
Aleph Alpha Blog
Luminous-Performance-Benchmarks
Die Studie vergleicht Luminous u.a. mit den Modellen des GPT-3- und ChatGPT-Entwicklers OpenAI.
Wir präsentieren unsere Benchmark-Ergebnisse für die Large Language Models von Aleph Alpha:
luminous-base,luminous-extended und luminous-supreme
– verfügbar im Completion-Playground und über den API-Client. Luminous-Modelle folgen einer Decoder-only-autoregressiven Architektur mit
Rotary-Positional-Embeddings. Unsere Modelle werden auf einem kuratierten mehrsprachigen
Korpus mit Quellen auf Englisch, Deutsch, Französisch, Italienisch und Spanisch trainiert –
mit ca. 400 Mrd. bis ca. 588 Mrd. Sprach-Tokens für das kleinste bzw. größte Modell.
Lade das PDF hier herunter.
Inhaltsverzeichnis
- Evaluations-Framework
- Modellperformance auf Core-Tasks
- Modellperformance auf einem erweiterten Aufgabenset
- Few-Shot-Prompting
- Ergänzende Materialien
1. Evaluations-Framework
Während Aleph Alpha Playground und API auch Endpoints für Question-Answering, Embedding und Zusammenfassung sowie multimodale Fähigkeiten bieten, konzentrieren wir uns hier auf die Evaluation textbasierter Completions des Large Language Models. Dafür nutzen wir das Evaluation-Harness-Package (lm-eval) von EleutherAI.
Die Korrektheit der Completions messen wir, wo möglich, mit der Soft-Accuracy-Metrik (acc). Dabei wird für jede mögliche Multiple-Choice-Completion-Option die Log-Likelihood-Wahrscheinlichkeit gemessen, und diejenige mit der höchsten Wahrscheinlichkeit ausgewählt, um die Genauigkeit der Vorhersage gegenüber der Ground-Truth-Option zu bestimmen. Für generative Aufgaben wird eine Exact-Match-Accuracy-Metrik (exact) berechnet, indem geprüft wird, ob die Modell-Completion exakt mit dem erwarteten Output übereinstimmt. Die mit exact evaluierten Aufgaben sind: squad2, triviaqs und webqs.
Hinweis: Wenn wir mit anderen Modellen vergleichen, tun wir das nur für Ergebnisse, die mit diesem gemeinsamen Benchmarking-Setup erzeugt wurden – Evaluationsergebnisse können bei einigen Tasks durch Prompt-Formulierung, Checkpoint-Formate, verwendete Daten-Splits etc. von publizierten Werten abweichen.
2. Modellperformance auf Core-Tasks
Zunächst zeigen wir Ergebnisse für unser aktuelles bestes Modell (luminous-supreme mit 70 Mrd. Parametern) auf einem Set von 16 Core-Tasks – im Vergleich zu Benchmark-Ergebnissen von BigScience BLOOM (176B) und Meta AI OPT (175B), die mit lm-eval erzeugt wurden (siehe Link hier). OpenAI davinci (175B) wird von uns selbst mit demselben Setup wie für unsere Aleph Alpha Luminous-Modelle evaluiert. Wir verzeichnen über alle 16 Tasks gemittelt wettbewerbsfähige Accuracy-Ergebnisse – besonders angesichts unserer kleineren Architektur im Vergleich zu den anderen Modellen.
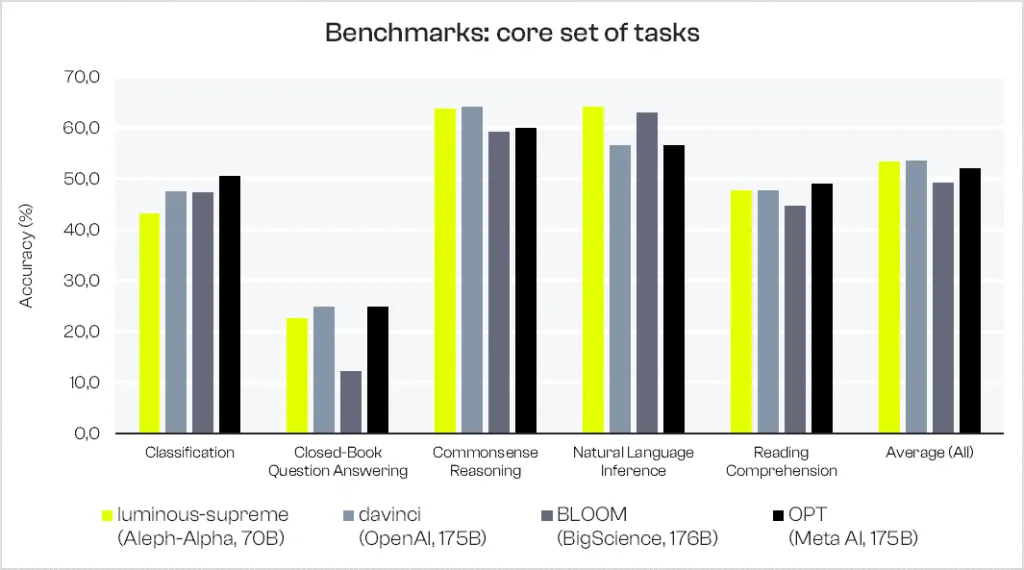
Die untersuchten Tasks decken fünf Gruppen ab:
- Klassifikation (wic),
- Closed-Book Question Answering (triviaqa, webqs),
- Common-Sense-Reasoning (arc_challenge, arc_easy, copa, hellaswag, openbookqa, piqa, winogrande, wsc),
- Natural Language Inference (rte),
- Reading Comprehension (boolq, lambada, multirc, race).
Beispiel-Prompts für die evaluierten Tasks und detaillierte Performance-Informationen findest du im Abschnitt mit den ergänzenden Materialien in Kapitel 6.
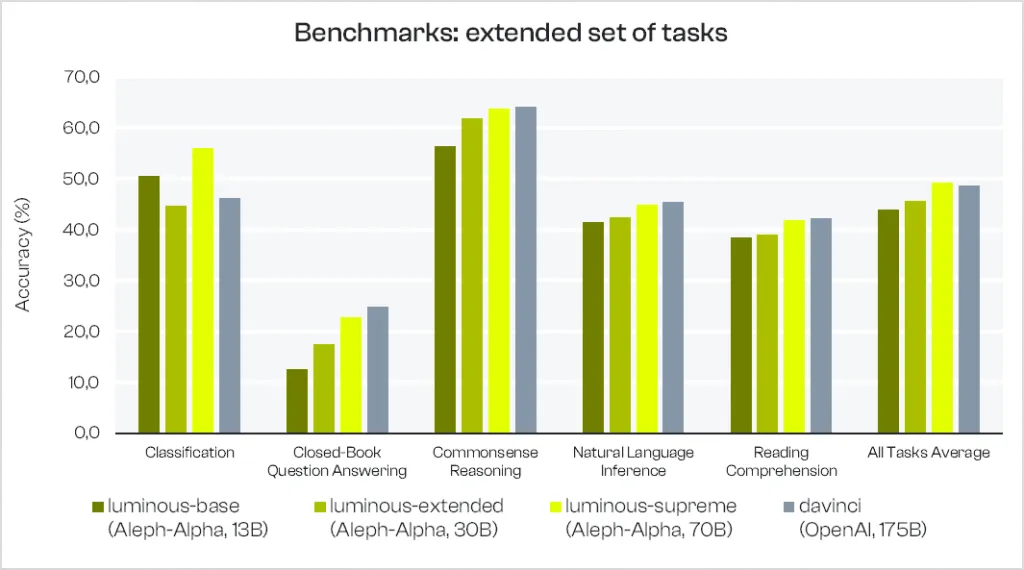
3. Modellperformance auf einem erweiterten Aufgabenset
Zusätzlich veröffentlichen wir weitere Benchmark-Ergebnisse mit 12 zusätzlichen Tasks und erweitern das Evaluationsset auf insgesamt 28 Tasks. Wir ergänzen unseren Vergleich um unsere beiden alternativen kleineren Modelle luminous-base und luminous-extended mit 13 Mrd. bzw. 30 Mrd. Parametern.
Die zusätzlichen Tasks sind:
- Klassifikation (mrpc, sst
), - Natural Language Inference (anli_r1, anli_r2, anli_r3, cb, mnli, mnli_mismatched, qnli, wnli),
- Reading Comprehension (squad2, race_mid).
Aus der untenstehenden Grafik lässt sich erkennen, dass Performance-Verbesserungen über alle untersuchten Task-Typen hinweg auftreten, sobald die Modellgröße steigt. Dieser Trend deckt sich mit empirischen Scaling-Law-Beobachtungen aus vorheriger Arbeit. Wir erwarten weitere Verbesserungen mit unserem hochskalierten luminous-world-Modell (folgt bald).
4. Few-Shot-Prompting
Die Tabelle unten zeigt die Benchmark-Ergebnisse mit Few-Shot-Prompting für die oben genannten 16 Core-Tasks. Null bis fünf Beispiele (in lm-eval durch zwei neue Zeilen getrennt) werden im Prompt als Input für die Completion konkateniert.
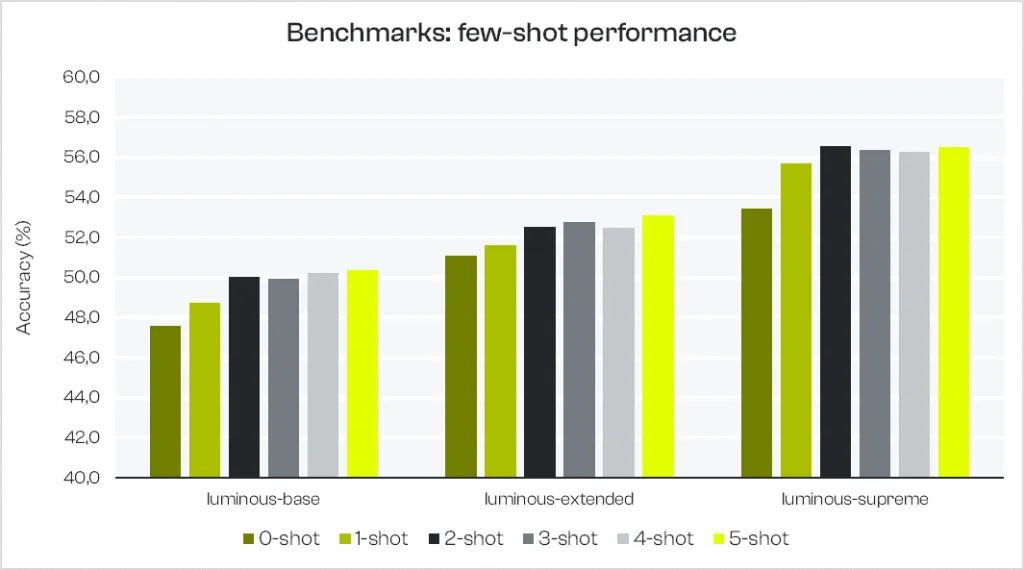
Few-Shot-Prompting hilft, die Performance bei Completion-Tasks für unsere Luminous-Modelle zu verbessern (6% bei luminous-supreme zwischen 0-Shot und 5-Shots). Je nach Anforderungen der Endnutzer:innen erlaubt das auch schnellere und günstigere Inferenz mit kleineren Modellen, ohne bei der Genauigkeit Kompromisse zu machen: Zum Beispiel können 5-Shot-Beispiele bei luminous-extended im Schnitt eine Performance ermöglichen, die fast so gut ist wie 0-Shot bei luminous-supreme.
Während die Tabelle Likelihood-basierte Genauigkeiten vergleicht, haben wir einen noch größeren Effekt auf Exact-Match-Completion-Tasks beobachtet – dort helfen die Few-Shot-Beispiele, die Performance zu steigern, indem sie dem Modell Beispiele dafür geben, welcher Antworttyp erwartet wird.
Zusätzlich haben wir eine Ablationsstudie durchgeführt, in der luminous-supreme erneut mit 1-Shot-Beispielen evaluiert wurde – diesmal aber mit „\\n###\\n“ als Separator (wie üblicherweise in unseren Playground-Beispielen) statt der lm-eval-Standard- Zeilenwechsel „\\n\\n“. Beide Few-Shot-Separatoren liefern sehr nahe beieinander liegende durchschnittliche Accuracy-Werte (55,3% mit „\\n###\\n“ und 55,7% mit „\\n\\n“), und die Scores für einzelne Tasks liegen innerhalb von 5% auseinander.
5. Ergänzende Materialien
Benchmark-Ergebnisse auf dem Core-Aufgabenset
| Task & Kategorie | Metrik | luminous-base (Aleph-Alpha, 13B) | luminous-extended (Aleph-Alpha, 30B) | luminous-supreme (Aleph-Alpha, 70B) | davinci (OpenAI, 175B) | BLOOM (BigScience, 176B) | OPT (Meta AI, 175B) |
|---|---|---|---|---|---|---|---|
| arc_challenge (CR) | acc | 37.0 | 40.7 | 44.2 | 43.2 | 41.1 | 41.2 |
| arc_easy (CR) | acc | 70.3 | 75.0 | 76.9 | 76.5 | 72.6 | 75.1 |
| boolq (RC) | acc | 68.3 | 69.1 | 74.3 | 73.4 | 70.4 | 80.2 |
| copa (CR) | acc | 83.0 | 84.0 | 90.0 | 89.0 | 87.0 | 84.0 |
| hellaswag (CR) | acc | 53.3 | 56.9 | 59.2 | 59.1 | 53.5 | 59.2 |
| lambada (RC) | acc | 70.2 | 72.5 | 74.0 | 75.1 | 67.2 | 74.7 |
| multirc (RC) | acc | 1.7 | 1.6 | 1.9 | 4.0 | 2.4 | 1.6 |
| openbookqa (CR) | acc | 27.8 | 29.4 | 33.0 | 33.6 | 31.2 | 32.2 |
| piqa (CR) | acc | 77.3 | 78.8 | 79.9 | 79.1 | 78.1 | 79.1 |
| race (RC) | acc | 37.2 | 38.6 | 40.8 | 38.6 | 39.0 | 40.2 |
| rte (NLI) | acc | 57.0 | 57.4 | 64.3 | 56.7 | 63.2 | 56.7 |
| triviaqa (QA) | exact | 20.5 | 28.7 | 37.7 | 40.9 | 18.3 | 34.2 |
| webqs (QA) | exact | 4.5 | 6.2 | 7.8 | 8.9 | 6.2 | 15.9 |
| wic (CL) | acc | 49.8 | 47.5 | 43.3 | 47.6 | 47.5 | 50.6 |
| winogrande (CR) | acc | 64.6 | 67.3 | 70.0 | 69.9 | 71.0 | 73.6 |
| wsc (CR) | acc | 38.5 | 63.5 | 57.7 | 63.5 | 40.4 | 36.5 |
| Klassifikation | 49.8 | 47.5 | 43.3 | 47.6 | 47.5 | 50.6 | |
| Closed-Book Question Answering | 12.5 | 17.4 | 22.7 | 24.9 | 12.2 | 25.0 | |
| Commonsense-Reasoning | 56.5 | 62.0 | 63.9 | 64.2 | 59.4 | 60.1 | |
| Natural Language Inference | 57.0 | 57.4 | 64.3 | 56.7 | 63.2 | 56.7 | |
| Reading Comprehension | 44.4 | 45.4 | 47.7 | 47.8 | 44.8 | 49.2 | |
| Durchschnitt (alle) | 47.6 | 51.1 | 53.4 | 53.7 | 49.3 | 52.2 |
Benchmark-Ergebnisse auf dem erweiterten Aufgabenset
| Task & Kategorie | Metrik | luminous-base (Aleph-Alpha, 13B) | luminous-extended (Aleph-Alpha, 30B) | luminous-supreme (Aleph-Alpha, 70B) | davinci (OpenAI, 175B) |
|---|---|---|---|---|---|
| anli_r1 (NLI) | acc | 33.3 | 30.8 | 33.7 | 36.1 |
| anli_r2 (NLI) | acc | 33.5 | 35.5 | 34.1 | 37.5 |
| anli_r3 (NLI) | acc | 33.6 | 36.8 | 36.1 | 36.8 |
| cb (NLI) | acc | 41.1 | 30.4 | 35.7 | 41.1 |
| squad2 (RC) | exact | 9.9 | 10.7 | 18.9 | 21.1 |
| mnli (NLI) | acc | 36.0 | 42.0 | 45.9 | 39.6 |
| mnli_mismatched (NLI) | acc | 35.7 | 43.7 | 47.1 | 41.0 |
| mrpc (CL) | acc | 47.8 | 36.5 | 65.4 | 39.5 |
| qnli (NLI) | acc | 50.7 | 53.6 | 50.5 | 52.0 |
| race_mid (RC) | acc | 43.4 | 41.4 | 40.9 | 41.4 |
| sst (CL) | acc | 54.0 | 49.9 | 59.5 | 51.3 |
| wnli (NLI) | acc | 52.1 | 52.1 | 56.3 | 67.6 |
| Klassifikation | 50.6 | 44.6 | 56.1 | 46.1 | |
| Closed-Book Question Answering | 12.5 | 17.4 | 22.7 | 24.9 | |
| Commonsense-Reasoning | 56.5 | 62.0 | 63.9 | 64.2 | |
| Natural Language Inference | 41.4 | 42.5 | 44.9 | 45.4 | |
| Reading Comprehension | 38.5 | 39.0 | 41.8 | 42.3 | |
| Durchschnitt aller Tasks | 44.0 | 45.7 | 49.3 | 48.7 |
Benchmark mit Few-Shot-Prompts
| Task & Kategorie | Metrik | luminous-base 0-Shot | luminous-base 1-Shot | luminous-base 2-Shot | luminous-base 3-Shot | luminous-base 4-Shot | luminous-base 5-Shot | luminous-extended 0-Shot | luminous-extended 1-Shot | luminous-extended 2-Shot | luminous-extended 3-Shot | luminous-extended 4-Shot | luminous-extended 5-Shot | luminous-supreme 0-Shot | luminous-supreme 1-Shot | luminous-supreme 2-Shot | luminous-supreme 3-Shot | luminous-supreme 4-Shot | luminous-supreme 5-Shot |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| arc_challenge (CR) | acc | 37.0 | 37.5 | 39.2 | 39.6 | 38.8 | 39.1 | 40.7 | 42.7 | 44.5 | 44.2 | 44.1 | 44.8 | 44.2 | 47.8 | 49.7 | 49.7 | 50.0 | 50.3 |
| arc_easy (CR) | acc | 70.3 | 72.4 | 72.6 | 72.8 | 73.2 | 73.2 | 75.0 | 75.9 | 76.9 | 77.1 | 76.8 | 76.6 | 76.9 | 78.0 | 79.5 | 79.9 | 79.7 | 80.1 |
| boolq (RC) | acc | 68.3 | 68.9 | 71.4 | 69.4 | 69.0 | 70.1 | 69.1 | 72.7 | 70.6 | 71.7 | 70.4 | 72.1 | 74.3 | 76.8 | 77.8 | 77.7 | 77.9 | 77.7 |
| copa (CR) | acc | 83.0 | 78.0 | 84.0 | 83.0 | 83.0 | 84.0 | 84.0 | 82.0 | 84.0 | 86.0 | 86.0 | 90.0 | 90.0 | 91.0 | 89.0 | 91.0 | 90.0 | 91.0 |
| hellaswag (CR) | acc | 53.3 | 53.2 | 53.4 | 53.7 | 53.6 | 53.6 | 56.9 | 56.5 | 57.1 | 57.3 | 57.4 | 57.4 | 59.2 | 59.6 | 60.1 | 60.1 | 60.0 | 60.2 |
| lambada (RC) | acc | 70.2 | 66.9 | 67.9 | 68.6 | 68.7 | 68.9 | 72.5 | 69.6 | 70.1 | 71.6 | 71.7 | 72.3 | 74.0 | 71.5 | 71.7 | 72.5 | 72.6 | 73.5 |
| multirc (RC) | acc | 1.7 | 4.7 | 5.1 | 4.5 | 4.7 | 3.4 | 1.6 | 4.7 | 4.8 | 3.7 | 2.9 | 3.4 | 1.9 | 4.6 | 4.3 | 2.9 | 3.6 | 1.8 |
| openbookqa (CR) | acc | 27.8 | 28.2 | 31.4 | 30.2 | 31.8 | 32.4 | 29.4 | 32.4 | 35.2 | 33.4 | 33.0 | 33.8 | 33.0 | 33.2 | 37.0 | 34.4 | 37.4 | 35.8 |
| piqa (CR) | acc | 77.3 | 76.9 | 77.8 | 77.4 | 77.5 | 77.1 | 78.8 | 77.9 | 78.1 | 78.5 | 77.8 | 77.7 | 79.9 | 79.7 | 79.9 | 79.8 | 80.6 | 80.4 |
| race (RC) | acc | 37.2 | 37.0 | 36.8 | 38.6 | 38.4 | 38.2 | 38.6 | 39.2 | 40.0 | 40.0 | 39.3 | 40.9 | 40.8 | 40.6 | 41.4 | 41.5 | 42.3 | 41.1 |
| rte (NLI) | acc | 57.0 | 61.4 | 57.0 | 59.6 | 58.8 | 56.3 | 57.4 | 59.6 | 58.1 | 60.3 | 55.6 | 56.7 | 64.3 | 63.2 | 69.0 | 66.8 | 65.3 | 67.9 |
| triviaqa (QA) | acc | 20.5 | 27.6 | 29.6 | 30.2 | 30.6 | 30.8 | 28.7 | 34.0 | 35.0 | 35.9 | 35.8 | 36.2 | 37.7 | 40.1 | 40.8 | 41.2 | 41.2 | 41.8 |
| webqs (QA) | acc | 4.5 | 13.6 | 17.0 | 17.7 | 19.6 | 20.3 | 6.2 | 17.7 | 21.2 | 23.1 | 25.1 | 24.6 | 7.8 | 18.6 | 22.8 | 26.1 | 26.2 | 28.1 |
| wic (CL) | acc | 49.8 | 48.6 | 53.9 | 49.2 | 51.1 | 54.5 | 47.5 | 47.6 | 54.4 | 52.5 | 55.6 | 54.9 | 43.3 | 50.6 | 53.0 | 53.1 | 55.0 | 55.5 |
| winogrande (CR) | acc | 64.6 | 67.0 | 66.5 | 67.6 | 68.5 | 67.0 | 67.3 | 68.7 | 69.9 | 69.6 | 71.3 | 71.3 | 70.0 | 71.7 | 73.8 | 72.2 | 74.2 | 74.9 |
| wsc (CR) | acc | 38.5 | 37.5 | 36.5 | 36.5 | 36.5 | 36.5 | 63.5 | 44.2 | 40.4 | 39.4 | 36.5 | 36.5 | 57.7 | 63.5 | 55.8 | 52.9 | 44.2 | 44.2 |
| Durchschnitt aller Tasks | 47.6 | 48.7 | 50.0 | 49.9 | 50.2 | 50.3 | 51.1 | 51.6 | 52.5 | 52.8 | 52.5 | 53.1 | 53.4 | 55.7 | 56.6 | 56.4 | 56.3 | 56.5 |
Beispiel-Prompts für verschiedene Task-Kategorien# Classification example: # - wic with Likelihood-based accuracy metric prompt = """
Sentence 1: Let's break for lunch. Sentence 2: A man broken by the terrible experience of
near-death. Question: Is the word 'break' used in the same way in the two sentences above?
Answer:""" expected_completion = " no" # evaluate against the following completions:
[yes/no] # Closed-Book Question Answering example: # - triviaqa with Exact Match accuracy
metric checked against a list of correct answers prompt = """ Question: What type of
leaves does a koala feed on? Answer:""" expected_completion = " Eucalypti" # the following
are also correct answers: [Eucalyptus/Gum trees/Gum-tree/Ευκάλυπτος] # Commonsense
Reasoning example: # - copa with Likelihood-based accuracy metric prompt_1 = "The man
perceived that the woman looked different because the woman got her hair cut." prompt_2 =
"The man perceived that the woman looked different because the woman wore a bracelet." #
correct answer # Natural Language Inference example: # - rte with Likelihood-based
accuracy metric prompt = """ The number of Danes opposed to swapping the krone for the
euro has increased slightly to 35.3 percent, up from 34.6 percent in April, according to a
poll published on Thursday by Danske Bank. Question: The introduction of the euro has been
opposed. True or False? Answer:""" expected_completion = " True" # evaluate against the
following completions: [True/False] # Reading Comprehension example: # - xquad_en with
Exact Match accuracy metric prompt = """ Between Bingen and Bonn, the Middle Rhine flows
through the Rhine Gorge, a formation which was created by erosion. The rate of erosion
equaled the uplift in the region, such that the river was left at about its original level
while the surrounding lands raised. The gorge is quite deep and is the stretch of the
river which is known for its many castles and vineyards. It is a UNESCO World Heritage
Site (2002) and known as "the Romantic Rhine", with more than 40 castles and fortresses
from the Middle Ages and many quaint and lovely country villages. Question: What flows
between Bingen and Bonn? Answer:""" expected_completion = "Middle Rhine"
Beispiel-Prompt aus der Few-Shot-Studie
# Few-shot prompting example # - boolq dataset with 2-shot prompt prompt=""" Central
government -- A central government is the government of a nation-state and is a
characteristic of a unitary state. This is the same thing as a federal government which
may have distinct powers at various levels authorized or delegated to it by its member
states, though the adjective 'central' is sometimes used to describe it. The structure of
central governments varies. Many countries have created autonomous regions by delegating
powers from the central government to governments at a subnational level, such as a
regional, state or local level. Based on a broad definition of a basic political system,
there are two or more levels of government that exist within an established territory and
govern through common institutions with overlapping or shared powers as prescribed by a
constitution or other law. Question: is national and federal government the same thing?
Answer: yes White House -- The White House is the official residence and workplace of the
President of the United States. It is located at 1600 Pennsylvania Avenue NW in
Washington, D.C., and has been the residence of every U.S. president since John Adams in
1800. The term White House is often used as a metonym for the president and his advisers,
as in \`\`The White House announced that...''. Question: is the white house in the state
of washington? Answer: no NCIS: New Orleans (season 4) -- The fourth season of NCIS: New
Orleans premiered on September 26, 2017 on CBS. The series continues to air following
Bull, Tuesday at 10:00 p.m. (ET) and contained 24 episodes. The season concluded on May
15, 2018. Question: is ncis new orleans over for the season? Answer:"""