
Aleph Alpha Blog
Beeindruckt von der Skala dieser Tensoren – eine sanfte Einführung in Unit-Scaled Maximal Update Parametrization
Heute freuen wir uns, die Aufnahme von Unit-Scaled Maximal Update Parametrization (u-μP) in Scaling anzukündigen – unsere offizielle Codebasis für Large-Scale-Training. Gemeinsam mit Graphcore haben wir kürzlich u-μP als neues Paradigma entwickelt, um neuronale Netze in Breite und Tiefe zu parametrisieren. Unser Ansatz kombiniert μP von G. Yang et al. mit Unit Scaling, einem von Graphcore eingeführten Konzept.
Die wesentlichen Vorteile von u-μP sind:
- Ein sinnvolles Set an Hyperparametern, die über Modellgrößen hinweg übertragbar und leicht zu sweepen sind.
- Stabile numerische Tensor-Scales während des Trainings – dadurch können die meisten Matmuls in linearen Layern nativ in FP8 ausgeführt werden, ganz ohne Per-Tensor-Scaling-Strategie.
Wenn du mehr Details zu u-μP erfahren willst, schau dir unser Paper an.
Wir geben zunächst einen Überblick über die Theorie hinter u-μP und erklären die zentralen Ideen. Danach folgen praktische Tipps und Insights für alle, die u-μP für LLM-Training nutzen wollen.
Primer: Das asymptotische Verhalten eines linearen Layers
Um die wirklich grundlegenden Ideen und Konzepte hinter u-μP zu verstehen, fangen wir bei den Fundamenten an.
Die Dokumentation von PyTorchs nn.Linear – dem Modul im Herzen der meisten modernen
Neuronale-Netz-Architekturen – besagt, dass Gewicht und Bias aus der Gleichverteilung auf (−1/fan_in−−−−−√,1/fan_in−−−−−√)(−1/fan_in,1/fan_in)
initialisiert werden, wobei fan_infan_in die Anzahl Eingabe-Features des Layers ist. Aus Notations-Gründen
kürzen wir das mit dd ab. Es gibt einen bestimmten Grund, warum 1/d−−√1/d hier auftaucht.
Betrachten wir einen frisch initialisierten linearen Layer FF mit einem Gewicht WW (ohne Bias), und nehmen wir an, dass die Einträge von WW i.i.d. mit Mittelwert 0 und Varianz σ2WσW2 sind. Sei xx ein zufälliger Input mit Mittelwert 0 und Varianz σxσx, der unabhängig von WW gezogen wird. Bezeichnen wir yy als Output des Layers, also y=F(x)y=F(x). Per Annahme sind die Koordinaten-Einträge von xx in etwa von der Größenordnung σxσx. Aber was ist mit den Einträgen von yy? Per Definition gilt
F(x)i=∑dj=1WijxjF(x)i=∑j=1dWijxj
Im modernen Deep Learning kann die Hidden-Dimension d sehr groß werden. Da die Zufallsvariablen {Wijxj}j{Wijxj}j alle unabhängig sind und Mittelwert 0 sowie Varianz σ2Wσ2xσW2σx2 haben, können wir den Zentralen Grenzwertsatz (CLT) anwenden und folgern
F(x)i∼N(0,σ2Wσ2xd),d→∞F(x)i∼N(0,σW2σx2d),d→∞
Da wir nicht wollen, dass die Hidden-Aktivierungen zu stark schrumpfen oder wachsen, wenn wir die Netzgröße ändern, ist eine gute Wahl für σWσW eine, die ungefähr proportional zu 1/d−−√1/d ist – denn dann hat yy eine Varianz, die mit der von xx vergleichbar und unabhängig von dd ist. Eine weitere interessante Beobachtung: Im Grenzfall wird yy Gauß'sch – unabhängig davon, aus welchen Verteilungen WW und xx gezogen werden – solange alle Größen i.i.d. sind und endliche Varianz haben. Das liefert einen Hinweis, warum sich breite neuronale Netze im ersten Forward-Pass wie Gauß-Prozesse verhalten.
μP: Von linearen Layern zu Tensor Programs
Während die Analyse für einen einzelnen Forward-Pass eines linearen Layers relativ einfach ist, ist das korrekte Skalierungsverhalten für ein ganzes neuronales Netz ein ganz anderes Tier – besonders wenn man an einer Analyse über den ersten Forward- und Backward-Pass hinaus interessiert ist.
In einem tiefen neuronalen Netz ist a priori unklar, welche Tensoren während des Trainings über den CLT interagieren und welche über das Gesetz der großen Zahlen (LLN). Der lineare Layer von oben ist ein Beispiel, in dem WW und xx im Matrix-Vektor-Produkt über den CLT interagieren, weil WW und xx unabhängig sind. Als Beispiel für eine LLN-Interaktion betrachte die Matrix V=W⋅WTV=W⋅WT für irgendeine Matrix WW mit zufälligen i.i.d. Einträgen. Die Einträge von VV sind gegeben durch
Vij=∑dk=1WikWjkVij=∑k=1dWikWjk
Abseits der Diagonale hat die Zufallsvariable WikWjkWikWjk Mittelwert null, daher skaliert VV wie d−−√d (CLT-Skalierung). Auf der Diagonale summieren wir W2ikWik2, das einen Mittelwert von σ2WσW2 hat – diese Einträge skalieren daher per LLN wie dd.
Beim ersten Forward-Pass eines neuronalen Netzes interagieren so gut wie alle Tensoren über den CLT. Nach einem Trainings-Step werden die Gewichte aber korreliert, und die Situation ist weniger eindeutig – besonders mit nichtlinearen Operationen. Das Beispiel W⋅WTW⋅WT oben ist einfach, aber strukturell tritt diese Art korreliertes Produkt tatsächlich in späteren Forward-Pässen auf, wenn sich Gewichte durch gradientenbasierte Updates ändern.
In einem großen Durchbruch haben G. Yang et al. die Typen von Tensor-Interaktionen während des Trainings für sehr allgemeine Netze, sogenannte Tensor Programs, vollständig analysiert. Aus dieser Analyse haben sie hergeleitet, dass es eine eindeutige (bis auf Symmetrie) Möglichkeit gibt, Multiplikatoren, Anfangsvarianzen und Learning Rates der Netzgewichte über Exponenten von dd zu parametrisieren – so, dass im Infinite-Width-Limit maximales Feature-Learning garantiert ist. Diese Parametrisierung heißt Maximal Update Parametrization (μP).
Vereinfacht: Die definierenden Eigenschaften von μP sind, dass Neuron-Aktivierungen während des Trainings von Größenordnung eins bleiben und dass alle Features (Hidden-States des Netzes für einen gegebenen Input) sich nicht-trivial entwickeln. Die Ergebnisse dieser Arbeit sind bedeutsam, weil die Klasse der Tensor Programs, für die die Haupt-Theoreme gelten, eine breite Palette neuronaler Architekturen umfasst (z.B. MLP, ResNet, Transformer, RNN). Außerdem wurde in Tensor Programs V gezeigt, dass μP Hyperparameter-Transfer von kleinen zu großen Modellen ermöglicht – eine sehr wertvolle Eigenschaft, die kosteneffiziente Hyperparameter-Sweeps für LLMs erlaubt.
Unit Scaling: Ein Ansatz für stabile Numerik
Während die Hauptmotivation von μP darin besteht, Dynamiken neuronaler Netze mit schönen mathematischen Eigenschaften zu etablieren, fokussiert es nicht zwingend auf numerische Treue (mehr dazu im nächsten Abschnitt). Mit dem Ziel, stabiles FP8-Training für neuronale Netze zu ermöglichen, haben Blake et al. von Graphcore das Konzept des Unit Scaling in diesem Paper eingeführt. Unit Scaling bezeichnet die Eigenschaft, dass alle Tensoren in einem neuronalen Netz (Aktivierungen, Gewichte und ihre Gradienten) bei der Initialisierung – also im ersten Forward- und Backward-Pass – Einheitsvarianz haben.
Einträge unit-skalierter Tensoren liegen mit hoher Wahrscheinlichkeit nahe am Zentrum des darstellbaren Bereichs gängiger Floating-Point-Formate. Das erlaubt es, sie in niedrigpräzise Zahlformate wie FP8 zu casten. In der Praxis wird Unit Scaling induktiv erreicht. Wenn wir annehmen, dass der Input eines neuronalen Netzes Einheitsvarianz hat, dann erfüllt das Netz Unit Scaling, sofern jede Zwischenoperation diese Eigenschaft erhält.
Im Beispiel des linearen Layers oben haben wir schon berechnet, dass die Varianz des Outputs y durch d−−√⋅σW⋅σxd⋅σW⋅σx gegeben ist. Um die Einheitsvarianz eines Inputs zu erhalten (σx=1σx=1), gibt es nur die Wahl σW=1/d−−√σW=1/d. Aufmerksame Leser:innen mögen hier protestieren – und das zu Recht. Damit Unit Scaling gilt, müssen alle Tensoren des Netzes Einheitsvarianz haben – das wird durch die Wahl von σWσW gerade verletzt.
Zur Lösung ist die entscheidende Beobachtung, dass wir statt der Initialisierung von WW einfach die lineare Operation selbst modifizieren können. Statt FF, betrachte
Fλ(x)=λ⋅WxFλ(x)=λ⋅Wx
Dann ist diese Operation skalenerhaltend für σW=1σW=1, wenn wir λ=1/d−−√λ=1/d setzen. Dieses einfache Beispiel veranschaulicht bereits einen wichtigen Aspekt von Unit Scaling: Aufgrund der präzisen numerischen Constraint sind Gewichtsmultiplikatoren wie λλ vollständig bestimmt – und nicht mehr ein Hyperparameter des Modells. Wir kommen darauf später zurück.
Mit dem Unit-Scaling-Prinzip im Kopf müssen wir nun sicherstellen, dass jede Operation – linear oder nichtlinear – Varianz erhält. Analytische Ausdrücke für das Skalierungsverhalten aller gängigen Operationen im Deep Learning herzuleiten, kann ziemlich aufwendig werden; für eine tiefere Betrachtung verweisen wir auf das Unit-Scaling-Paper oder diesen Blogpost, der speziell die Scaled-Dot-Product-Operation behandelt.
Es gibt einige weitere Feinheiten, die wir erwähnen wollen. Erstens: Wenn wir die Skala von der initialen Gewichtsvarianz zu einem Operations-Multiplikator verschieben, ändert sich die Analyse für einen einzelnen Forward-Pass nicht – wohl aber die Trainings-Dynamik, weil der Multiplikator auch Gradienten und Gewichts-Updates beeinflusst (das wird durch abc-Symmetrie erfasst, siehe nächster Abschnitt). Eine gegebene Netzarchitektur unit-skaliert zu machen und gleichzeitig ihre Trainings-Dynamik zu erhalten, ist oft möglich, erfordert aber Sorgfalt.
Zweitens haben wir bisher nur den Forward-Pass betrachtet. Im Backward-Pass eines linearen Layers multiplizieren wir den eingehenden Gradienten mit WTWT, um den Gradienten bezüglich des Inputs zu erhalten. Wenn fan_infan_in ungleich fan_outfan_out ist, erhält die Backward-Operation die Varianz nicht. Das lässt sich manchmal mit der sogenannten Cut-Edge-Regel von Unit Scaling lösen, besonders in Residual-Netzwerken aber nicht immer. Eine andere Option ist, zwischen Forward- und Backward-Scales zu interpolieren – als Kompromiss (was weder Forward- noch Backward-Pass perfekt unit-skaliert macht); wir finden jedoch, dass es in der Regel die beste Praxis ist, Unit Scaling im Forward-Pass zu priorisieren.
u-μP: Ein Match made in Heaven
Fassen wir kurz zusammen, was wir bisher gelernt haben.
μP ist eine Methode, die
- darauf abzielt, schöne mathematische Eigenschaften neuronaler Netze sicherzustellen – mit dem Resultat Hyperparameter-Transfer.
- Regeln zur Skalierung von Gewichts-Multiplikator, Init-Varianz und Learning Rate liefert.
- garantiert, dass Aktivierungen bei jedem Trainings-Step von Größenordnung eins bleiben, wenn die Modellbreite steigt.
Ein praktischer Nachteil von μP ist die numerische Stabilität. Tensor Programs V berichtet sogar, dass ihr 7B-μP-Transformer-Modell in FP32 trainiert werden musste – was im Vergleich zu niedrigpräzisen Verfahren sehr kostspielig ist.
Unit Scaling ist eine Methode, die
- darauf abzielt, schöne numerische Eigenschaften neuronaler Netze sicherzustellen – mit dem Resultat Out-of-the-Box-Low-Precision-Training.
- Regeln zur Skalierung von Gewichts-Multiplikator, Init-Varianz (konstant 1) und nichtlinearen Operationen liefert.
- garantiert, dass Tensoren während des ersten Forward- und Backward-Passes Einheitsvarianz haben.
Unit Scaling fokussiert explizit auf Numerik, kann aber nur Garantien zur Initialisierung geben. Es liefert keine weiteren Empfehlungen zu Hyperparametern – insbesondere zu Learning Rates – und adressiert Tensor-Korrelationen während des Trainings nicht. Aufgrund ihrer konzeptuellen Ähnlichkeiten liegt die Frage nahe, ob man beide Ansätze kombinieren kann, um das Beste aus beiden Welten zu bekommen und gleichzeitig ihre blinden Flecken zu mildern. Die Antwort lautet ja!
Wir haben festgestellt, dass es eine eindeutige Version von μP gibt, die Unit Scaling erfüllt – wir nennen sie Unit-Scaled Maximal Update Parametrization (u-μP). Wer mit den Skalierungs-Regeln von μP vertraut ist, könnte annehmen, dass Unit Scaling und μP sich widersprechen: Die Hidden-Weight-Varianz von μP ist üblicherweise 1/d−−√1/d, während Unit Scaling eine Varianz von 1 verlangt. Um das aufzulösen, müssen wir über eine fundamentale Eigenschaft neuronaler Netze sprechen (Lemma J.1 in Tensor Programs V), die wir abc-Symmetrie nennen.
Die abc-Symmetrie besagt, dass die Trainings-Dynamik (mit dem ADAM-Optimizer und ϵ=0ϵ=0) jedes neuronalen Netzes invariant unter folgender Symmetrietransformation ist:
AW←AW/θ,BW←BW⋅θ,CW←CW⋅θ,AW←AW/θ,BW←BW⋅θ,CW←CW⋅θ,
wobei A,B,CA,B,C den Multiplikator, die Init-Std und die Learning Rate bezeichnen und θθ eine beliebige nicht-negative Zahl ist. Diese Aussage lässt sich in wenigen Zeilen mit der Kettenregel beweisen, ist aber das Schlüsselwerkzeug, um μP und Unit Scaling zu vereinen. Aufgrund der abc-Symmetrie gibt es eigentlich kein eindeutiges μP, sondern eine unendliche 1-Parameter-Familie von μPs, die alle äquivalent sind. Man kann frei eine Skalierungs-Regel für eines von A, B oder C wählen, das dann die Exponenten der anderen beiden bestimmt. Im Fall von Unit Scaling verlangen wir BW=1BW=1. Die eindeutige Version von μP, die diese Constraint erfüllt, ist in der folgenden Tabelle dargestellt:
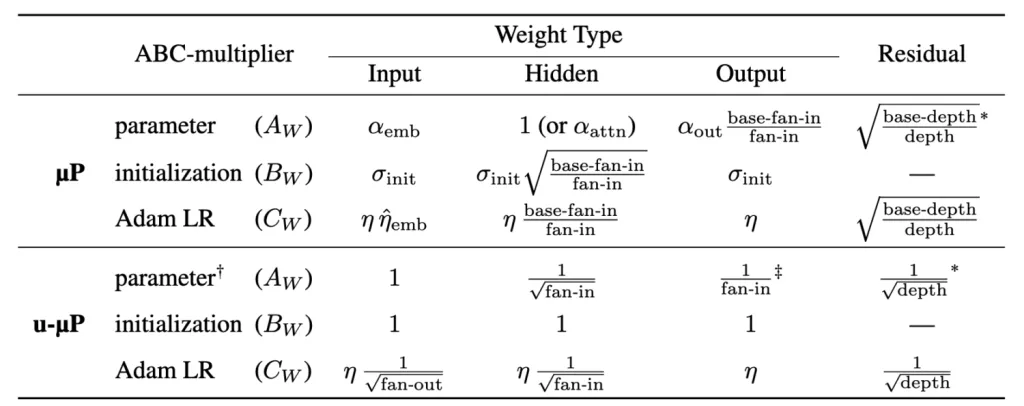
Wer mit μP sehr vertraut ist, wird einwenden, dass unsere Learning-Rate-Skalierungsregel eigentlich nicht μP-konform ist – und das stimmt. Bei unseren Transformer-Experimenten haben wir festgestellt, dass die optimale Learning Rate für die Embedding-Matrix bei steigender Modellbreite tatsächlich deutlich verschoben wird. Empirisch haben wir gefunden, dass diese Verschiebung ungefähr einem inversen Wurzelgesetz folgt:
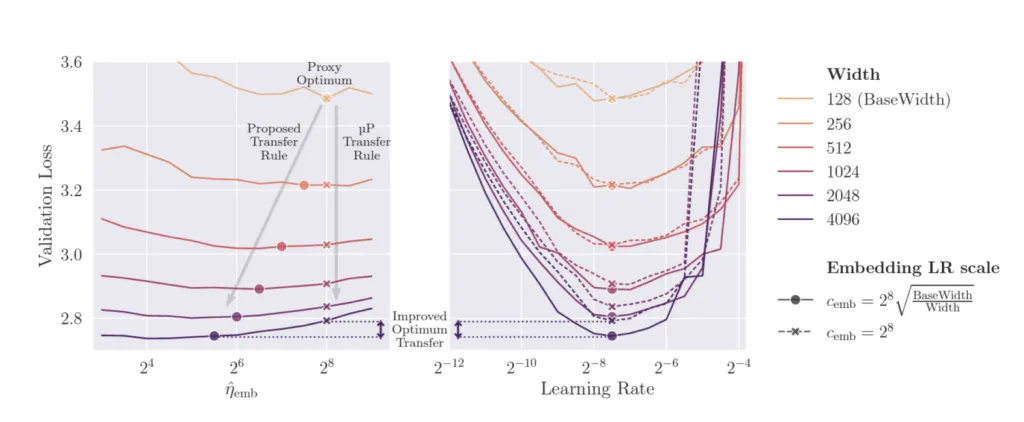
Dieser Befund ist spannend, und wir hoffen, in zukünftiger Arbeit eine theoretische Erklärung dafür zu liefern.
Ein weiterer Punkt ist der 1/d1/d-Multiplikator für das Output-Gewicht. Diese Regel verletzt Unit Scaling tatsächlich, weil die Output-Logits im ersten Forward-Pass mit steigender Breite gegen null tendieren. Damit können wir aus zwei Gründen leben: Erstens wissen wir, dass die Logits nach dem ersten Modell-Update wieder von Größenordnung eins sind. Dieses Verhalten des Output-Layers ist eine der zentralen Erkenntnisse von μP und wird durch einen Wechsel der Tensor-Interaktion (CLT vs. LLN) nach dem ersten Forward-Pass verursacht. Zweitens: Da der Output-Layer die letzte Operation vor der Loss-Berechnung ist, propagiert die schrumpfende Skala nicht auf andere Layer. Unit Scaling hier durch Anwenden eines 1/d−−√1/d-Multiplikators zu erzwingen, würde nach dem ersten Step zu explodierenden Logits führen – das wäre deutlich schlechter, als Unit Scaling für diesen einen Layer zu verletzen.
Im Backward-Pass sieht die Situation hingegen gefährlicher aus, denn dort propagiert die Magnitude linear durch das Netz und unterskaliert jeden Gradienten auf dem Weg. Zum Glück können wir die Backward-Berechnung so anpassen, dass der 1/d−−√1/d-Faktor im Backward-Pass angewendet wird. Auch wenn das einen mathematisch „falschen“ Gradienten erzeugt – der Fehler ist nur ein konstanter Faktor, der bei ADAM praktisch ignoriert wird, oder lässt sich bei SGD im Optimizer kompensieren (ähnlich wie Loss-Scaling).
Zusammengefasst:
- Unit Scaling diktiert eine konstante Skalierung für die Init-Std der Modellgewichte. Wir nutzen abc-Symmetrie, um die eindeutige Version von μP zu identifizieren, die diese Constraint erfüllt.
- Empirisch identifizieren wir eine bessere Regel für die Embedding-Learning-Rate in Transformer-Modellen.
- Wir wenden eine manuelle Skalen-Korrektur in der Input-Gradient-Berechnung des Output-Layers an und nutzen 1/d−−√1/d statt 1/d1/d, um Unit Scaling im Backward-Pass wiederherzustellen.
Beachte: Die Unit-Scaling-Bedingung entfernt zudem den globalen Init-Std-Gain-Parameter, der ein üblicher Hyperparameter von μP ist. Man könnte fragen, ob das Entfernen von Hyperparametern zu restriktiv ist und das Risiko erhöht, in einer schlechten Region des Hyperparameter-Raums zu landen. Diese Frage adressieren wir als Nächstes.
u-Multiplikatoren: Ein kanonisches Set an Hyperparametern
Wenn Gewichts-Multiplikatoren und Anfangsvarianz aus den Hyperparametern entfernt werden, sieht es auf den ersten Blick so aus, als hätten wir den Hyperparameter-Raum massiv eingeschränkt. Individuelle Learning-Rate-Multiplikatoren sind weiterhin zulässig – empirisch funktioniert es aber meist gut, sie an eine globale Learning Rate zu binden.
Um genug Ausdrucksstärke in unserer Parametrisierung zu gewährleisten, ist die entscheidende Beobachtung, dass wir tatsächlich Multiplikatoren in bestimmten Teilen des Modells wieder einführen können, in denen Skala nicht propagiert. Veranschaulichen wir das an einem Beispiel: Betrachte das FFN eines Transformer-Blocks:
FFN(x)=Fdown(φ(Fup(x)))FFN(x)=Fdown(φ(Fup(x)))
wobei FdownFdown und FupFup die linearen Projektionen ohne Bias sind und φφ die Nichtlinearität ist. Üblicherweise gibt es eine Skip-Connection um das FFN, sodass der eigentliche Output berechnet wird als
y=x+FFN(x)y=x+FFN(x)
Denk daran, dass jeder lineare Layer mit einem festen Multiplikator daherkommt, der Unit Scaling garantiert. Nehmen wir an, wir wollen die Multiplikatoren, die zu
WupWup und WdownWdown gehören, um die Faktoren αupαup bzw. αdownαdown ändern. αdownαdown können wir implementieren, indem wir einfach eine neue Aktivierungsfunktion φα(x)=φ(α⋅x)φα(x)=φ(α⋅x) einführen. Das funktioniert, weil die lineare Operation den Faktor αdownαdown an die nächste Operation weitergibt. Wenn φ=GeLUφ=GeLU, propagiert φφ die Skala nicht – wir bekommen einen echten neuen Hyperparameter in Form der Pre-Aktivierungs-Temperatur für die GeLU-Funktion. Für αupαup können wir eine skalierte Residual-Add-Operation mit einem Residual-Gain-Parameter definieren
Rα(xskip,xres)=xskip+αxresRα(xskip,xres)=xskip+αxres
und αupαup im Residual-Gain subsumieren.
Wenn φ=ReLUφ=ReLU, kann αdownαdown sogar weiter zur nächsten linearen Operation und direkt zur Residual-Add-Operation propagiert werden. In diesem Fall bekommen wir keine Temperatur für die Aktivierungsfunktion und subsumieren beide Gewichts-Multiplikatoren im Residual-Gain-Parameter dieses Residual-Blocks.
Allgemein propagieren Residual-Add-Operationen und nicht-homogene Operationen (wie Softmax oder GeLU) Skala nicht und führen einen Multiplikator ein, der mit dieser Operation verknüpft ist – statt an ein konkretes Gewicht zu hängen. Indem wir Temperaturen für diese nichtlinearen Funktionen einführen, verzerren wir natürlich die Varianz des Outputs und müssen den Post-Op-Skalierungsfaktor anpassen, um Unit Scaling wiederherzustellen. Bei Residual-Add-Operationen wird das noch aufwendiger und erfordert einen zusätzlichen Trick. Das im Detail zu behandeln, sprengt den Rahmen dieses Blogposts – interessierte Leser:innen verweisen wir auf den Anhang unseres Papers, in dem das ausführlich erklärt wird.
Wenn wir dieses Vorgehen über die gesamte Pre-Norm-Transformer-Architektur fortsetzen, identifizieren wir 5 sinnvolle Hyperparameter, die wir u-Multiplikatoren nennen:
- Die Pre-Attention-Softmax-Temperatur αattn−softmaxαattn−softmax.
- Die Pre-Nichtlinearitäts-Temperatur im FFN αffn−actαffn−act, unter der Annahme eines Standard-GeLU- oder SwiGLU-FFN.
- Den Attention-Residual-Gain αres−attnαres−attn.
- Den FFN-Residual-Gain αres−ffnαres−ffn.
- Die Pre-Loss-Softmax-Temperatur αloss−softmaxαloss−softmax.
Für Hyperparameter-Unabhängigkeit hat es sich als hilfreich erwiesen, die Residual-Gain-Faktoren in zwei neue Hyperparameter umzuparametrisieren:
- αresαres – die gesamte Residual-Stärke.
- αres−attn−ratioαres−attn−ratio, das den Beitrag des Attention-Residuals relativ zum FFN-Residual steuert.
Wir finden, dass diese kanonischen Multiplikatoren weitgehend unabhängig voneinander sind – das macht Hyperparameter-Sweeps deutlich einfacher. Statt einer teuren Grid- oder Random-Search reicht es, einen unserer Hyperparameter nach dem anderen zu sweepen, um zum gleichen Downstream-Loss mit deutlich weniger Trials zu kommen.
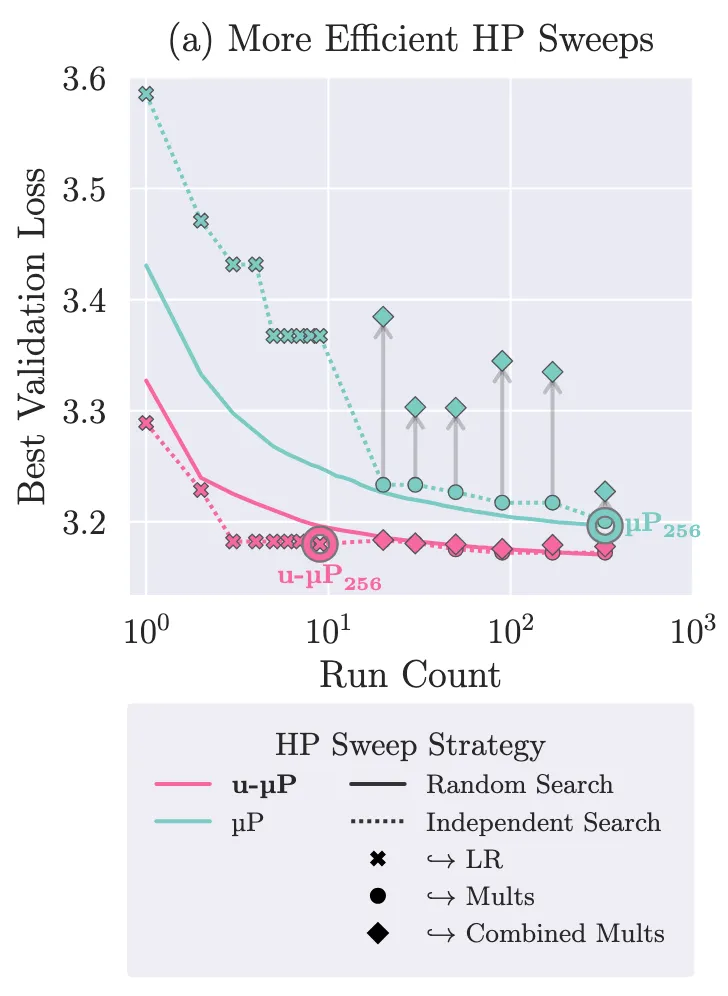
Außerdem übertragen sich globale Learning Rate und u-Multiplikatoren gut über Modellgrößen hinweg – der Default-Wert von 1 für die u-Multiplikatoren liegt oft nahe am Optimum.
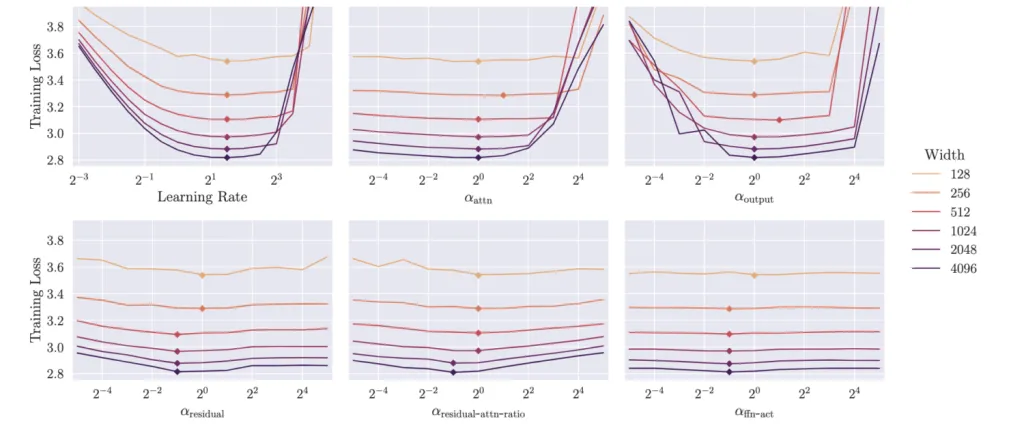
Abschließend wollen wir betonen, dass u-μP mit unseren u-Multiplikatoren und ggf. individuellen Learning Rates für einige Parametergruppen nahezu jede Hyperparameter-Konfiguration bei gegebener Modellgröße abbilden kann. Ähnlich wie wir u-μP ursprünglich entwickelt haben, muss man abc-Symmetrie nutzen, um alle Gewichtsvarianzen auf 1 zu schieben und dann die resultierenden Gewichts-Multiplikatoren in unsere u-Multiplikatoren zu absorbieren. Das braucht etwas Übung – die Belohnung für alle, die mit ihren Modell-Hyperparametern bereits zufrieden sind, ist: Du kannst sie in u-μP übersetzen und von den Vorteilen profitieren, z.B. einem out-of-the-box partiellen FP8-Trainings-Schema (siehe nächster Abschnitt).
Von der Theorie zur Praxis: u-μP in Aktion
Wir schließen mit einem Trainings-Report von u-μP in einem realistischen Trainings-Szenario. Das sollte ein guter Ausgangspunkt für alle sein, die u-μP für LLM-Training einsetzen wollen.
Architektur. Wir nutzen eine mehr oder weniger Standard-Transformer-Architektur in Anlehnung an LLAMA 2:
- Pre-Norm-Residuals
- SwiGLU-FFN
- Keine Biases
- RMS-Norm (nicht-parametrisch)
- Kein Weight-Tying
- Kein Group-Query-Attention
- Kein QK-Norm
- Kein Gradient-Clipping
- Kein z-Loss
- 4M Token Batch-Size (4096 Sequenzlänge und 1024 Batch-Size)
- Wir resetten die Attention-Mask nicht zwischen Dokumenten
- Cosine-LR-Schedule mit Decay auf 10% der Max-LR, 500 Warmup-Steps
- Independent Weight Decay von 2−132−13
- Kein Dropout
- Rotary-Positional-Embeddings mit Base 1e4
- Head-Dimension von 128
Independent Weight Decay, nicht-parametrische Norms und der Verzicht auf Biases sind Entscheidungen, die wir laut unseren Experimenten beim Einsatz von u-μP wärmstens empfehlen.
Wir verzichten bewusst auf das, was wir als Ad-hoc-Stabilisierungs-Techniken betrachten – QK-Normalisierung, Gradient-Clipping und z-Loss –, weil u-μP gezielt auf stabile Numerik ausgelegt ist. Man kann sie weiterhin anwenden (Gradient-Clipping müsste auf Gradient-Größen von Größenordnung eins angepasst werden), aber mit u-μP sind sie womöglich nicht mehr nötig.
Wir skalieren Layer- und Attention-Head-Anzahl (so viele Heads wie Layer) von 16 auf 24 auf 32 und kommen damit auf Modelle mit etwa 1B, 3B und 7B Parametern.
Wir trainieren 72k Iterationen (~300B Tokens) auf dem SlimPajama-Datensatz.
Für Learning Rate und u-Multiplikatoren machen wir einen unabhängigen Sweep auf einem kleinen Proxy-Modell und finden folgende optimalen Werte:
- Learning Rate η=23.5η=23.5
- Attention-Residual-Ratio αattn−residual−ratio=2−2αattn−residual−ratio=2−2
- Alle anderen Multiplikatoren werden bei 1 gehalten.
Learning Rate und Attention-Residual-Ratio hatten in unseren Sweeps mit Abstand den größten Einfluss – wir empfehlen daher, mindestens diese beiden zu optimieren.
FP8-Mixed-Precision. In initialen Trainings-Runs haben wir die Magnitude der Tensoren im gesamten Modell getrackt. Die meisten Tensor-Scales stabilisieren sich und wachsen nicht signifikant über ihre initiale Skala von 1 hinaus. Die Input-Tensoren zur Attention-Dense-Projection und zur finalen FFN-Projection (wir nennen diese Operationen kritische Matmuls) zeigen aber in einigen Layern plötzliches, explosives Wachstum:
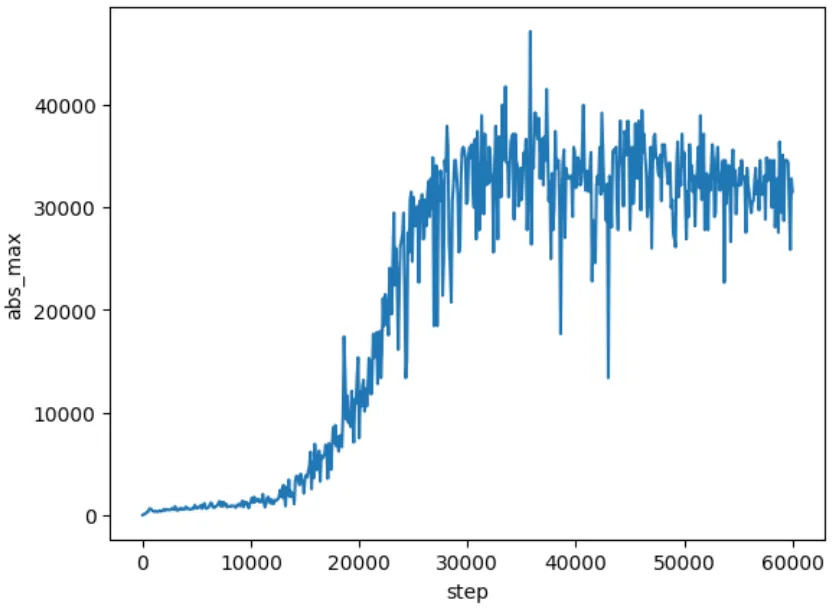
Das könnte mit der Bildung von Outlier-Features zu tun haben (siehe dieses Paper) und verdient zukünftige Untersuchung.
Basierend auf diesen Beobachtungen haben wir Modelle mit folgendem FP8-Mixed-Precision-Schema trainiert:
- Wir casten den Input und das Gewicht nicht-kritischer Matmuls auf FP8 E4M3 und den Gradienten bzgl. des Outputs auf FP8 E5M2.
- Kritische Matmuls, Embedding und Decoder-Head bleiben in BF16.
- Optimizer-States bleiben in FP32.
Der Unterschied zwischen E4M3 und E5M2: Ersterer nutzt 4 Bits für den Exponenten und 3 Bits für die Mantisse, Letzterer 5 Bits für den Exponenten und 2 Bits für die Mantisse. Für mehr Informationen verweisen wir auf dieses Paper.
Wir betonen, dass wir keinerlei Ad-hoc-Per-Tensor-Scaling vornehmen – wie es bei FP8-Training sonst üblich ist. Aufgrund der wohlverhaltenen numerischen Scales können wir einfach nach FP8 casten (man könnte Per-Tensor-Scaling weiterhin nutzen; wir zeigen lediglich, dass es für die meisten Tensoren beim Einsatz von u-μP nicht nötig ist).
Mit diesem partiellen FP8-Schema werden rund 70% der Matmuls im Transformer-Layer in FP8 ausgeführt – das führt direkt zu einer 35%igen Reduktion des Speicher-Footprints der Modellgewichte während der Inferenz. Was den Durchsatz angeht: Theoretisch lassen sich FP8-Matmuls auf Nvidia-H100-Hardware doppelt so schnell ausführen wie ihre 16-Bit-Pendants. Dieses Potenzial voll auszuschöpfen, erfordert technische Optimierungen, die außerhalb des Scopes dieses Papers lagen. Wir planen, das und weitere mögliche FP8-Speedups während des Trainings in zukünftiger Arbeit zu erkunden.
Um sowohl die Treue unseres FP8-Mixed-Precision-Schemas als auch unsere Hyperparameter zu testen, haben wir parallel zu unseren u-μP-FP8-Modellen zwei weitere Baselines trainiert:
- u-μP in Standard-BF16-Mixed-Precision
- Eine Standard-Parametrisierung (SP) als Baseline, die das tiefenskalierte Initialisierungs-Schema von Pythia und ein Learning-Rate-Schema verwendet, das invers linear mit der Hidden-Size skaliert (6e-4, 4e-4, 3e-4).
Die Ergebnisse dieser Trainings sind unten dargestellt:
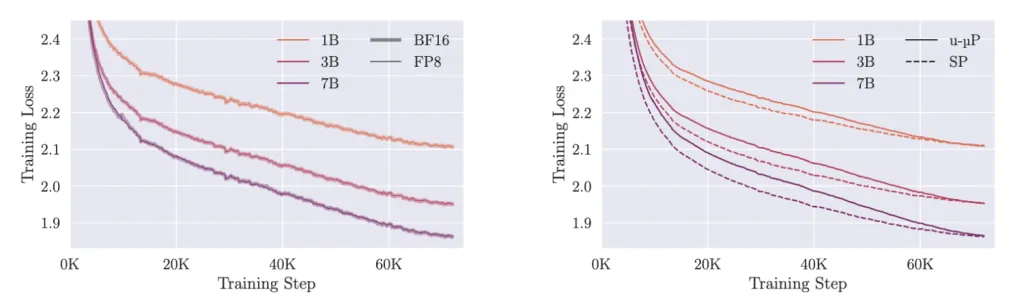
Wir sehen, dass die FP8-Modelle den Loss ihres BF16-Pendants eng nachvollziehen. Was u-μP vs. SP angeht: Die beiden Modellfamilien haben recht unterschiedliche Optimierungs-Trajektorien – SP hat zu Beginn des Trainings einen niedrigeren Loss, u-μP holt aber gegen Ende auf. Die Downstream-Evaluationen runden das Bild ab und zeigen kaum Degradation der FP8-Modelle sowie eine insgesamt starke Performance von u-μP.

Fazit
Themen wie Infinite-Width-Limits, Hyperparameter und Numerik können für Uneingeweihte recht herausfordernd sein – u-μP berührt all diese. Wir hoffen, dass Leser:innen, die in diesen Bereichen ganz neu sind, ebenso wie Erfahrenere etwas aus diesem Blogpost mitgenommen haben und nun Lust haben, tiefer in unsere Arbeit und die unserer Vorgänger:innen einzutauchen.
Auch wenn u-μP für uns und hoffentlich andere ein Meilenstein ist, gibt es noch viele offene Fragen. Es fehlt nach wie vor ein einheitliches Verständnis der Trainings-Dynamiken neuronaler Netze – darum ist empirische Hyperparameter-Suche überhaupt erst nötig. Auf Seite des Low-Precision-Trainings und der Effizienz sind wir fest überzeugt, dass Modell-Design-Entscheidungen, die auf mathematischen Prinzipien wie u-μP fußen, weitere Optimierungen ermöglichen und die Modellperformance vorantreiben.
Wenn du mehr über u-μP erfahren willst, schau gerne in unser Paper. Wenn du u-μP in der Praxis erleben willst, findest du unseren Code auf GitHub und die Modell-Checkpoints in unserem Hugging Face-Repository.