
Aleph Alpha Blog
Luminous-Explore – Ein Modell für semantische Repräsentation auf Weltklasse-Niveau
In diesem Beitrag stellen wir unser semantisches Embedding-Modell Luminous-Explore vor, zeigen State-of-the-Art-Ergebnisse auf zwei öffentlichen Benchmarks und gehen detailliert auf Philosophie und praktischen Einsatz semantischer Repräsentationen ein.
In diesem Beitrag stellen wir unser semantisches Embedding-Modell Luminous-Explore vor, zeigen State-of-the-Art-Ergebnisse auf zwei öffentlichen Benchmarks und gehen detailliert auf Philosophie und praktischen Einsatz semantischer Repräsentationen ein.
Inhalt:
- Ein Modell für semantische Repräsentation auf Weltklasse-Niveau
- Semantische Suche mit Luminous-Modellen
- Benchmarks für semantische Suche
- Semantische Embeddings mit Luminous erzeugen
- Über das Wesen semantischer Inhaltsrepräsentationen
- Was bedeutet eine gute semantische Inhaltsrepräsentation für Wissenschaft, Industrie und Gesellschaft?
Abstract
In diesem Beitrag stellen wir semantische Repräsentationen und semantische Suche mit Luminous-Modellen vor. Wir bieten zwei Arten semantischer Repräsentationen an: symmetrische Embeddings (für Klassifizierung, Clustering usw.) und asymmetrische Embeddings (für Information Retrieval und Kontext-Relevanz). Die mit Luminous-Explore erzeugten semantischen Repräsentationen erreichen State-of-the-Art-Performance auf den USEB-Benchmarks (5 von 5) und den BEIR-Benchmarks (1 von 4). Mit den bereitgestellten Code-Snippets sind die von Luminous-Explore erzeugten semantischen Repräsentationen für alle nutzbar. Mit unseren semantischen Repräsentationen wollen wir Informationen und Wissen zugänglicher machen.
Ein Modell für semantische Repräsentation auf Weltklasse-Niveau
Ein Ziel der natürlichen Sprachverarbeitung (NLP) ist das Verstehen der semantischen Bedeutung eines Textes. Mit Blick auf Use-Cases wie Suche, Clustering, Exploration, Klassifizierung oder Feature-Extraktion streben Forscher:innen sowohl nach hochwertigen als auch nach recheneffizienten Algorithmen, um Bedeutung zu verstehen, zu kodieren und zu vergleichen.
Willkommen Luminous-Explore – unser eigens entwickeltes Modell zur Erzeugung von Repräsentationen (Embeddings) von Text, das optimal auf semantische Ähnlichkeit eingestellt ist. Transformer-basierte KI-Modelle haben im NLP-Bereich Rekord um Rekord gebrochen und verändern und prägen weiterhin die Art und Weise, wie wir in einer Vielzahl von Anwendungen mit KI interagieren und sie nutzen. Mit den von Luminous-Explore generierten semantischen Repräsentationen leisten wir unseren Beitrag zur Weiterentwicklung des State-of-the-Art in NLP.
Um wertvolle semantische Repräsentationen zu erzeugen, haben wir den SGPT-Ansatz ([2202.08904] SGPT: GPT Sentence Embeddings for Semantic Search (arxiv.org)), der im Rahmen eines Praktikums bei Aleph Alpha entwickelt wurde, auf eine Modellgröße von 13 Milliarden Parametern hochskaliert. Mit dem resultierenden Modell präsentieren wir State-of-the-Art-Ergebnisse auf den USEB- und BEIR-Benchmarks für semantische Suche und erreichen 5 von 5 bzw. 1 von 5 Top-Scores.
Das Luminous-Base-Modell, das wir mit diesem Ansatz feinabgestimmt haben, ist sehr gut darin, Bedeutung auf einer höheren, konzeptuellen Ebene zu vergleichen. Die Fähigkeiten unserer semantischen Repräsentationen ermöglichen eine Vielzahl von Anwendungen, die auf dieser Funktionalität aufgebaut werden können – von semantischer Suche über geführte Zusammenfassung bis hin zu Klassifizierung. Diese Fähigkeiten sind öffentlich über unsere API verfügbar (Aleph Alpha API | Aleph Alpha API (aleph-alpha.com)).
Randbemerkung: Luminous – eine Familie mehrsprachiger Large Language Models
Luminous ist eine Familie von Large Language Models (LLM), die von Aleph Alpha entwickelt werden. Sie können natürliche Sprache in 5 verschiedenen Sprachen (Englisch, Deutsch, Französisch, Italienisch, Spanisch) mit State-of-the-Art-Performance generieren. Mehr über Luminous erfährst du hier: Luminous (aleph-alpha.com)

Semantische Suche mit Luminous-Explore
Mit unserem semantischen Repräsentationsmodell Luminous-Explore, das auf dem Luminous-Base-LLM mit 13 Mrd. Parametern aufbaut, erreichen wir State-of-the-Art-Ergebnisse im Vergleich zu anderen LLM-basierten semantischen Repräsentationsmodellen (Anchor-Benchmark-Unterkapitel).
Eine zentrale Anwendung semantischer Repräsentationen ist die semantische Suche, die die semantische Ähnlichkeit von Texten bewerten kann. Durch den Einsatz semantischer Repräsentationen können wir deutlich höhere Scores erreichen und mit höheren Konzepten arbeiten als andere, schlüsselwortbasierte Methoden. Eine bessere Suche bedeutet einfacheres Retrieval verwandter Daten und besseren Zugriff auf Informationen.
Um zu verstehen, was semantische Suche ist und was sie kann, müssen wir zuerst verstehen, wie sie funktioniert.
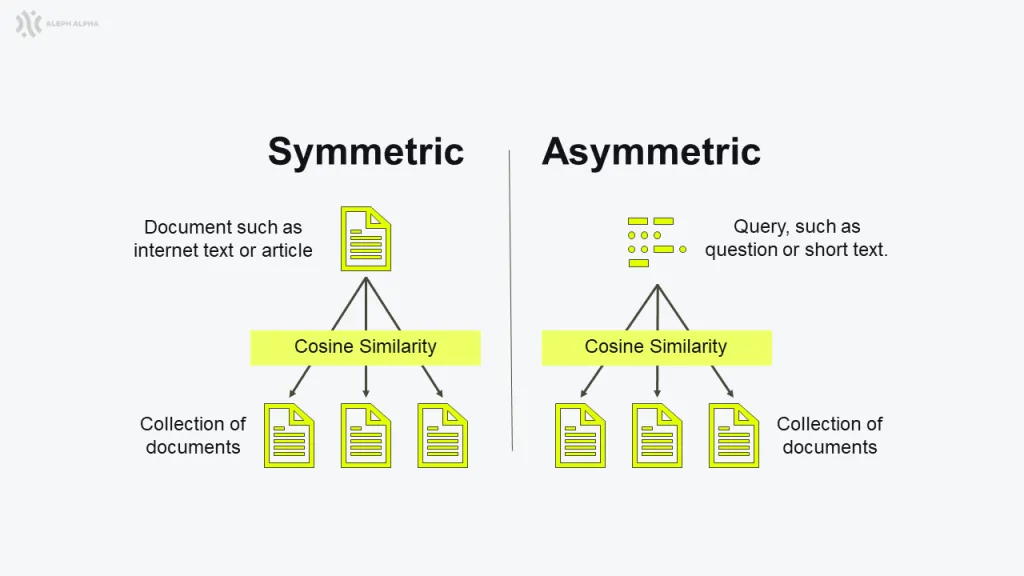
Abbildung 1: Der Unterschied zwischen symmetrischer und asymmetrischer Suche
Wir können semantische Ähnlichkeit – und damit auch Suche – in zwei Typen unterteilen: symmetrisch und asymmetrisch.
Symmetrische Suche bedeutet, dass wir neue Texte basierend auf der Ähnlichkeit zu einem bereits vorliegenden Text finden wollen. Das funktioniert besonders gut, wenn die gesuchten Texte nicht nur semantisch, sondern auch in Länge, Tonalität, Sprache usw. ähnlich sind. Symmetrische Suche kann aber generell für den Vergleich von zwei oder mehr Texten verwendet werden. Für die semantische Suche stellen wir ein Modell bereit, das alle Eingaben in symmetrische semantische Embeddings übersetzt.
Asymmetrische Suche ist hingegen darauf optimiert, die Ähnlichkeit zwischen zwei Texten zu maximieren, die in ihrer Form heterogen sind. In unserem Fall besteht die asymmetrische Suche aus zwei Modellen: eines, das auf das Embedding von Queries trainiert ist, und eines, das auf das Embedding von Dokumenten trainiert ist. Beide Modelle sind darauf optimiert, ähnliche Repräsentationen für Fragen und passende Texte zu erzeugen. Für asymmetrische Embeddings haben wir zwei separate Modelle – eines zum Einbetten von Queries (kurze Texte oder Fragen) und eines zum Einbetten von Dokumenten (längere Texte wie Dokumente oder Artikel).
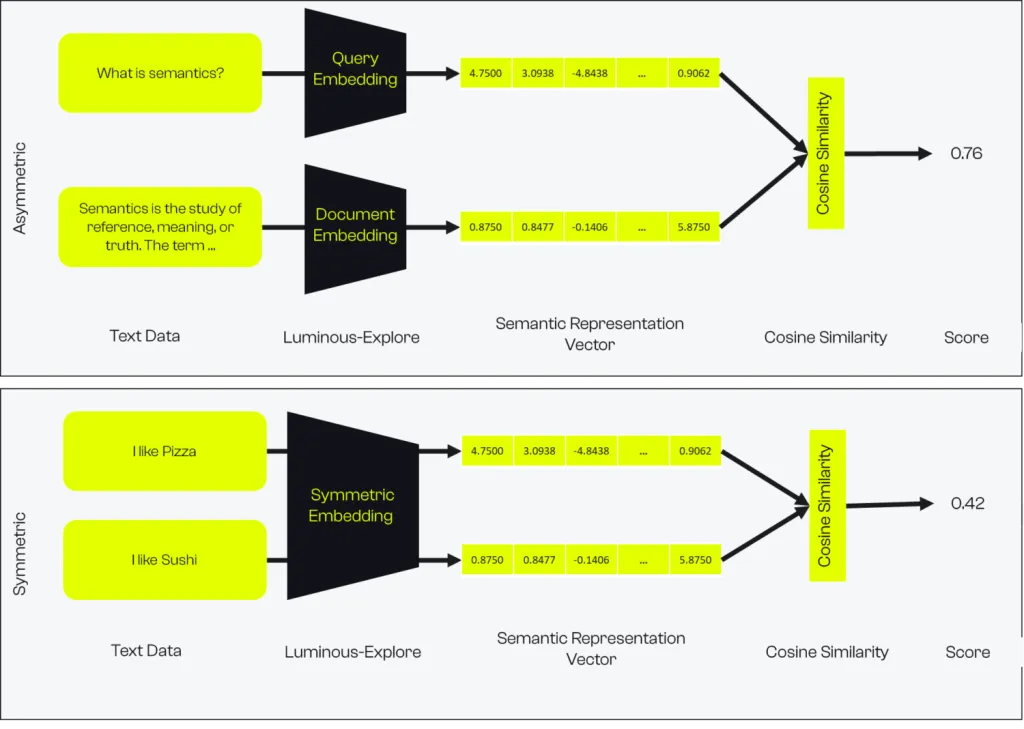
Abbildung 2: Ein Schema, wie Scores für die semantische Suche mit symmetrischen und asymmetrischen Modellen berechnet werden.
Benchmarks für semantische Suche
Wir haben gängige Open-Source-Benchmarks gefahren, um die Performance unserer symmetrischen und asymmetrischen Such-Modelle (oben beschrieben) zu bewerten. Die Benchmark-Ergebnisse sowie eine kurze Beschreibung findest du unten.
Evaluation der symmetrischen Suche auf dem USEB-Benchmark
Symmetrische Embeddings setzen voraus, dass die zu vergleichenden Texte austauschbar sind. Anwendungsbeispiele für symmetrische Embeddings sind Clustering, Regression, Anomalie-Erkennung oder Visualisierungs-Aufgaben. In Tabelle 1 findest du die Evaluationsergebnisse unserer symmetrischen Suche auf vier gängigen Datensätzen aus dem USEB-Benchmark (GitHub – UKPLab/useb: Heterogenous, Task- and Domain-Specific Benchmark for Unsupervised Sentence Embeddings used in the TSDAE paper: https://arxiv.org/abs/2104.06979.). Alle vier evaluieren unterschiedliche semantische Aufgaben. Wie die Tabelle zeigt, können wir mit unserem symmetrischen Embedding-Modell andere State-of-the-Art-Modelle auf allen vier Datensätzen übertreffen. Besonders auf CQA und SciDocs übertreffen wir die Ergebnisse der Curie-Modelle von OpenAI um 5,1% bzw. 11%.
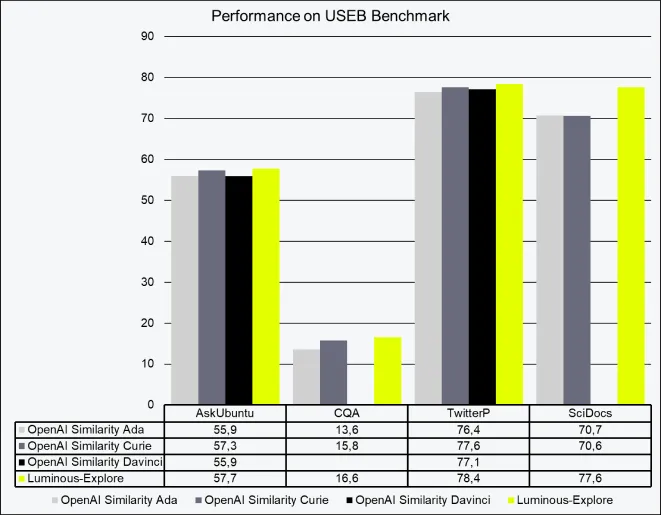
Tabelle 1: Performance von Luminous-Explore im Vergleich zu anderen LLM-basierten semantischen Repräsentationen auf dem USEB-Benchmark. Die Scores sind nDCG@10, Werte gerundet.
Evaluation der asymmetrischen Suche auf dem BEIR-Benchmark
Asymmetrische Embeddings setzen voraus, dass es einen Unterschied zwischen Queries und Dokumenten gibt. Anwendungsbeispiele für asymmetrische Suche sind Suche, Kontext-Relevanz und Information Retrieval. Wir testen unsere asymmetrischen Embeddings mit fünf gängigen Datensätzen aus dem BEIR-Benchmark (GitHub – beir-cellar/beir: A Heterogeneous Benchmark for Information Retrieval. Easy to use, evaluate your models across 15+ diverse IR datasets.), die in Tabelle 2 zu sehen sind. Wir übertreffen aktuelle SOTA-Modelle auf ArguaAna (14%) und zeigen wettbewerbsfähige Performance auf NFCorpus, SCIDOCS und SciFact.
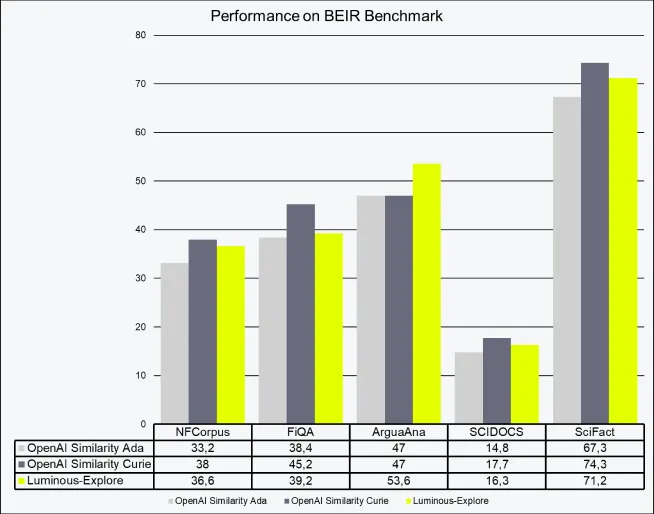
Tabelle 2: Performance von Luminous-Explore im Vergleich zu anderen LLM-basierten semantischen Repräsentationen auf dem BEIR-Benchmark. Die Scores sind nDCG@10, Werte gerundet.
Semantische Embeddings mit Luminous-Explore erzeugen
Semantische Embeddings mit Luminous-Explore zu erzeugen und in der eigenen Forschung oder im eigenen Produkt zu nutzen, ist einfach. Das geht entweder über einen REST-Call zu unserer API oder über das per pip installierbare aleph-alpha-client-Paket. Einmal erstellt, lassen sich Embeddings lokal speichern, um Zugriff und Berechnung zu beschleunigen.
Hier ist ein einfacher Code, um ein symmetrisches Embedding für einen Text zu erzeugen:
from aleph_alpha_client import AlephAlphaClient, AlephAlphaModel,
SemanticEmbeddingRequest, SemanticRepresentation, Prompt import os model =
AlephAlphaModel( AlephAlphaClient(host="https://api.aleph-alpha.com",
token=os.getenv("AA_TOKEN")), # You need to choose a model with semantic embedding
capability. model_name = "luminous-base" ) text_to_embed = "I really like Pizza." request
= SemanticEmbeddingRequest(prompt=Prompt.from_text(text_to_embed),
representation=SemanticRepresentation.Symmetric) result = model.semantic_embed(request)
print(result.embedding)
Wenn du die Embeddings für semantische Suche, Clustering oder andere
Anwendungen nutzen willst, findest du unten ein ausführlicheres Skript zur Verwendung der
Embedding-API (mehr dazu in unserer Aleph Alpha API | Aleph Alpha API (aleph-alpha.com)).
""" Running this script requires the installation of the aleph alpha client.
\`\`\`console pip install aleph-alpha-client \`\`\` """ from typing import Sequence from
aleph_alpha_client import ImagePrompt, AlephAlphaClient, AlephAlphaModel,
SemanticEmbeddingRequest, SemanticRepresentation, Prompt import math import os API_TOKEN =
"YOUR_API_TOKEN" model = AlephAlphaModel(
AlephAlphaClient(host="https://api.aleph-alpha.com", token=API_TOKEN), # You need to
choose a model with multimodal capabilities for this example. model_name = "luminous-base"
) # Texts to compare texts = [ "deep learning", "artificial intelligence", "deep diving",
"artificial snow", ] embeddings = [] for txt in texts: request =
SemanticEmbeddingRequest(prompt=Prompt.from_text(text),
representation=SemanticRepresentation.Symmetric) result = model.semantic_embed(request)
embeddings.append(result.embedding) # Calculate cosine similarities. Can use numpy or
scipy or another library to do this def cosine_similarity(v1: Sequence[float], v2:
Sequence[float]) -> float: "compute cosine similarity of v1 to v2: (v1 dot
v2)/{||v1||*||v2||)" sumxx, sumxy, sumyy = 0, 0, 0 for i in range(len(v1)): x =
v1[i]; y = v2[i] sumxx += x*x sumyy += y*y sumxy += x*y return
sumxy/math.sqrt(sumxx*sumyy) # Cosine similarities are in [-1, 1]. Higher means more
similar print("Cosine similarity between \\"%s\\" and \\"%s\\" is: %.3f" % (texts[0],
texts[1], cosine_similarity(embeddings[0], embeddings[1]))) print("Cosine similarity
between \\"%s\\" and \\"%s\\" is: %.3f" % (texts[0], texts[2],
cosine_similarity(embeddings[0], embeddings[2]))) print("Cosine similarity between
\\"%s\\" and \\"%s\\" is: %.3f" % (texts[0], texts[3], cosine_similarity(embeddings[0],
embeddings[3])))
Über das Wesen semantischer Inhaltsrepräsentationen
Ein Ziel der natürlichen Sprachverarbeitung ist das Verstehen der semantischen Bedeutung eines Textes. Mit Blick auf Use-Cases wie Suche, Clustering, Exploration, Klassifizierung oder Feature-Extraktion streben Forscher:innen sowohl nach hochwertigen als auch nach recheneffizienten Algorithmen, um Bedeutung zu verstehen, zu kodieren und zu vergleichen. Üblicherweise wird ein Text in eine semantische Repräsentation in Form eines Vektors (Liste von Zahlen) umgewandelt, auf die mathematische Operationen (z.B. Ähnlichkeitsmaße) angewendet werden können. Dieser Blogpost diskutiert das Wesen einer „guten“ semantischen Repräsentation im Hinblick auf den praktischen Einsatz.
Eine gute semantische Repräsentation behält sowohl breite als auch detaillierte Information
Hypothese: Eine gute semantische Inhaltsrepräsentation lässt sich sowohl auf sehr breite Cluster anwenden als auch auf Detailebene gut nutzen.
Eine nützliche Repräsentation dient dazu, Vorkommen innerhalb der Domäne oder Verteilung eines Use-Cases zu unterscheiden. Eine semantische Repräsentation einer breiten Menge an Tweets sollte beispielsweise vielfältige Themen und Meinungen identifizieren. Man würde generische Cluster und weniger Differenzierung auf Detailebene erwarten. Es kann genügen zu sagen, dass die Aussagen „Die Sonne scheint.“ und „Es regnet.“ beide zum Cluster „Wetter“ gehören. Eine spezialisierte Wetter-App hingegen könnte diese Aussagen als Gegensätze behandeln. Da das Thema Wetter ist, muss für eine sinnvolle Repräsentation klar unterschieden werden.
Nur bedeutungsbezogene Informationen sollten repräsentiert werden
Hypothese: Eine gute semantische Inhaltsrepräsentation behält nicht alle Informationen. Informationen, die nichts mit Bedeutung zu tun haben, sollten verworfen werden.
Paraphrasen sollten eine sehr ähnliche, wenn nicht dieselbe semantische Repräsentation ergeben. Die Repräsentation muss unabhängig vom Wortlaut sein – sonst könnte man auch einfach die verwendeten Wörter vergleichen. Daher kann eine Repräsentation nicht invertierbar sein, d.h. der ursprüngliche Text lässt sich aus der Repräsentation nicht rekonstruieren. Die Information wird in eine Repräsentation überführt, die geeignet ist, Bedeutung zu erfassen. Alles, was damit nichts zu tun hat, ist nutzlos und wird wahrscheinlich von einem Algorithmus entfernt, der auf Bedeutung optimiert ist und alles andere als störendes Rauschen behandelt.
Ähnlichkeit kann in mehreren (subjektiven) Dimensionen auftreten
Hypothese: Eine einzelne semantische Repräsentation kann nicht allen möglichen Interpretationen gerecht werden.
Jede Person vergleicht Aussagen intuitiv auf Basis eigener Interessen und Situationen. Betrachten wir folgende Ausdrücke:
- Es ist warm an meinem Kamin.
- Es ist ein warmer Sommertag.
- Ein furchterregendes Gewitter naht.
Welche dieser Aussagen sind sich am ähnlichsten? Wahrscheinlich evozieren der warme Kamin und der warme Sommertag ein Gefühl von Wohlbefinden und Entspannung. Außerdem wird der warme Kamin eher mit Winter assoziiert, während sich die anderen Aussagen klar auf den Sommer beziehen.
In der Praxis treten semantische Gegensätze selten auf
Hypothese: Vergleiche semantischer Repräsentationen sind immer relativ. Absolute Werte von Metriken sind selten aussagekräftig.
Eine gängige Metrik zum Vergleich zweier semantischer Repräsentationen ist die Kosinus-Ähnlichkeit. Mathematisch definiert sie einen Gegensatz (ein Vektor, der exakt in die entgegengesetzte Richtung zeigt). In der Praxis erwarten wir keinen echten Gegensatz. Aber was wäre das überhaupt? Betrachten wir folgende Beispiele:
- „Die Sonne scheint und es ist warm.“ vs. „Es regnet und ist kalt.“: Beide Aussagen beziehen sich auf das Wetter. Sie sind keine echten Gegensätze, sondern haben ein gemeinsames Thema.
- „Die Sonne scheint.“ vs. „Ich mag mein Auto.“: Auch wenn sich beide Aussagen auf verschiedene Themen beziehen, könnte man argumentieren, dass sich beide auf etwas im Außen beziehen. Sollten sie als Gegensätze gelten?
Innerhalb eines bestimmten Use-Cases lassen sich Gegensätze identifizieren. Zumindest auf philosophischer Ebene lassen sich aber häufig gemeinsame Merkmale in scheinbar unterschiedlichen Aussagen finden. Eine semantische Repräsentation, die solche Ähnlichkeiten nicht berücksichtigt, würde wohl nicht generalisieren. Dasselbe gilt für Verneinungen. Die Sätze „Ich habe kein Auto.“ und „Ich habe ein Auto.“ machen beide eine Aussage über Auto-Besitz. Sie teilen eine semantische Bedeutung zum Thema, machen aber unterschiedliche Aussagen auf Detailebene.
Das macht es schwer, Ähnlichkeitsmaße auf absoluter Ebene zu vergleichen. Metriken vergleichen vielmehr Ähnlichkeiten zwischen Aussagen, ohne einen absoluten Anspruch zu erheben.
Die Textlänge beeinflusst semantische Repräsentationen
Hypothese: Es gibt keine generell ideale Länge von Texten, die kodiert werden sollen. Der Use-Case entscheidet.
Eine semantische Repräsentation kodiert Bedeutung aus beliebig langem Text. Kurze Texte repräsentieren eher prägnante Informationen. Längere Texte können Aussagen zu verschiedenen Themen treffen und sogar widersprüchlich sein. Daher beeinflusst die Wahl der Textlänge (oder des Chunks) beim Kodieren in eine semantische Repräsentation die Nutzbarkeit. Ist der Text zu kurz, bietet er möglicherweise nicht genügend Detail für den Use-Case. Ist er zu lang, ergibt sich im Schnitt keine klare Bedeutung. (Die Bedeutung des Textes kann durch irrelevante Details verwässert werden.)
Informationen in Repräsentationen sollten unabhängig von Sprache sein
Hypothese: Sprache, Tonalität und Stil sollten in semantischen Repräsentationen ignoriert werden. Andere Repräsentationen für Sprache, Tonalität und Stil (unter anderem) können dafür angemessen sein.
Es ist diskutabel, ob Sprache eine bedeutungsrelevante Dimension ist. Man könnte argumentieren, dass Bedeutung unabhängig davon ist, in welcher Sprache sie ausgedrückt wird. Aber sind zwei Aussagen mit derselben Bedeutung nicht noch ähnlicher, wenn sie in derselben Sprache – womöglich sogar mit denselben Wörtern – ausgedrückt werden? Diese Argumentation lässt sich auf Tonalität und Stil ausdehnen. Use-Cases der semantischen Suche neigen dazu, Sprache, Tonalität und Stil zu ignorieren. Das Ziel ist, einen sehr guten Match zu finden (möglichst in guter Sprache) – selbst wenn die Suchanfrage ohne Rücksicht auf Grammatik und Rechtschreibung eingegeben wurde.
Jeder Use-Case erfordert eine passende Repräsentation
Zusammenfassung: Die besten Ergebnisse erzielt man, wenn man symmetrische oder asymmetrische Repräsentationen passend zum Use-Case einsetzt.
Nicht alle semantischen Repräsentationen haben denselben Zweck. Repräsentationen unterschiedlicher Textlänge und Sprache können unterschiedlichen Use-Cases dienen. Ein weiterer Ansatz ist die Unterscheidung zwischen symmetrischer und asymmetrischer Suche.
Symmetrische Repräsentationen betrachten zwei austauschbare Aussagen. Es gibt keine Reihenfolge. Übliche Use-Cases sind Clustering, Regression, Anomalie-Erkennung, Visualisierung oder Feature-Extraktion.
Asymmetrische Repräsentationen erzeugen je nach vordefinierter Klasse eines Textes unterschiedlichen Output. Übliche Beispiele sind Queries und Dokumente in einer semantischen Suche. Eine Query ist meist eine kurze Frage (die Information ist explizit unbekannt). Ein Dokument ist vergleichsweise lang und enthält die Antwort auf eine Query.
Manchmal enthält Bedeutung Interpretation
Zusammenfassung: Eine gute semantische Inhaltsrepräsentation respektiert Kontext und kann einen Text Interpretation unterziehen, um Bedeutung abzuleiten.
Sprache kodiert eine Menge Informationen. Das bloße Aufschreiben einer mündlichen Aussage eliminiert jede Interpretierbarkeit hinsichtlich nonverbaler Kommunikation wie Tonfall und Mimik. Manchmal kann sich dadurch die Bedeutung sogar komplett ändern. Vergleiche die Aussage „Oh, du bist schon wieder hier.“, wenn sie genervt oder freudig überrascht ausgesprochen wird. Neben der expliziten objektiven Aussage (die Person scheint sich am gleichen physischen Ort wie zuvor zu befinden) lässt sich zwischen den Zeilen mehr lesen. Ohne die Debatte von Semantik zu Pragmatik zu verschieben, lässt sich für die Bedeutung indirekter Information wie Absicht oder Emotion argumentieren, die für den Use-Case relevant sein kann. Zum Beispiel kann man Äußerungen von Unzufriedenheit in Support-Chats mit Kund:innen nicht (immer) anhand reinen Vokabulars und expliziter Aussagen finden, sondern muss den Kontext interpretieren. Dasselbe gilt für das Verzeihen von Rechtschreibfehlern, ausschweifenden Paraphrasen oder umständlichen Beschreibungen durch Nicht-Muttersprachler:innen (z.B. lässt sich „Dieses Bildschirmding mit der Tastatur.“ eher als Laptop und nicht als Instrument interpretieren).
Was bedeutet eine gute semantische Inhaltsrepräsentation für Wissenschaft, Industrie und Gesellschaft?
Die Antworten auf diese Frage sind zahlreich, vielfältig und noch nicht abschließend bestimmt. Wir möchten dennoch einige Bereiche ansprechen, in denen wir eine relevante Wirkung sehen:
Ein ganzheitlicherer Ansatz für Related Work
Related Work ist ein wesentlicher Teil jeder wissenschaftlichen Arbeit – Fortschritt ist nur möglich, wenn man „auf den Schultern von Riesen steht“. Heute gehört das Finden der richtigen Keywords sowie das Suchen und Sichten von Artikeln zu fast jedem wissenschaftlichen Vorgehen. Der Erfolg hängt oft davon ab, den korrekten Fachbegriff für das Forschungsfeld zu wählen. Bei vielen Themen ist das nicht trivial (z.B. Digital Twin, Digital Shadow, Digital Representation, Virtual Twin, Digital Clone, Virtual Mirror, Virtual Model …). Mit semantischen Embeddings wissenschaftlicher Literatur wandelt sich die Suche von Related Work weg vom Erstellen umfangreicher Keyword-Queries hin zu einer vielschichtigen Suche, die nicht eindimensional auf Keyword-Übereinstimmungen abstellt, sondern tatsächliche Ähnlichkeit über mehrere Dimensionen wie Thema, Intention, Methode, Daten, Ergebnisse usw. ranken kann.
Besonders Nachwuchsforscher:innen könnten sich einen Überblick über ein prospektives Forschungsfeld verschaffen, ohne die exakte Terminologie oder einschlägige Expert:innen kennen zu müssen. Das wiederum könnte die Durchführung neuer und innovativer Forschung verbreitern und beschleunigen – mit größerer Wertschöpfung.
Maschinen lernen menschliche Repräsentationen vs. Menschen lernen maschinelle Repräsentationen (jenseits der Keyword-Suche)
Wir sehen eine Zukunft, in der sich technische Systeme menschlichen Repräsentationen annähern und nicht umgekehrt.
Annäherungen an semantische Bedeutung zum Verwaltung menschlichen Wissens sind eine Daueraufgabe – vor allem durch den Einsatz künstlicher Ontologien, Keywords und Kategorien. Während Systeme sich weiterentwickelt haben, um menschliche Semantik besser abzubilden, haben sich auch Menschen an algorithmische Semantik angepasst. Ein Beispiel: Beim Web-Suchen kann die menschliche Intention lauten „Was sind traditionelle Restaurants in meiner Gegend, die ich mit Freund:innen besuchen kann?“. Die Query, die geübte Nutzer:innen in die Suchmaschine eintippen würden, sähe eher so aus: „traditionelle Restaurants Heidelberg“. Dieses Beispiel zeigt, dass Menschen ihr Verständnis relevanter Semantik an die Funktionalität von Wissensmanagement-Systemen angleichen. Da Maschinen keine menschlichen Repräsentationen erzeugen können, haben wir Menschen gelernt, unsere Gedanken und Absichten in maschinellen Repräsentationen darzustellen.
Aber hier könnten wir an einem Wendepunkt sein, an dem wir durch bessere semantische Repräsentationen langsam zu einer natürlicheren Art zurückkehren, unsere Absichten auszudrücken. Das bedeutet auch, dass ein zentrales Element des digitalen Daten-Managements – Keywords – an Bedeutung verlieren kann. Keywords lassen sich zwar weiterhin als zusätzliche Suchmetrik nutzen, aber Systeme müssen nicht zwingend darauf angewiesen sein, um gut zu performen. Dasselbe gilt für Synonyme und Antonyme oder den Einsatz von Fachbegriffen.
Wissensmanagement durch wirklich semantische Inhaltsrepräsentationen erweitern
Eine wirklich semantische Inhaltsrepräsentation ist eine Schlüsseltechnologie, um Wissensmanagement von seinem aktuellen Stand abzuheben. Das gilt nicht nur für Wissensmanagement-Systeme großer Unternehmen, sondern auch dafür, wie Wissen in unserer Gesellschaft gespeichert, verwaltet und abgerufen wird.
Ein Wissensmanagement-System mit echter semantischer Inhaltsrepräsentation kann per Design eine Schnittstelle umsetzen, die eher dem Fragen an menschliche Expert:innen gleicht als dem Eingeben von Keywords in eine Suchmaschine. Ein solches System erlaubt seinen Nutzer:innen, ihre Absichten genauso zu kommunizieren wie gegenüber anderen Menschen. Eine solche Schnittstelle kann Wissen für Nicht-Expert:innen zugänglicher machen und ihnen helfen, ihre Gedanken und Eingaben zu strukturieren. Wissen ist eine der wichtigsten Ressourcen einer modernen Gesellschaft – einen leichteren Zugang dazu zu ermöglichen, ist Voraussetzung für mehr Gleichheit bei gesellschaftlicher Teilhabe und Informationszugang.
Schnellzusammenfassung (von Luminous-Extended)
Semantische Embeddings auf Weltklasse-Niveau
- Luminous-Explore ist ein neues Modell zur Erzeugung von Repräsentationen (Embeddings) von Text, die optimal auf semantische Ähnlichkeit eingestellt sind.
- Die semantischen Repräsentationen von Aleph Alpha sind State-of-the-Art. Sie ermöglichen eine Vielzahl von Anwendungen, die auf dieser Funktionalität aufbauen – von semantischer Suche über geführte Zusammenfassung bis hin zu Klassifizierung.
Semantische Suche mit Luminous
- Das semantische Repräsentationsmodell baut auf dem Luminous-Base-Modell mit 13 Mrd. Parametern auf. Es erzielt State-of-the-Art-Ergebnisse im Vergleich zu anderen LLM-basierten semantischen Repräsentationsmodellen.
- Luminous unterstützt sowohl symmetrische als auch asymmetrische Suche. Symmetrische Suche bedeutet, neue Texte basierend auf der Ähnlichkeit zu einem bereits vorliegenden Text zu finden. Asymmetrische Suche ist darauf optimiert, die Ähnlichkeit zwischen zwei Texten zu maximieren, die in ihrer Form heterogen sind.
Über das Wesen semantischer Inhaltsrepräsentationen
- Eine gute semantische Repräsentation behält sowohl breite als auch detaillierte Information.
- Eine gute semantische Inhaltsrepräsentation behält nicht alle Informationen. Informationen, die nichts mit Bedeutung zu tun haben, sollten verworfen werden.
- Die Bedeutung einer Aussage wird nicht nur durch die verwendeten Wörter, sondern auch durch den Kontext bestimmt.
- Semantische Gegensätze treten in der Praxis selten auf.
- Die Länge der zu kodierenden Texte beeinflusst die Qualität semantischer Repräsentationen.
- Semantische Repräsentationen sollten unabhängig von Sprache, Tonalität und Stil sein.
- Semantische Repräsentationen sind nicht alle gleich. Manche sind symmetrisch, manche asymmetrisch.
- Eine gute semantische Inhaltsrepräsentation respektiert Kontext und kann einen Text Interpretation unterziehen, um Bedeutung abzuleiten.
Was bedeutet eine gute semantische Inhaltsrepräsentation für Wissenschaft, Industrie und Gesellschaft?
- Wir sehen eine Zukunft, in der sich technische Systeme menschlichen Repräsentationen annähern und nicht umgekehrt.
- Semantische Inhaltsrepräsentation ist eine Schlüsseltechnologie, um Wissensmanagement von seinem aktuellen Stand abzuheben.
- Ein Wissensmanagement-System mit echter semantischer Inhaltsrepräsentation kann per Design eine Schnittstelle umsetzen, die eher dem Fragen an menschliche Expert:innen gleicht als dem Eingeben von Keywords in eine Suchmaschine. Ein solches System erlaubt seinen Nutzer:innen, ihre Absichten genauso zu kommunizieren wie gegenüber anderen Menschen.
Autoren: Samuel Weinbach & Markus Schmitz