
Michael Barlow
Model Training als Code
TL;DR: Model Training ist komplex genug geworden, dass es viele spezialisierte Phasen und Teams erfordert – und manuelle Koordination zwischen ihnen skaliert nicht. Bei Aleph Alpha haben wir Savanna gebaut, eine Modell-Fabrik, die die gesamte Trainings-Pipeline in Code abbildet und Model Training so in ein kollaboratives Software-Projekt verwandelt. In Savanna sind End-to-End-Trainingsläufe hermetisch und lassen sich mit einem Klick starten. Dieser Beitrag beschreibt Savanna, warum es notwendig ist und welche Engineering-Kultur es wirksam macht.
Einführung
Model Training entwickelt sich rasant. Neue Phasen kommen ständig zur Pipeline hinzu und bestehende werden komplexer – damit wird Model Training aus drei Gründen zu einer Engineering-Herausforderung. Erstens bedeutet mehr Komplexität mehr Raum für Fehler: Bugs oder Inkonsistenzen in Daten, Code oder Konfiguration können ganze Trainingsläufe scheitern oder driften lassen. Zweitens steigen die Kosten eines Fehlschlags stetig: Modelle werden größer, GPU-Preise höher, und pro Lauf werden immer mehr Daten verarbeitet. Wenn du Tausende GPU-Stunden verbrennst, ist „Ups" ein teures Wort.
Die dritte und schwerste Herausforderung ist organisatorisch. Die Komplexität ist längst größer geworden als die Kapazität eines einzelnen Kopfes, weshalb Labs wie unseres große, spezialisierte Teams aufgebaut haben. Das Problem ist dann die Koordination dieser Teams. Wie können Mitglieder autonom die neuesten Forschungsergebnisse in ihrem Spezialgebiet erkunden und dabei ihre Änderungen in die Produktions-Pipeline integrieren, ohne sie zu brechen oder sich gegenseitig zu stören? Und wie stellen sie sicher, dass Verbesserungen einzelner Phasen am Ende auch zu einem besseren Modell führen?
Traditionelle, manuelle Model-Training-Prozesse haben auf diese Fragen keine guten Antworten.
Die versteckten Kosten manuellen Model Trainings
Brechen wir den traditionellen manuellen Prozess herunter. Auf hoher Flughöhe wirkt Model Training simpel: Pre-Training, um das Internet zu absorbieren, gefolgt von Post-Training, um Instruction-Following zu lernen. In der Realität trainierst du beim ersten Versuch kein gutes Modell. Zu einer guten Datenmischung, Architektur und Trainings-Rezeptur zu kommen, ist ein iterativer, compute-gebundener Prozess, geleitet von Evaluation – wobei jeder Pfeil unten mit seinen relativen GPU-Kosten gewichtet ist:
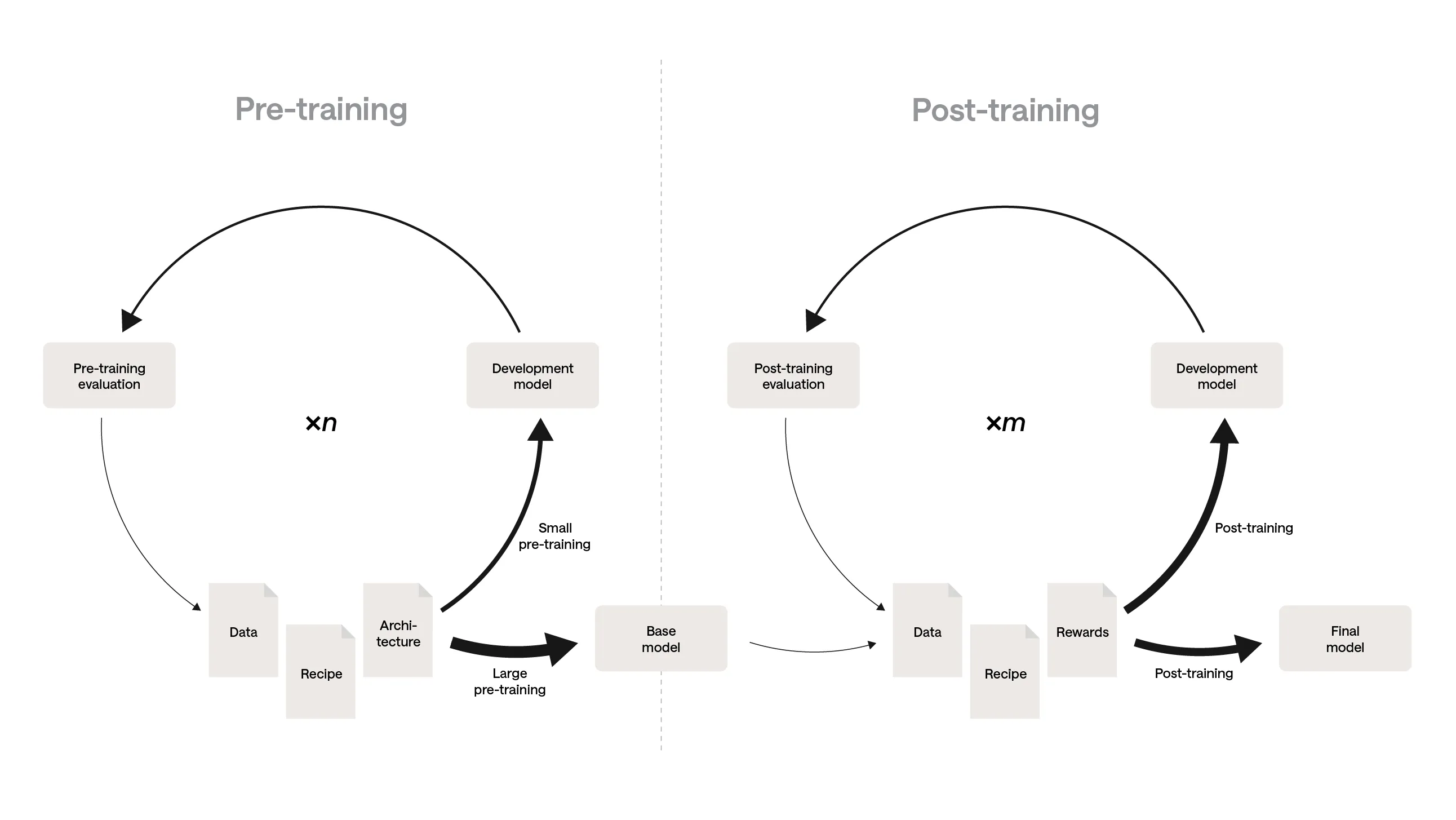
Jede dieser Komponenten ist komplex genug, um mehrere dedizierte Teams zu rechtfertigen. Modernes Post-Training besteht zum Beispiel aus einer Supervised-Fine-Tuning-(SFT)-Phase gefolgt von einer Reinforcement-Learning-(RL)-Phase. SFT und RL erfordern unterschiedliche Skillsets und Werkzeuge, müssen aber integriert werden, um ein Modell zu trainieren.
Stell dir vor, wie die Reise eines einzigen Modells durch die Pipeline in einem manuellen Lab aussehen könnte:
Das Daten-Team finalisiert eine neue Mischung und schickt den Datenbankpfad per Slack ans
Pre-Training-Team, das einen mehrwöchigen Lauf startet. Zwei Wochen später läuft das
Speicher-Quota voll und der Trainingslauf crasht. Das Dateisystem wird manuell verwaltet,
also ist sich niemand sicher, ob es sicher ist, dieses 30TB-Dataset mit
do_not_delete im Dateinamen zu löschen – und die GPUs stehen leer, während das Pre-Training-Team
das klärt. Beim Neustart rekonstruieren sie das ursprüngliche Setup aus dem Gedächtnis und aus
Slack-Threads und hoffen, dass sie kein Flag vergessen haben. Das sind die ersten versteckten Kosten: Jeder manuelle Schritt ist eine Gelegenheit für
menschliche Fehler.
Wenn Pre-Training schließlich fertig ist, übergibt das Pre-Training-Team den Checkpoint ans SFT-Team. Um eine gute Rezeptur zu finden, startet das SFT-Team manuell einen Sweep paralleler Trainings mit verschiedenen Konfigurationen und Datenmischungen. Während die Checkpoints reinkommen, lässt das Team sein Evaluations-Skript auf jedem laufen und teilt Ergebnisse und Analysen in Slack. Manche Rezepturen sehen vielversprechend aus, andere nicht – sie wiederholen den Prozess ein paar Wochen lang, bis sie eine gute eingegrenzt haben. Ohne es zu merken, hat das Team einige Experimente wiederholt, die sie vor ein paar Monaten bereits für den vorherigen Pre-Training-Checkpoint abgeschlossen hatten.
Das sind die zweiten versteckten Kosten: Das Team vergisst seine Erkenntnisse. Es gibt kein dauerhaftes Protokoll des Reasonings hinter dem aktuellen Wert eines Hyperparameters, keine formale Verknüpfung zwischen einer Datenmischung und ihren konstituierenden Datensätzen und keine klare Attribution, die ein Modell mit der Trainings-Rezeptur verbindet, die es erzeugt hat. In einem manuellen Lab ist diese Lineage verstreut über Slack, das Dateisystem, einen Experiment-Manager und diverse Wiki-Seiten – und geht mit der Zeit leicht verloren.
Das SFT-Team übergibt seinen Checkpoint ans RL-Team, das einen Trainingslauf darauf aufsetzt. Das finale Modell schneidet schlecht ab. Ist die RL-Rezeptur auf den SFT-Checkpoint vom letzten Monat overfit, oder liegt das Problem im SFT-Checkpoint selbst? Nach zwei Wochen Debugging bestätigt das RL-Team: Letzteres. Keines der Teams kann die Phase des anderen ausführen, also hat jedes für seinen eigenen Pipeline-Abschnitt optimiert – statt für das Modell am Ende. Und weil Integration eine manuelle Übergabe ist, passiert sie selten und hinterlässt einen Monat an Divergenz, die jedes Mal aufgelöst werden muss. Das sind die dritten versteckten Kosten: Manuelle, seltene Übergaben fragmentieren die Verantwortung der Teams.
Es ist klar, dass manuelles Model Training nicht skaliert – und Automatisierung ist nicht das einzige fehlende Puzzleteil. Jede dieser versteckten Kosten entspringt dem gleichen zugrunde liegenden Problem: Die Pipeline lebt in den Köpfen des Teams statt in einem geteilten, dauerhaften Artefakt. Um zu skalieren, muss die Pipeline selbst etwas Greifbares sein, an dem Teams zusammenarbeiten können.
Vorstellung: Model Training als Code
Unsere Modell-Fabrik mit dem Codenamen Savanna bildet unsere gesamte Model-Training-Pipeline und unsere Prozesse in imperativem Code ab. Wir nennen das Model Training as Code (MTaC). So sieht eine einfache Savanna-Post-Training-Pipeline als Pseudocode aus:
async post_train(config: PostTrainConfig) -> PostTrainEvaluation:
sft_checkpoint = await sft(config.sft)
sft_eval = spawn evaluate(config.eval, sft_checkpoint)
rl_checkpoint = await rl(config.rl, sft_checkpoint)
rl_eval = spawn evaluate(config.eval, rl_checkpoint)
return PostTrainEvaluation(await sft_eval, await rl_eval)Indem du die Pipeline in Code hebst, gewinnst du drei Dinge: Composability, Consensus und Provenance.
- Composability: Composability entsteht dadurch, dass manuelle Schritte als Funktionen mit typisierten Inputs und Outputs ausgedrückt werden, um die du dann Abstraktionen bauen und zu einer End-to-End-Pipeline komponieren kannst, die per Knopfdruck läuft. Die Pipeline zu ändern wird so einfach wie eine Funktion zu bearbeiten, repetitive Arbeit wie das Evaluieren von Zwischen-Checkpoints lässt sich mit einer for-Schleife automatisieren, und Tests sind unkompliziert, weil du Teilmengen oder verkleinerte Varianten der Pipeline mit anderer Parametrisierung laufen lassen kannst.
- Consensus: Consensus entsteht durch Version Control. Der Main-Branch repräsentiert das kollektive beste Verständnis des Teams, wie ein Modell zu trainieren ist. Der Code enthält die vollständige Trainings-Rezeptur – es gibt kein Setup zu rekonstruieren und kein Flag zu vergessen, wenn du einen Trainingslauf startest.
- Provenance: Provenance entsteht durch Code-Kommentare und Commit-History. Diese kodieren die Erkenntnisse und Entscheidungen, die zu Main geführt haben. Vergangene Trainingsläufe bleiben reproduzierbar, weil der Code, der sie erzeugt hat, in einem Commit fixiert ist, den du auschecken und neu laufen lassen kannst.
Wenn jedes Team die gesamte Pipeline selbst starten kann, kann es die Phase jedes anderen Teams ausführen und am Modell als Ganzes iterieren – nicht nur an seinem eigenen Abschnitt. Labs zerlegen Model Training beim Skalieren typischerweise zeitlich, wobei jedes Team eine Phase der Pipeline besitzt. MTaC öffnet die Tür zu einer fähigkeitsbasierten Zerlegung, in der Teams stattdessen ein Modellverhalten wie Multilingualität end-to-end verantworten.
Wenig integrieren, oft integrieren
Mit der Pipeline in Code gelten Standard-Best-Practices der Code-Kollaboration – und um das
Maximum aus MTaC herauszuholen, musst du sie befolgen. Die wichtigste davon ist Trunk-Based
Development, bei dem Änderungen so früh wie möglich und in kleinen Inkrementen auf main landen, damit Teams frühestmöglich auf der Arbeit der anderen aufbauen und schnell scheitern
können, falls ein Ansatz falsch ist. Sammelst du Änderungen stattdessen in langlebigen Branches
an, zahlst du die gleiche Integrationsschuld wie zuvor.
Savanna nutzen
Savanna lebt in GitHub, wo die CI der Einstiegspunkt für Model Training ist. Du kannst diese
CI durch einen Push auf einen Branch oder manuell aus der GitHub-UI heraus starten. Unser
bestes Modell zu trainieren ist so einfach wie CI auf main zu triggern. Wir nutzen
CI auch auf Pull Requests, um die Pipeline mit einem kleinen End-to-End-Trainingslauf schnell
zu validieren. Das ist in unter 5 Minuten fertig, also fühlt sich der Beitrag zu Savanna nie langsam
an – und es gibt uns Vertrauen in unsere Änderungen. Um semantische Regressionen in unserer Pipeline
zu erkennen, fahren wir jede Nacht einen größeren End-to-End-Trainings-Testlauf, der unsere Trainings-Logik
validiert, indem er sicherstellt, dass das resultierende Modell eine messbare Verbesserung in
unserer Evaluation-Suite erzielt.
MTaC liefert Decision-Lineage über git blame, und Savanna erweitert das um
Artefakt-Lineage. Läufe sind hermetisch, und alle Nicht-Code-Artefakte (z.B. Daten, Modelle
und Tokenizer) sind unveränderlich und in einer Registry versioniert – du kannst also sicher
sein, jedes Mal dasselbe zu bekommen. Wenn du einen Lauf startest, sind die referenzierten
Artefakte, Trainings-Logs, Metriken und Evaluations-Ergebnisse alle mit diesem Lauf und dem
resultierenden Checkpoint verknüpft, sodass du Output leicht dem Input zuordnen kannst. Um
zu bestimmen, welche Modelle auf einem bestimmten Datensatz trainiert wurden, nutzt du den
Artefakt-Lineage-Graph, nicht die Slack-Suche.
Savanna macht Full-Scale-Runs einfach, aber das Weiterentwickeln dessen, wie diese Läufe aussehen, erfordert die Möglichkeit, jeden Aspekt der Pipeline experimentell zu modifizieren – sei das Daten, Hyperparameter, Pipeline-Schritte, Environments, Sharding-Topologien oder etwas anderes – und zwar in kleinerem Maßstab. In Savanna ist Experimentieren so einfach wie Änderungen auf einen Branch zu pushen und CI von dort zu starten. Wenn du einen neuen Datensatz ausprobieren willst, kannst du ihn zur Ablations-Trainings-Config hinzufügen und CI starten. Wenn die resultierenden Evals eine Verbesserung zeigen, kannst du die Änderung in Main mergen, damit sie Teil des nächsten Full-Scale-Runs wird.
Hyperparameter-Sweeps sind ebenfalls einfach. Da die Pipeline einfach eine Funktion ist, kannst du sie programmatisch mehrfach mit unterschiedlichen Parametrisierungen aufrufen. Unten zum Beispiel ein Experiment, um herauszufinden, welche SFT- und RL-Learning-Rates in der zuvor gezeigten Post-Training-Pipeline am besten funktionieren:
async post_training_learning_rate_experiment(config: PostTrainConfig) -> str:
post_train_runs = []
for sft_learning_rate in (1e-4, 1e-5):
for rl_learning_rate in (1e-4, 1e-5):
run_config = config
.with_sft_learning_rate(sft_learning_rate)
.with_rl_learning_rate(rl_learning_rate)
post_train_runs.append(spawn post_train(run_config))
post_train_evaluations = gather post_train_runs
experiment_report_url = create_report(post_train_evaluations)
return experiment_report_urlSavanna orchestriert dann den Sweep und fasst die End-Ergebnisse in einem Report zusammen, den du auswerten kannst. So sieht dieses Experiment in Savannas Workflow-Engine-UI aus:
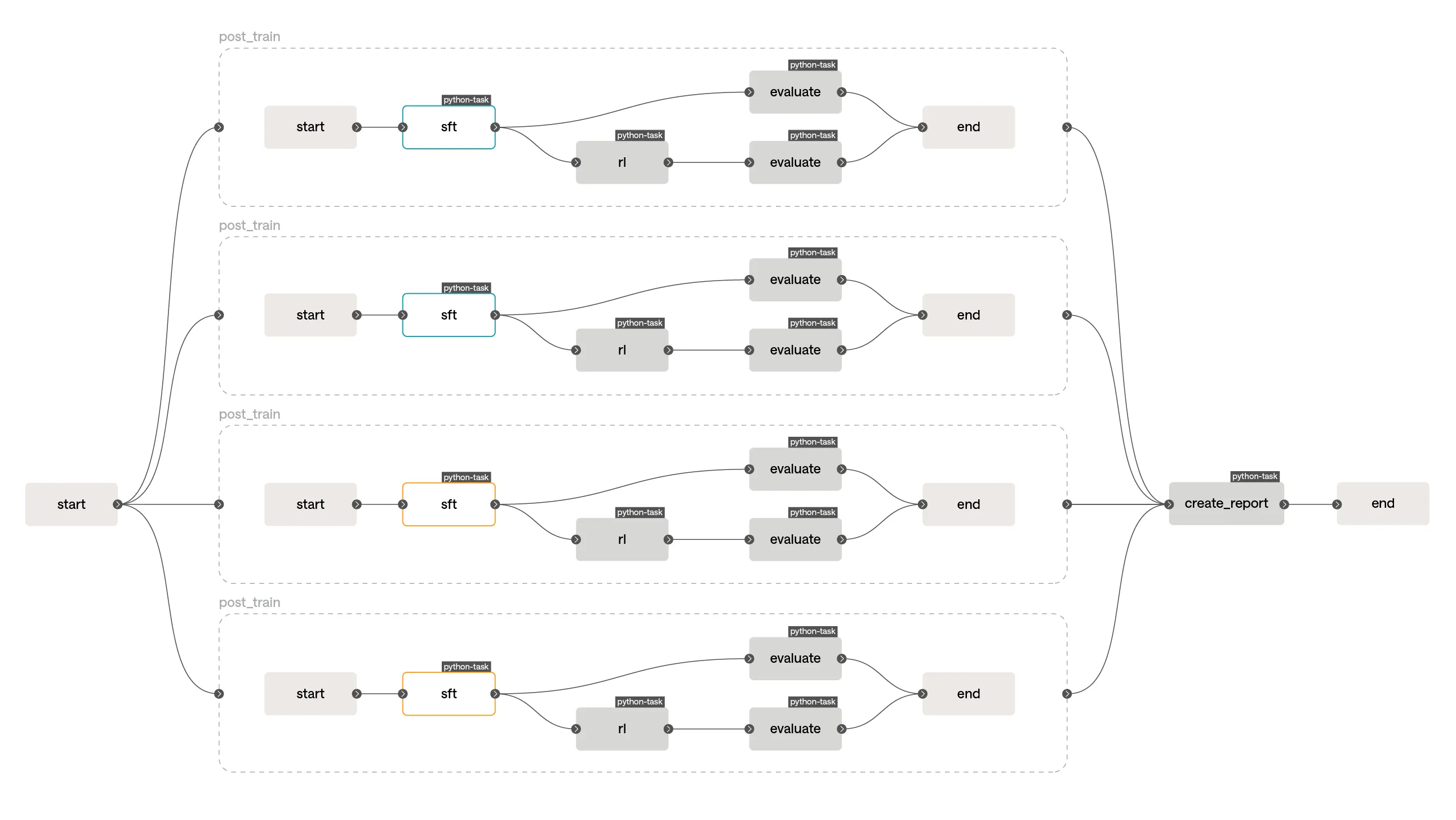
Blaue Knoten sind „running", orangene Knoten „awaiting cache". Obwohl wir
post_train viermal aufrufen, läuft die SFT-Phase nur zweimal: Savannas Workflow-Engine
erkennt, wenn Phasen dieselben Inputs haben, und liest deren Outputs aus dem Cache, sobald die
entsprechende laufende Phase fertig ist. So kannst du Sweeps starten, die mehrere Aspekte der
Pipeline gleichzeitig modifizieren, ohne dich um die kombinatorische Explosion redundanter Berechnung
sorgen zu müssen.
Für Pre-Training-Runs oder lange laufende RL-Jobs emittieren und evaluieren wir inkrementell Checkpoints, damit wir besser verstehen, wie sich unser Modell über das Training hinweg verändert. Nach dem Training evaluiert Savanna das Modell automatisch auf unserer Benchmark-Suite und sammelt alle Ergebnisse und Metriken in einem Run-Report. Savanna aktualisiert außerdem automatisch unser Modell-Leaderboard, das wir auf einem großen Bildschirm in unserem Heidelberger HQ zeigen, sodass alle die Freude teilen, wenn wir unser neues bestes Modell trainieren.

Wie Savanna funktioniert
Wenn du einen Lauf triggerst, startet Savanna einen Job auf Flyte, unserer Workflow-Engine der Wahl, die in Kubernetes läuft. Flyte bietet eine bequeme Möglichkeit, beliebige Tasks auszuführen – mit dauerhafter Ausführung, Sequenzierung, Parallelismus, Retries, Caching und einer UI zur Visualisierung von Läufen.
Wir speichern Modell- und Daten-Artefakte unveränderlich in unserem On-Prem-Object-Store und tracken ihre Versionen in Weights & Biases. Das erlaubt uns, Cleanup-Policies leicht zuzuweisen, damit unser Speicher-System aufgeräumt bleibt – und gibt uns eine UI, um Artefakt-Lineage interaktiv zu erkunden. Diese Daten streamen wir dann zu unseren Kubernetes-GPU-Clustern fürs Training. Während des Trainings loggen unsere Jobs Metriken in unser Monitoring-System, damit wir Fortschritt und Performance in Echtzeit verfolgen und Alerts senden können, falls ein Eingreifen nötig ist.
Wie hat Savanna uns tatsächlich geholfen?
Wir wissen, dass die Komplexität von Model Training nur wachsen wird, je weiter das Feld voranschreitet – und die organisatorischen Herausforderungen werden mitwachsen. MTaC hat es uns ermöglicht, diese organisatorische Komplexität in Code zu heben, was die Art, wie wir arbeiten, grundlegend verändert hat.
Tag für Tag iterieren wir schneller. Das meiste unserer Arbeit sind kleine Experimente und Sweeps, und Savanna automatisiert das manuelle Starten und Evaluieren, das diese früher erforderten. Dieser Aufwand fließt jetzt in die Analyse der Ergebnisse und das Design des nächsten Experiments.
Bei einem einzelnen großen Run liegen die Karten anders. Während unseres jüngsten großen Pre-Training-Runs haben wir das Training mehrfach fortgesetzt, um unser Setup nachzuziehen, während wir durch unsere automatisierten Zwischen-Evals mehr darüber gelernt haben, wie sich das Modell verhält. Jeder Relaunch war schnell und risikoarm, weil der Consensus, den MTaC liefert, bedeutete, dass es kein Setup zu rekonstruieren und kein Flag zu vergessen gab. Und weil Relaunching einfach war, musste es nicht zweimal dieselbe Person sein – wer gerade verfügbar war, konnte sicher übernehmen.
Auf einer höheren Ebene hat MTaC uns erlaubt, mehrere fähigkeits-orientierte Post-Training-Teams aufzusetzen, die die Integration und Verbesserung eines Modellverhaltens end-to-end verantworten. Unser Multilingualitäts-Team zum Beispiel bringt dem Modell deutsche Sprache und Kultur bei, indem es die dafür nötigen SFT-Datensätze, RL-Environments und Evaluation-Suites baut.
Seit wir Savanna eingeführt und Engineering-Kultur angenommen haben, ist unsere Lernrate als Organisation deutlich gestiegen – und der Ansatz ist nur wertvoller geworden, je tiefer unsere Pipeline und je größer unsere Teams wurden.
Mit Blick weiter nach vorn sehen wir MTaC als Schlüssel-Enabler für Auto-Research. Mit unserer gesamten Pipeline in Code kann ein LLM-Agent sie autonom lesen, modifizieren und ausführen – und wir beginnen jetzt damit, das zu erkunden. Eines Tages hoffen wir, dass unser Modell sich über Savanna selbst verbessern kann.
Danksagungen
Geschrieben von Michael Barlow. Diese Arbeit spiegelt die gemeinsamen Anstrengungen vieler Mitwirkender bei Aleph Alpha Research wider, die Savanna zum Leben erweckt haben. Dank an Martin Reinhardt, Dominik Kellner und Jordan Sassoon für hilfreiches Feedback, das diesen Blog mitgestaltet hat, und an Paige Reddington und Noé Beckerle Vallejo, die ihn präsentabel gemacht haben.