Luminous Performance Benchmarks
The research compares Luminous to the models from GPT-3 and ChatGPT developer OpenAI, among others.
We present our benchmark results for Aleph Alpha’s Large Language Models: luminous-base,luminous-extended, and luminous-supreme available on the Completion Playground and API client. Luminous models follow a decoder-only autoregressive architecture with use of rotary positional embeddings. Our models are trained on a curated multilingual corpus containing sources in English, German, French, Italian, and Spanish on ~400B to ~588B language tokens for the smallest and largest models, respectively.
Download the PDF here
Table of contents
- Evaluation framework
- Model performance on core tasks
- Model performance on an extended set of tasks
- Few-shot prompting
- Supplementary materials
1. Evaluation framework
While the Aleph Alpha Playground and API also provide Question-Answering, Embedding, and Summarization endpoints along with multimodal capabilities, here we focus on evaluating the Large Language Model’s text-based completions. For that, EleutherAI’s Evaluation Harness (lm-eval) package is used.
Completion correctness is measured with the soft accuracy metric (acc) when possible; here the log-likelihood probability is measured for each of the possible multiple-choice completion options, and the one with the highest probability is selected to determine the accuracy of the prediction compared to the ground-truth option. For generative tasks, an exact match accuracy metric (exact) is computed by checking if model completion exactly matches the expected output. The tasks evaluated with the exact metric are the following: squad2, triviaqs, webqs.
Note that when comparing to other models, we only do so for results produced with this common benchmarking setup, as evaluation results can deviate from published ones for some tasks due to prompt formulation, checkpoint formats, data splits used, etc.
2. Model performance on core tasks
Firstly, we show results for our current best model (luminous-supreme with 70B parameters) on a set of core 16 tasks and compared to BigScience BLOOM (176B) and Meta AI OPT (175B) benchmark results produced with lm-eval (see link here). OpenAI davinci (175B) is evaluated by ourselves using the same setup as for our Aleph Alpha Luminous models. We note competitive accuracy results when averaged across all 16 tasks, especially given our smaller architecture in comparison to the other models.
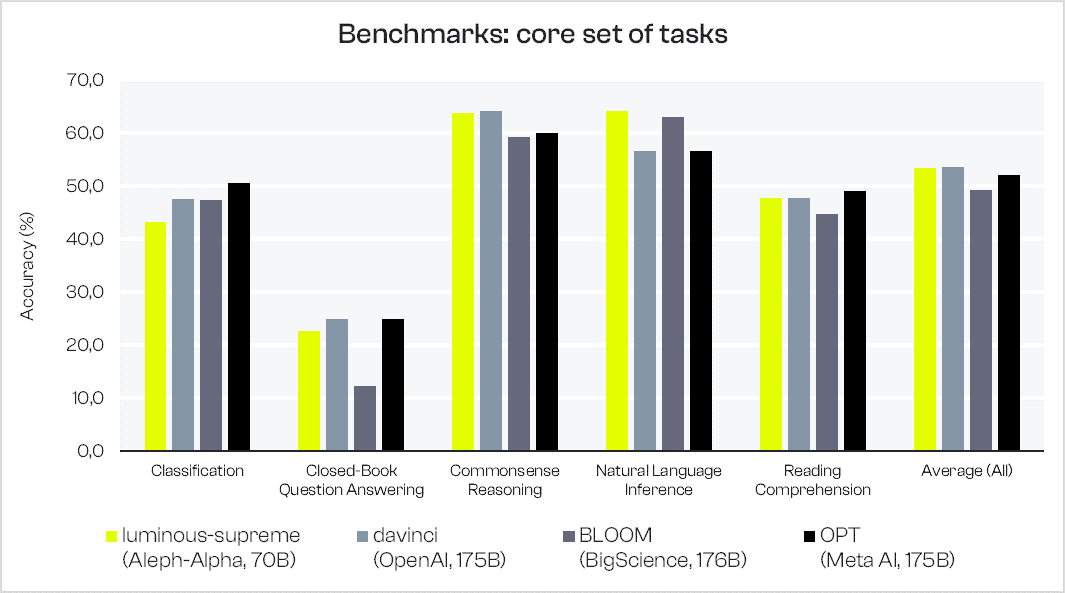
The benchmarked tasks cover five groups:
- Classification (wic),
- Closed-Book Question Answering (triviaqa, webqs),
- Common-sense Reasoning (arc_challenge, arc_easy, copa, hellaswag, openbookqa, piqa, winogrande, wsc),
- Natural Language Inference (rte),
- Reading Comprehension (boolq, lambada, multirc, race).
Example prompts for the evaluated tasks, and detailed information on performance are provided in the supplementary material section in chapter 6.
3. Model performance on an extended set of tasks
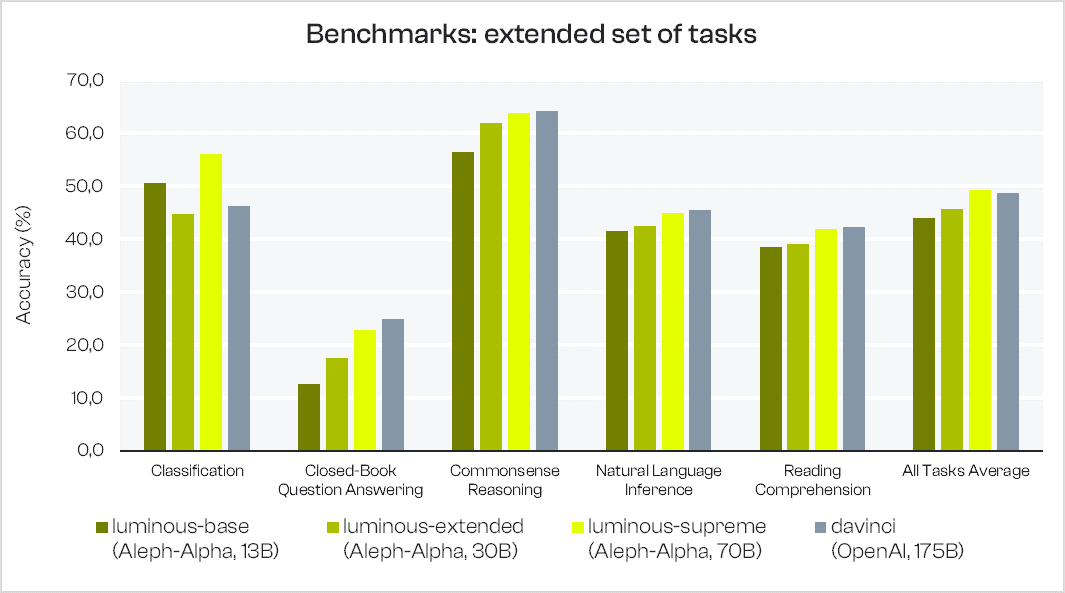
We also release additional benchmark results with 12 additional tasks, extending the evaluation set to a total of 28 tasks. We add to our comparison our two alternative smaller models, luminous-baseand luminous-extended with 13B and 30B parameters, respectively.
The additional tasks are:
- Classification (mrpc, sst
), - Natural Language Inference (anli_r1, anli_r2, anli_r3, cb, mnli, mnli_mismatched, qnli, wnli),
- Reading Comprehension (squad2, race_mid).
We can see from the graph below that performance improvements are seen for all task types evaluated in the results, as model size increases. This trend is in line with empirical scaling law observations as seen in prior work. We expect further improvements with our scaled-up luminous-world model (coming soon).
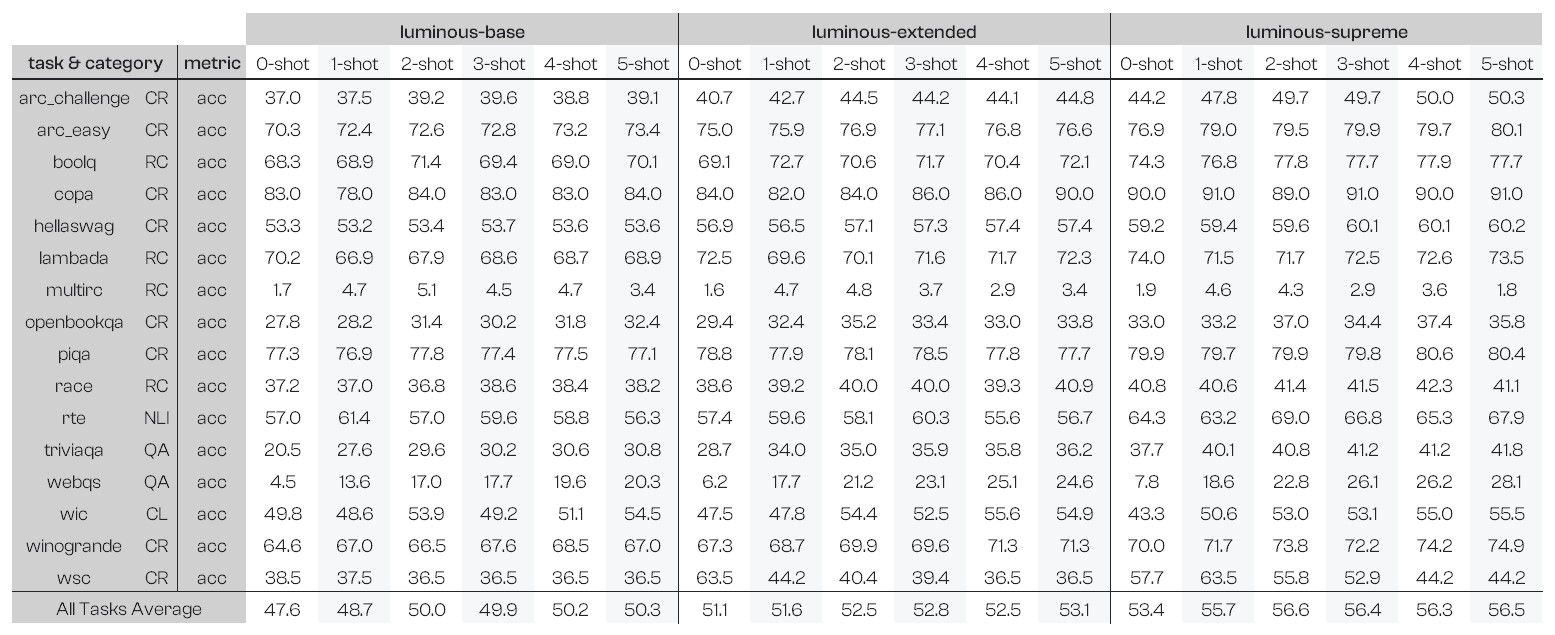
4. Few-shot prompting
The table below provides the benchmarking results with few-shot prompting for the 16 core tasks listed above. Zero to five examples (separated by two new lines in lm-eval) are concatenated in the prompt as input for the completion.
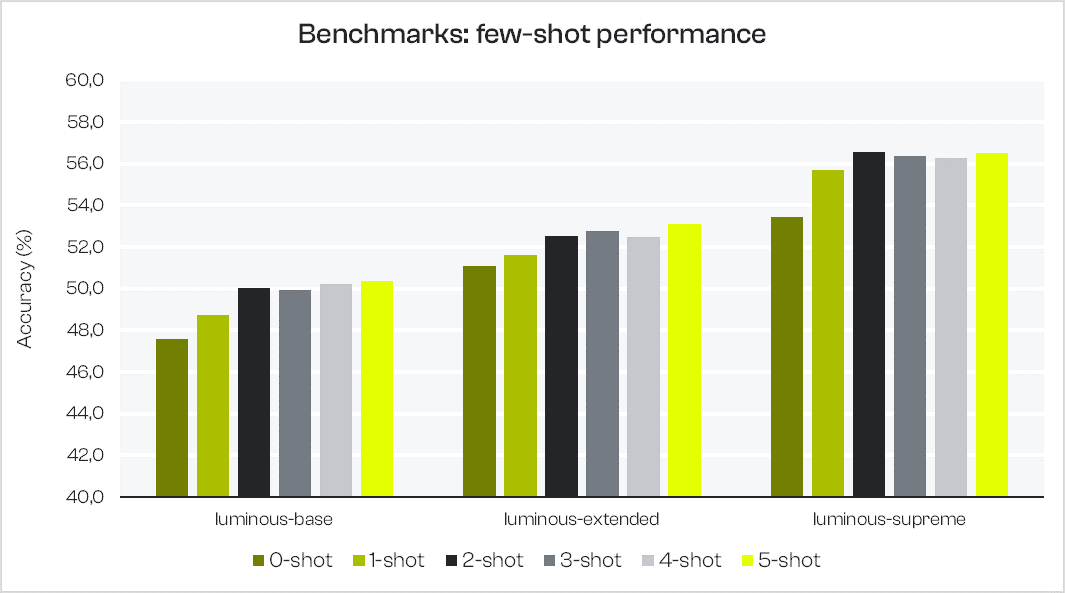
Few-shot prompting helps to boost performance in completion tasks for our Luminous models (6% on luminous-supreme between 0-shot and 5-shots). Depending on the end-user needs, this also allows for faster and cheaper inference using smaller models without compromising on accuracy: for example, providing 5-shot examples on luminous-extended can enable performance that is almost as good as 0-shot luminous-supreme on average.
While the table compares likelihood-based accuracies, we observed an even larger impact on exact-match completion tasks, where the few-shot examples help boost the performance by providing the model with examples of what type of answers are expected.
In addition, we did an ablation study where luminous-supreme was evaluated with 1-shot examples again but with “\n###\n” as a separator (which is usually used in our examples in the Playground) rather than the lm-eval standard new lines “\n\n”. Using both few-shot separators gives very close average accuracy scores (55.3% with “\n###\n” and 55.7% with “\n\n”) and scores for individual tasks are within 5% of each other.
5. Supplementary Materials
Benchmark results on the core set of tasks

Benchmark results on the extended set of tasks
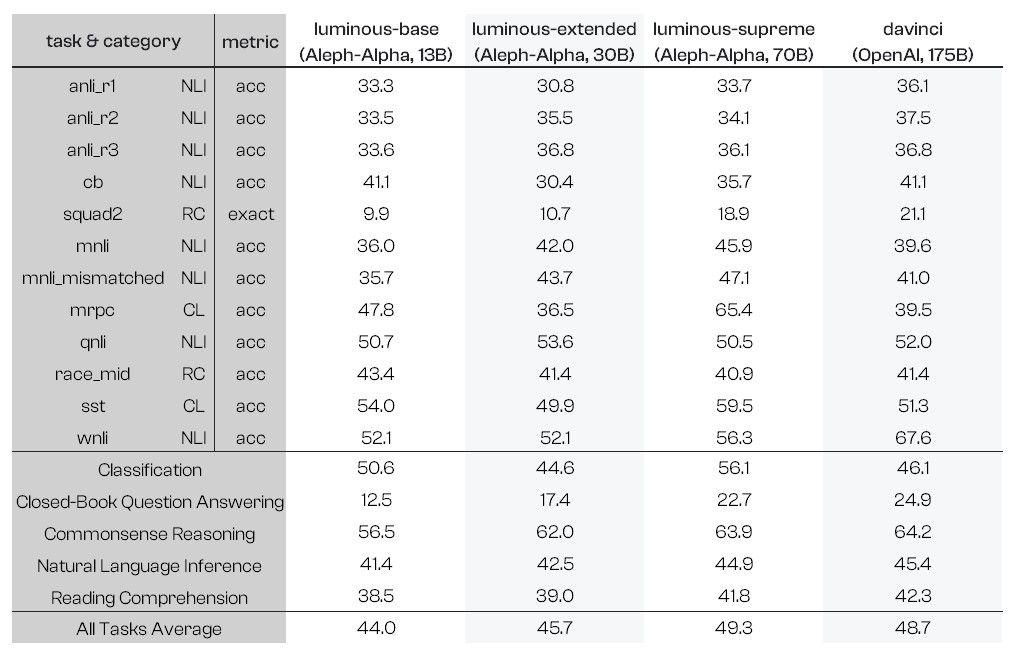
Benchmark with few-shot prompts
Example prompts for different task categories
# Classification example:
# - wic with Likelihood-based accuracy metric
prompt = """
Sentence 1: Let's break for lunch.
Sentence 2: A man broken by the terrible experience of near-death.
Question: Is the word 'break' used in the same way in the two sentences above?
Answer:"""
expected_completion = " no" # evaluate against the following completions: [yes/no]
# Closed-Book Question Answering example:
# - triviaqa with Exact Match accuracy metric checked against a list of correct answers
prompt = """
Question: What type of leaves does a koala feed on?
Answer:"""
expected_completion = " Eucalypti" # the following are also correct answers: [Eucalyptus/Gum trees/Gum-tree/Ευκάλυπτος]
# Commonsense Reasoning example:
# - copa with Likelihood-based accuracy metric
prompt_1 = "The man perceived that the woman looked different because the woman got her hair cut."
prompt_2 = "The man perceived that the woman looked different because the woman wore a bracelet." # correct answer
# Natural Language Inference example:
# - rte with Likelihood-based accuracy metric
prompt = """
The number of Danes opposed to swapping the krone for the euro has increased slightly to 35.3 percent, up from 34.6 percent in April, according to a poll published on Thursday by Danske Bank.
Question: The introduction of the euro has been opposed. True or False?
Answer:"""
expected_completion = " True" # evaluate against the following completions: [True/False]
# Reading Comprehension example:
# - xquad_en with Exact Match accuracy metric
prompt = """
Between Bingen and Bonn, the Middle Rhine flows through the Rhine Gorge, a formation which was created by erosion. The rate of erosion equaled the uplift in the region, such that the river was left at about its original level while the surrounding lands raised. The gorge is quite deep and is the stretch of the river which is known for its many castles and vineyards. It is a UNESCO World Heritage Site (2002) and known as "the Romantic Rhine", with more than 40 castles and fortresses from the Middle Ages and many quaint and lovely country villages.
Question: What flows between Bingen and Bonn?
Answer:"""
expected_completion = "Middle Rhine"
Example prompt in few-shot study
# Few-shot prompting example
# - boolq dataset with 2-shot prompt
prompt="""
Central government -- A central government is the government of a nation-state and is a characteristic of a unitary state. This is the same thing as a federal government which may have distinct powers at various levels authorized or delegated to it by its member states, though the adjective 'central' is sometimes used to describe it. The structure of central governments varies. Many countries have created autonomous regions by delegating powers from the central government to governments at a subnational level, such as a regional, state or local level. Based on a broad definition of a basic political system, there are two or more levels of government that exist within an established territory and govern through common institutions with overlapping or shared powers as prescribed by a constitution or other law.
Question: is national and federal government the same thing?
Answer: yes
White House -- The White House is the official residence and workplace of the President of the United States. It is located at 1600 Pennsylvania Avenue NW in Washington, D.C., and has been the residence of every U.S. president since John Adams in 1800. The term White House is often used as a metonym for the president and his advisers, as in ``The White House announced that...''.
Question: is the white house in the state of washington?
Answer: no
NCIS: New Orleans (season 4) -- The fourth season of NCIS: New Orleans premiered on September 26, 2017 on CBS. The series continues to air following Bull, Tuesday at 10:00 p.m. (ET) and contained 24 episodes. The season concluded on May 15, 2018.
Question: is ncis new orleans over for the season?
Answer:"""