T-Free: Hierarchical Autoregressive Transformers for Language Fairness and Sovereignty

A game-changer for low-resource languages and out-of-distribution fine-tuning
At Aleph Alpha Research, our goal is to build robust and performant language models, which can be easily and efficiently adapted to many different languages, domains and use cases. One aspect hindering such adaptability is the use of tokenizers with rigid, pre-fitted vocabularies. This is why we are working on vocabulary-free language models. This research direction is summarised under the name “T-Free” which was the first peer reviewed paper we introduced at EMNLP 2024 about a year ago.
In this blog post, we want to take a closer look at a tokenizer-free approach, which we proposed in a recent paper and termed Hierarchical Autoregressive Transformers (HAT). In particular, we want to showcase how such a model an be pre-trained in English and efficiently adapted to learn a new, previously unseen language.
Our HAT model achieves comparable evaluation scores to a tokenizer-based model in English pre-training and Finnish continued pre-training, while being 18% more efficient in English and 200% more efficient in Finnish during inference.
Subword Tokenizers and Their Problems
In computational language modelling, tokenization refers to the process of splitting a piece of text into units to be processed by a model. Two fundamental approaches are character-level [Footnote: Characters can refer to different base alphabets. A common choice, which we adopt below, is to use raw UTF-8 bytes.] and word-level tokenization. While character-level tokenization uses the “atomic” units of text and enjoys a small vocabulary size, it leads to long sequences with high computational and memory cost. Conversely, word-level tokenization leads to short sequences but suffers from extremely large vocabulary sizes and the inability to process out-of-vocabulary words.
State-of-the-art models use so-called subword tokenizers, which have emerged as a compromise between these two extremes. Common subword tokenizers such as Byte Pair Encoding (BPE) are fitted on a reference corpus of text, building a subword vocabulary that optimally compresses that text. A fitted subword tokenizer is essentially a huge vocabulary file, against which a piece of input text is matched to produce a sequence of token IDs. To feed this sequence into a model, each token is embedded using a large embedding look-up table. This process is illustrated in Figure 1.
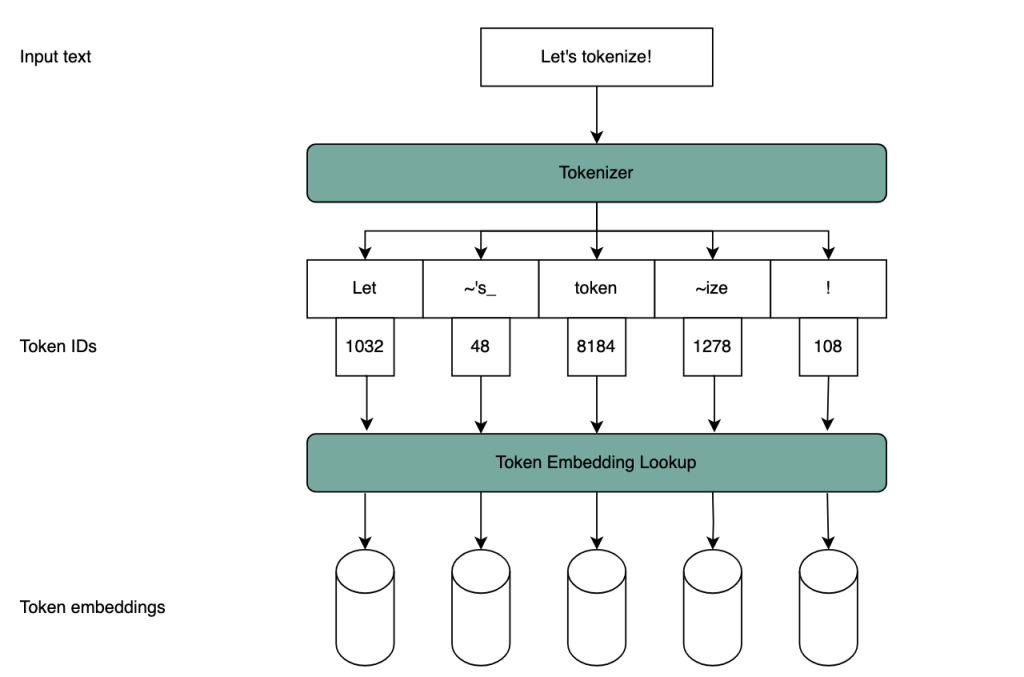
Figure 1: Schematic of tokenizer-based model inputs. The tokenizer segments the text by matching against its fixed vocabulary. Each token has a unique ID, which is used to query an embedding lookup table.
However, subword tokenizers come with several downsides. First, contemporary models routinely use vocabulary sizes in the hundreds of thousands. Since a model’s embedding matrix and output head scale with vocabulary size, models become extremely large. For instance, for the 8B model of the Llama-3 family with a vocabulary size of 128k, these matrices account for roughly 13% of the model’s total parameter footprint. Secondly, spelling mistakes or variations can lead to drastically different token sequences for semantically close inputs and thereby degrade model performance.
Probably the most important downside is that a tokenizer is fitted in a separate step and not included in the end-to-end learning process of the model. This may become problematic when a pre-trained model is applied to or fine-tuned on text from different domains or languages to which the tokenizer is not attuned. E.g., when applying a tokenizer fitted on English data to a new language, it will struggle to represent text efficiently and in semantically meaningful units. One manifestation of that is the tokenizer’s compression rate, i.e., the average number of text bytes it groups into a single token. Figure 1 depicts this phenomenon using the example of English and German.
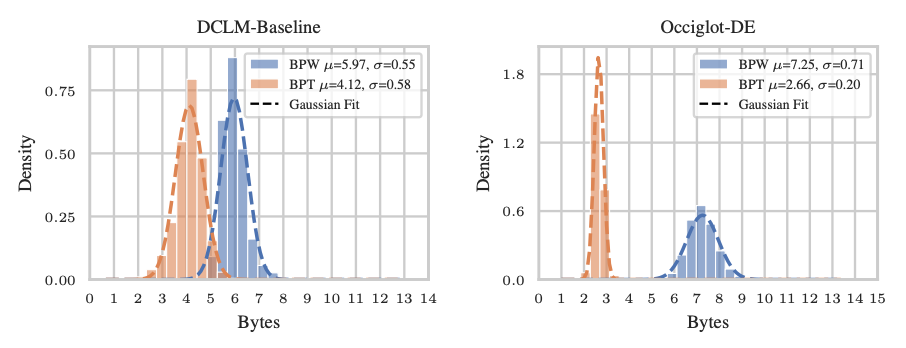
Figure 2: Bytes per word (BPW) and bytes per token (BPT) on the English DCLM-Baseline dataset and the German Occiglot-DE dataset. While the compression rate of the tokenizer drops drastically, the average number of bytes per word even increases
Hierarchical Autoregressive Transformers
To address these shortcomings, Aleph Alpha Research is working on models that do not rely on separately-fitted tokenizers. The approach we are presenting here has been termed Hierarchical Autoregressive Transformer (HAT) and has been presented in a recent paper.
Note: Tokenizer-free architectures are an active research topic at Aleph Alpha. For the experiments presented in this blog post, we use an improved variant of the architecture proposed in the paper above.
The hierarchical autoregressive transformer architecture combines byte-level and word-level processing. We first split the text into words using a simple split rule; we rely on the Unicode standard definition of word. The bytes within each word are processed by a small encoder module, which maps them to a word embedding. The resulting sequence of word embeddings is then processed by a larger backbone model. This process is illustrated in Figure 3.
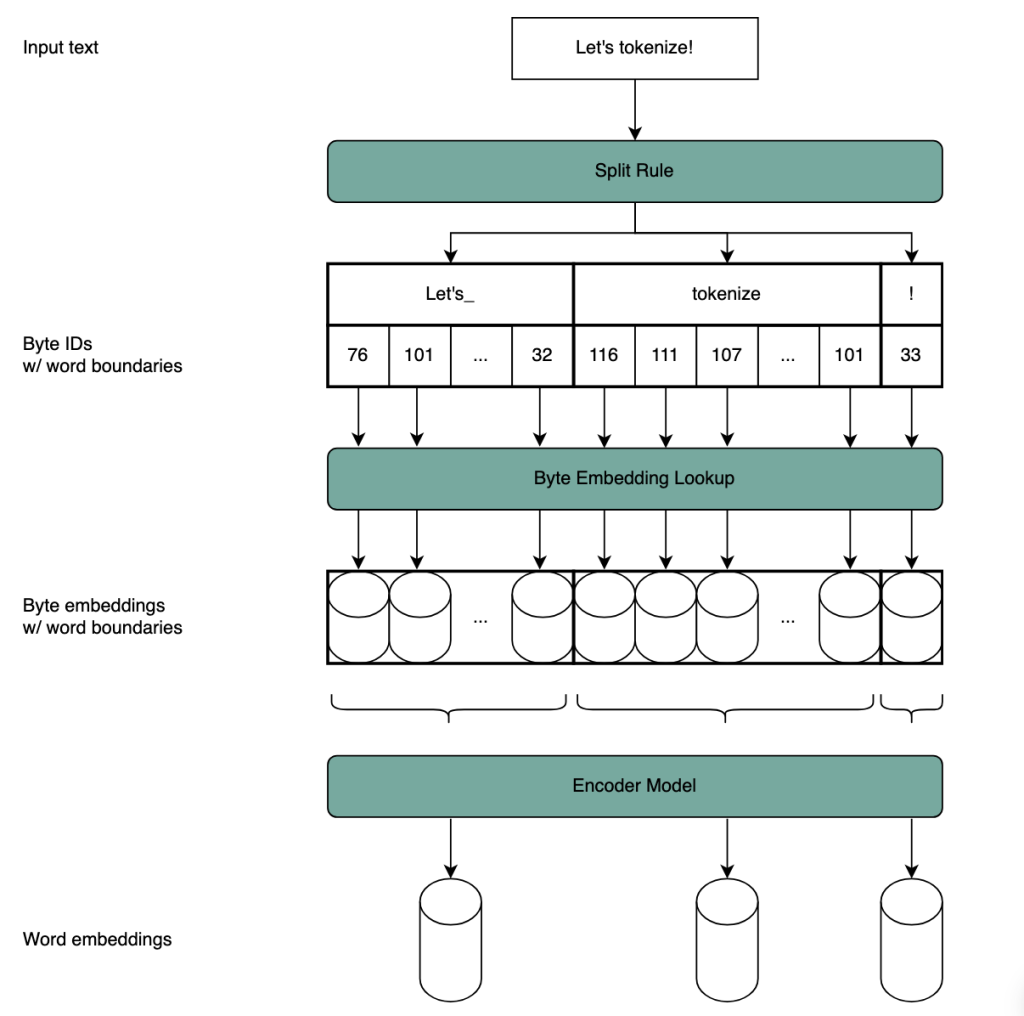
Figure 3: Our hierarchical autoregressive transformer does not rely on a (sub)-word vocabulary. Instead, the text is segmented into words based on a simple splitting rule. Every byte is embedded separately, then the sequence of bytes within each word is passed through a small encoder model, to produce a word embedding.
The outputs of the backbone are treated as abstract “predictive” word embeddings and are decoded back to characters by another small character-level decoder module. The character-level modules are very small, having fewer parameters than the token-level embedding and output head which they replace. Encoder, backbone and decoder are transformer models and the entire system can be trained end-to-end, without the need for a fixed, trained tokenizer.
The model operates on raw UTF-8 bytes as its base alphabet, with a tiny vocabulary size of only 256. HAT can ingest and output any word over that base alphabet.
Pre-training
For this demo, we pre-trained a 7 billion parameter hierarchical transformer model on the English DCLM-baseline dataset. The backbone of the architecture is a standard decoder-only Transformer largely following the Llama-3 design. It has 32 layers, 32 query heads, and 8 key-value heads.
We trained this model on roughly 1.9 trillion words of DCLM data, corresponding to approximately 2.3 trillion tokens using a conventional tokenizer. The context window is 3072 words, the equivalent of roughly 3720 tokens. The training recipe follows established standards, using the AdamW optimizer with a linear warm-up followed by a cosine decay schedule.
Note that this model is substantially cheaper to train than a 7B-parameter model using a conventional subword tokenizer. The backbone of our hierarchical architecture, which accounts for most of the compute, operates on the word level, which is a coarser unit than subword tokens. E.g., while a typical tokenizer may process around 4 bytes per token, our word splitting rule produces an average of more than 5 bytes per word on English text. That means, while our model has seen the equivalent of 2.3T tokens of data, it has only incurred the cost of training a tokenizer-based model of similar size on 1.9T tokens.
The resulting model scores favorably on standard pre-training evaluation tasks, see Table 1. E.g., it achieves a score of 59.4% on the MMLU benchmark. For reference, we display scores of the Apple-DCLM-7B model, which is a comparable open-source model. It has been trained on 2.5T tokens (thereby consuming roughly 30% more compute than our model) on a combination of DCLM-Baseline as well as Math and code datasets (which we did not use). We also report scores for Llama-3.1-8B as well as Meta’s Byte Latent Transformer (BLT), a recent proposal for a byte-level architecture. Our model overall performs at a comparable level.

The table also lists the compression rate of the models, where HAT achieves 5.28 bytes/word compared to 4.35 bytes/word for the Apple-DCLM model. Hence, during deployment the HAT model would save roughly 18% in computational cost!
Scores taken from Meta Paper Byte Latent Transformer: Patches Scale Better Than Tokens
Let’s Learn Finnish!
To showcase the finetunability of our tokenizer-free architecture, we are going to teach our model Finnish! We chose Finnish as an example of a relatively low-resource language that is substantially different from English. As discussed above, such a language acquisition is a substantial challenge for tokenizer-based models, due to the static nature of the tokenizer’s vocabulary.
For this language acquisition phase, we proceed in two stages: continued pre-training and instruction finetuning.
Continued Pre-training
First, we perform a continued pre-training (CPT) on a 2:1 mix of the Finnish portion of the FineWeb2 dataset and (English) DCLM-baseline data. The Finnish data totals 18B words and we perform two passes. The training budget for this phase is only 54B words, which is less than 3% of the pre-training budget. Results on a set of Finnish pre-training evals are depicted in Table 2. In addition to Llama-3.1-8B and Apple-DCLM-7B, we also compare to Viking-7B, a similarly-sized open-source model, which has been trained multilingually from scratch on English, Finnish and other Nordic languages.
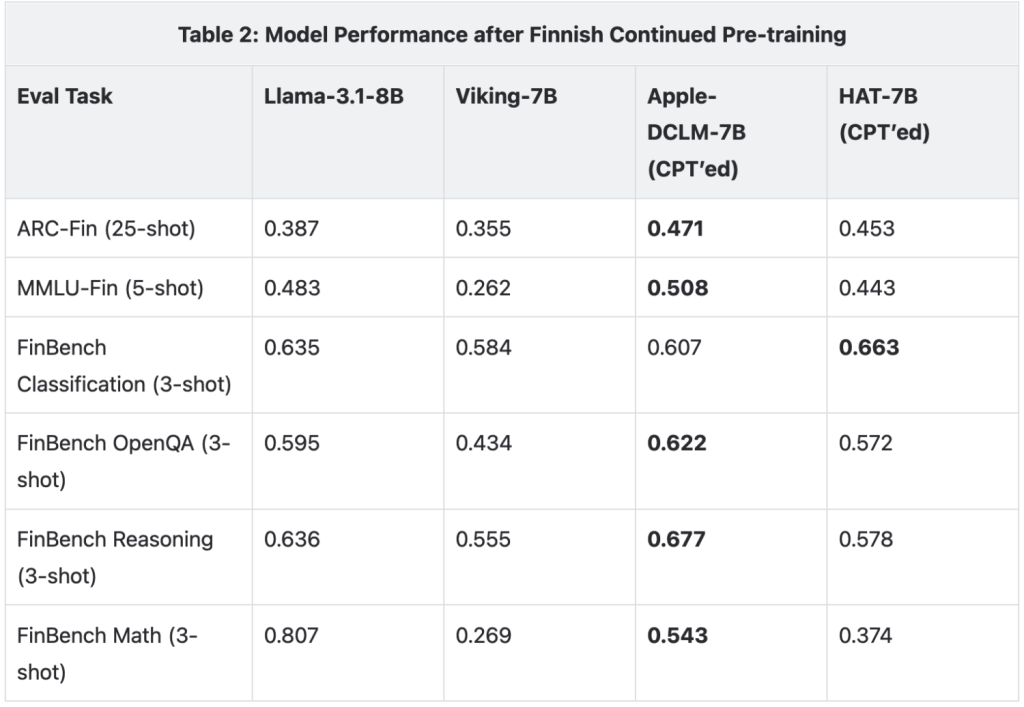
Overall, both the Apple-DCLM model as well as our HAT model successfully acquire Finnish language capabilities according to these benchmarks. They both outperform Viking-7B, which has been trained multilingually from scratch. HAT underperforms in Math and partially also in reasoning tasks, which we attribute to the lack of Math and code in our pre-training data.
Instruction Finetuning
In the second phase, we finetune the model on a combination of English and Finnish instruction finetuning data. Results on English and Finnish evaluation tasks are depicted in Table 3. Again, we apply the identical procedure to the Apple-DCLM-7B model as a comparison point. We are not aware of comparable instruction-tuned Finnish open-source models. On these generative evaluation tasks, the HAT model consistently outperforms the tokenizer-based Apple-DCLM model.
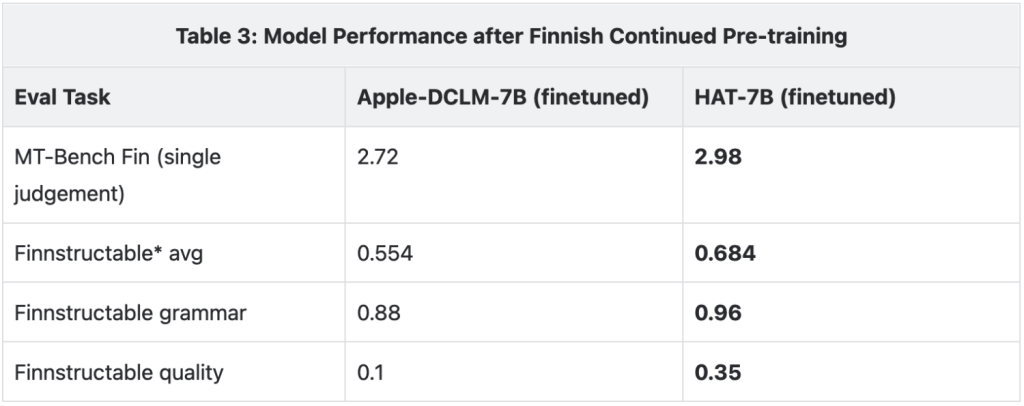
Finnstructable is an internal benchmark for instruction following in Finnish with instructions generated and judged by GPT-4.
Inference Efficiency
Deploying the Apple-DCLM model in a Finnish use case would be massively inefficient. The tokenizer’s compression rate drops from 4.35 bytes per token in English to 2.68 bytes per token in Finnish. In contrast, the compression rate of our word-based HAT model increases to 7.96 bytes per word on Finnish due to longer average word lengths. That means that, on average, for a given Finnish document the HAT model processes a sequence that is almost 3x shorter compared to the tokenizer-based model. This results in a 3x reduction in computational cost and activation memory consumption. Conversely, when comparing models with identical context sizes in tokens and words, respectively, the word-based model would cover 3x more effective context (as measured in bytes).

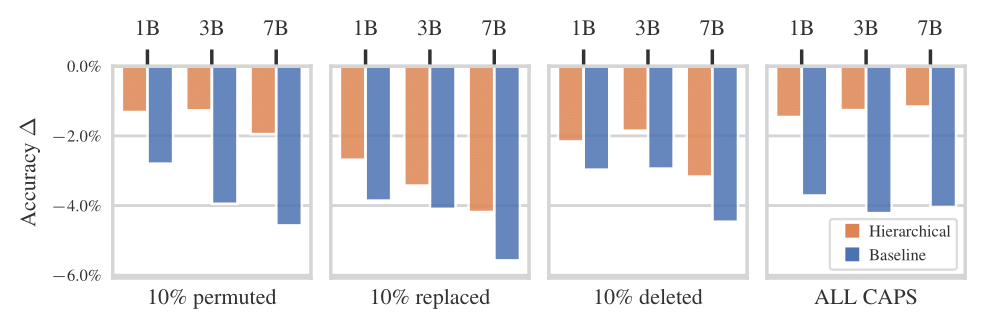
Robustness
In addition to the improved inference efficiency, as reported in our paper, the HAT model is significantly more robust to perturbations to the input (incomplete words, typos) than tokenizer-based models. We measure this by applying perturbations to the prompts of selected evaluation tasks and measure the change in average accuracy compared to each model’s performance on the original prompt. The perturbations include permuting, randomizing, or deleting 10% of the characters per word, as well as changing the prompt to all caps.
Conclusion
We have presented the Hierarchical Autoregressive Transformer (HAT) architecture, a tokenizer-free approach to language modelling. We have showcased how this architecture, pre-trained in English, can be effectively fine-tuned to acquire a previously-unseen language while maintaining efficiency through high compression rates. We believe that tokenizer-free, end-to-end trained approaches, like the one presented here, are a promising avenue towards more robust and adaptable language models.