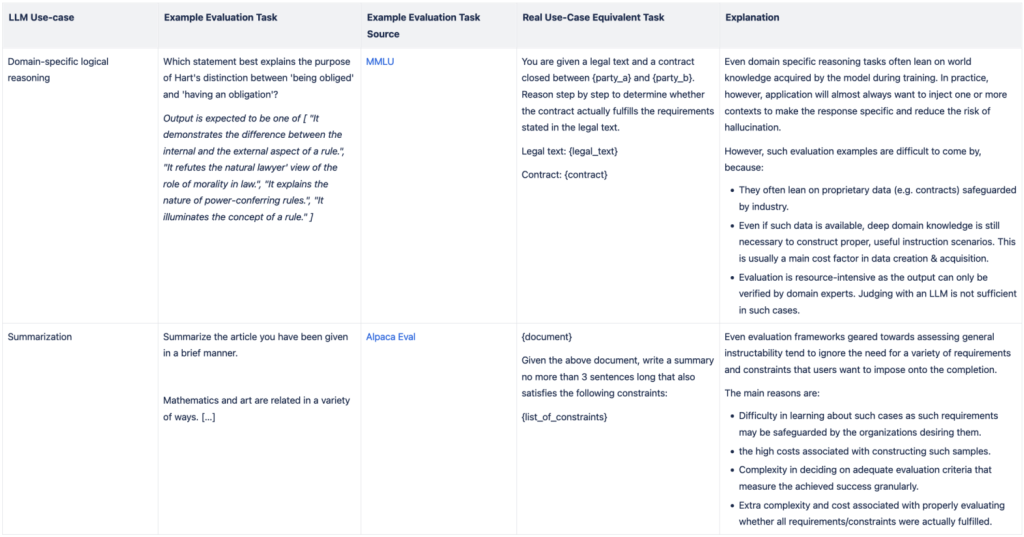
Even when tasks are specifically defined, the criteria for “good model behavior” are context-dependent and often unclear. In GenAI, what constitutes a “good” or “correct” output can vary significantly depending on the specific use case or user expectations. This context sensitivity makes establishing a universally accepted standard for model performance challenging. Consequently, selecting an appropriate dataset for evaluation becomes a critical task, as it must accurately represent the context and goals of the intended application. Furthermore, ensuring the quality of the dataset becomes even more crucial, as any shortcomings in the dataset – such as biases, lack of diversity, misalignment with the intended use case, errors, or samples that make no sense without further context – can lead to misleading evaluation results and ultimately limit the model’s performance in real-world scenarios.
The above particularly applies to benchmarking of pre-trained models; pre-training benchmarks are supposed to measure a model’s ability to learn patterns from vast data. Still, they do not reflect how well the model will perform after fine-tuning specific tasks, and provide unreliable indicators of fine-tuned model performance. Fine-tuning adapts the model to particular use cases required in real-world scenarios, and its success depends heavily on the task- and domain-specific data and objectives.
Pharia-1-7B-control and Pharia-1-7B-control-aligned have been evaluated against similarly sized weight-available multilingual models in several languages, namely Mistral’s Mistral-7B-Instruct-v0.3 and Meta’s llama-3.1-8b-instruct. The results of these evaluations are provided in the model card.