
Aleph Alpha Blog
Pharia-1-LLM vorgestellt: transparent und compliant
Pharia-1-LLM-7B
Wir freuen uns, unsere neue Foundation-Modell-Familie anzukündigen – mit Pharia-1-LLM-7B-control und Pharia-1-LLM-7B-control-aligned – jetzt öffentlich verfügbar unter der Open Aleph License, die ausdrücklich nicht-kommerzielle Forschung und Bildungszwecke erlaubt. Pharia-1-LLM-7B-control ist darauf ausgelegt, prägnante, längengesteuerte Antworten zu liefern, die mit der Performance führender Open-Source-Modelle im 7B- bis 8B-Parameterbereich mithalten – und ist durch Training auf einem mehrsprachigen Basiskorpus kulturell und sprachlich für Deutsch, Französisch und Spanisch optimiert. Pharia-1-LLM-7B-control wird auf sorgfältig kuratierten Daten in Übereinstimmung mit geltenden EU- und nationalen Vorschriften – einschließlich Urheber- und Datenschutzrecht – trainiert. Mit verbesserter Token-Effizienz brilliert Pharia-1-LLM-7B-control in domänenspezifischen Anwendungen – besonders in Automotive- und Engineering-Branchen – und lässt sich an Nutzer:innenpräferenzen ausrichten. Damit eignet es sich für kritische Anwendungen ohne das Risiko von Shutdown-Verhalten. Es ist somit eine wertvolle Ergänzung der Community-Auswahl an Foundation-Modellen mit verfügbaren Weights. Pharia-1-LLM-7B-control-aligned wurde via Alignment-Methoden um zusätzliche Safety-Guardrails ergänzt.
Begleitend zur Model Card beschreibt dieser Blogpost detailliert unseren Ansatz zum Aufbau des Pharia-1-LLM-7B-control-Modells.
Datensatz
Details zu den Daten, mit denen Pharia-1-LLM-7B-control trainiert wurde, legen wir in der Model Card offen.
Modellarchitektur & Hyperparameter
Für unsere Wahl von Architektur und Hyperparametern haben wir mehrere Ablationen durchgeführt, die wir in diesem Abschnitt beschreiben. Sofern nicht anders erwähnt, wurden die Experimente auf einer Modellgröße von 1B Parametern durchgeführt. Ablationen wurden auf den Standard-Pre-Training-Benchmarks lambada, triviaqa, hellaswag, winogrande, webqs, arc und boolq evaluiert. Performance auf anderen Benchmarks blieb vernachlässigbar oder zeigte überwiegend Noise.
Hyperparameter-Schema & Skalierungsstrategie
Unser ursprünglicher Plan war, die Werte für Learning Rate, globalen Init-Std-Gain, Embedding-Multiplier und Output-Multiplier auf einem kleinen Proxy-Modell mit Hidden Size 256 und 27 Layern (passend zur Layer-Anzahl des Zielmodells) zu sweepen und sie dann gemäß den Regeln der Maximal Update Parametrization (MuP) auf die Ziel-Hidden-Size hochzuskalieren.
Wir haben diese Methode genutzt, um unsere Hyperparameter für die 1B-Ablationen zu finden, und haben einen kurzen 7B-Sanity-Check-Run gefahren, der positiv ausfiel.
Auf 7B-Skala stießen wir jedoch auf gravierende Trainings-Instabilitäten, sobald wir nur leicht von der ursprünglichen Config abwichen (z.B. den Datensatz oder die Sequenzlänge änderten).
Nicht alle Ursachen dieser Instabilitäten sind vollständig bekannt und verstanden, doch MuP scheint eine davon zu sein. Daher haben wir uns gegen den Einsatz für dieses Modelltraining entschieden. Inzwischen verstehen wir besser, wie MuP für Transformer funktioniert, und haben dieses Paper veröffentlicht, das eine leicht modifizierte und numerisch stabile Variante von MuP einführt.
Anstelle von MuP haben wir uns bei unseren Pre-Training-Runs auf Heuristiken verlassen. Wir haben dieselbe Learning Rate wie Llama 2 verwendet und für die Gewichte ein Standard-Initialisierungs-Schema.
GPT vs. Llama 2
Wir haben die klassische GPT-Transformer-Architektur mit der durch Llama 2 populär gewordenen Architektur verglichen. Die Unterschiede sind in der Tabelle unten aufgeführt. Für beide Architekturen haben wir RoPE-Positional-Embeddings eingesetzt. In diesem Setting performen beide Architekturen hinsichtlich Loss und Downstream-Scores sehr ähnlich. Bei den Benchmarks fiel ein Ausreißer auf – TriviaQA –, wo die GPT-Architektur deutlich besser abschnitt. Wir konnten dieses Verhalten auf 7B-Skala reproduzieren – wenn auch mit einer geringeren Zahl an Trainings-Iterationen – und sind zum Schluss gekommen, dass die Standard-GPT-Architektur einen leichten Vorteil hat. Daher haben wir uns für diese Architektur für die Pharia-1-LLM-7B-Modelle entschieden.
| Komponente | GPT | Llama 2 |
|---|---|---|
| Bias | True | False |
| Norm | Layernorm | RMS Norm |
| MLP | Standard FFN | SwiGLU |
Group-Query-Attention (GQA)
Mit dem Ziel, die Inferenz-Performance zu verbessern, haben wir Ablationen zum Einsatz von Group-Query-Attention durchgeführt. Zuerst haben wir untersucht, wie sich die Modellperformance bei weniger KV-Heads verändert. Da Modelle mit mehr Parametern bei gleichen Daten in der Regel besser performen, haben wir versucht, den Gesamt-Parameter-Count in unseren Experimenten für einen fairen Vergleich konstant zu halten. Das haben wir erreicht, indem wir zusätzliche Layer ergänzt haben, um entfernte KV-Parameter auszugleichen. Dabei unterschied sich der Parameter-Count der verglichenen Modelle um maximal 5% des Gesamt-Parameter-Counts. In dieser parameter-normalisierten Konstellation konnten wir bei weniger KV-Heads keine signifikante Verschlechterung beobachten.
Gleichzeitig haben wir bis zu einem KV-Q-Verhältnis von 1/8 deutliche Vorteile beim Speicherbedarf und erhöhten Durchsatz gemessen – darüber hinaus haben wir keine substanziellen Gewinne mehr festgestellt. Wir haben uns daher entschieden, Group-Query-Attention bei einem Verhältnis nicht weit von 1/8 zu nutzen, und sind für unser finales 7B-Modell auf 1/9 gegangen.
Rotary Base
Für bessere Long-Context-Fähigkeiten schlägt Code Llama eine größere Base von 1e6 für die Rotary-Embeddings vor. Wir haben untersucht, ob eine größere Base für das Pre-Training schädlich ist. Auf 1B-Skala ist das nicht der Fall – die Downstream-Scores sind sogar leicht besser als mit der Default-Base 1e4. Wir haben daher die größere Base 1e6 während des Pre-Trainings eingesetzt.
Tokenizer
Wir haben eine Familie von Tokenizern mit unterschiedlichen Vokabulargrößen (64k, 96k,
128k, 160k, 192k) und Trainings-Algorithmen (BPE und Unigram) trainiert. Für beide
Algorithmen haben wir die SentencePiece-Bibliothek verwendet. Für das Trainings-Set haben
wir unseren High-Quality-Datensatz subgesampelt. Mit jedem Tokenizer haben wir ein 1B-Modell
trainiert und dabei nur die Embedding- und Head-Dimensionen verändert. Jedes Modell wurde
auf 380B Tokens bei einer Token-Batchgröße von 2M trainiert. Auf Downstream-Tasks wurde BPE
meist von Unigram übertroffen. Bei der Vokabulargröße haben wir bis 128k eine
Score-Verbesserung beobachtet, danach erreichte die Performance ein Plateau. Wir haben daher
einen Unigram-Tokenizer mit 128k Vokabulargröße als finalen Tokenizer gewählt.
Parallel
zu diesen etablierten Tokenisierungs-Verbesserungen haben wir ein innovativeres Arbeitsfeld
gestartet: „tokenizer-frei“, das wir für zukünftige Modell-Releases weiter erforschen.
Weight Decay & Dropout
Bei sorgfältiger Datenvorverarbeitung gibt es im Large-Scale-Pre-Training keine wiederholten Trainings-Samples. Damit besteht kein echtes Potenzial für Overfitting, und Regularisierungs-Techniken sind weniger wichtig. Aus diesem Grund haben wir a priori entschieden, kein Dropout zu verwenden. Bei Weight Decay legen Literatur und Erfahrungswerte nahe, dass ein Wert ungleich null das Training mit AdamW stabilisieren und in Pre-Training-Szenarien zu besserer Konvergenz führen kann. Um das zu prüfen, haben wir drei Werte für Weight Decay – 0, 1e-2 und 1e-1 – evaluiert und bestätigt, dass 1e-1 auf 1B-Skala zu den besten Downstream-Scores führt. Wir haben uns daher für diesen Wert entschieden.
Learning-Rate-Decay
Wir haben den Decay-Schedule kurz erneut betrachtet (mit konstantem Cosine-Decay-Stil) und Decay auf 0 vs. 10% der Learning Rate verglichen. Decay auf 0 führte zu leicht besseren Downstream-Scores, also haben wir diesen Wert gewählt. Wir erkennen an, dass das wohl ein komplexeres Thema ist, das auch mit Fragen zu Data-Mix und Daten-Curriculum verwoben ist. Eine umfassende Untersuchung in diese Richtung lag außerhalb des Scopes für dieses Modelltraining.
| Pharia-1-LLM-7B-control, Pharia-1-LLM-7B-control-aligned | |
|---|---|
| Anzahl Layer | 27 |
| Anzahl Attention-Heads | 36 |
| Head-Size | 128 |
| Anzahl Key-Value-Heads | 4 |
| Hidden Size | 4608 |
| MLP-Expansion-Factor | 4 |
| MLP-Typ | Standard |
| Vokabulargröße | 128.000 |
| Rotary Base | 1.000.000 |
| Dropout | 0 |
| Weight Decay | 0,1 |
| Learning-Rate-Schedule | Warmup: linear über 2000 Steps · Max-Wert: 3,0e-4 · Decay: Cosine auf 0,0 |
| Gesamt-Parameter-Count | 7.041.544.704 |
Pre-Training
Das Training unseres Pharia-1-LLM-7B-Basismodells erfolgte mit unserer Scaling-Codebasis, die wir parallel zu den Modellen veröffentlichen. Wir haben die Parallelisierungs- und Performance-Optimierungen von Scaling genutzt: Wir haben das bfloat16-Format eingesetzt und mit einer Standard-Mixed-Precision-Strategie trainiert – eine Master-Kopie der Gewichte sowie die Optimizer-States haben wir in voller Präzision gehalten. Die Full-Precision-Tensoren haben wir über die datenparallelen Worker geshardet (ZeRO Stage 1).
Wir haben das Pre-Training bei einer Sequenzlänge von 8192 Tokens durchgeführt, um in der Pre-Training-Phase angemessene Baseline-Fähigkeiten im Long Context zu erreichen. Beachte: Long-Context-Anpassungen folgen in späteren Iterationen der Modellfamilie. Bei den Experimenten zur Hochskalierung der Sequenzlänge haben wir früh im Training Instabilitäten beobachtet. Daher haben wir eine Sequenzlängen-Warm-up-Strategie eingesetzt und die Sequenzlänge von 512 auf 2048 und dann auf das Ziel 8192 über einige Tausend Steps skaliert. Der genaue Schedule wurde ad hoc gewählt. Wir haben mit einer globalen Batchgröße von 1024 über insgesamt 4,7 T Tokens trainiert – eine einzelne Epoche unseres ersten Pre-Training-Datenteils.
Nach Abschluss des initialen Pre-Trainings haben wir entschieden, eine weitere Epoche auf einem anderen Daten-Mix zu trainieren – und dabei zusätzliche Daten zu nutzen, die uns in dieser späteren Modell-Entwicklungs-Phase zur Verfügung standen. Wir haben Experimente mit unterschiedlichen Daten-Mixes gefahren, in dem Versuch, die neu verfügbaren hochwertigen englischen Daten stärker einzubinden – aber sicherzustellen, dass das Modell seine Mehrsprach-Performance behält, indem wir nicht-englische Daten aus unserem ersten Pre-Training-Schritt mit hineinmischen.
Wir haben das Pharia-1-LLM-7B-Basismodell für eine einzige Epoche des zweiten Daten-Mixes weitere 3T Tokens trainiert. Da die Learning Rate nach dem ersten Pre-Training auf 0 abgefallen war, haben wir eine weitere Warm-up-Phase von 2000 Iterationen auf eine Learning Rate von 3e-5 durchgeführt – also 10% unserer ursprünglichen maximalen Learning Rate – und diesen Wert während des Trainings nach einem Cosine-Schedule auf 3e-6 abklingen lassen.
Mit beiden Pre-Training-Phasen wurde das Pharia-1-LLM-7B-Basismodell auf insgesamt 7,7T Tokens trainiert.
Wir haben 256 A100-GPUs für das Training auf unserem ersten Daten-Mix und 256 H100-GPUs für das Training auf dem zweiten Daten-Mix eingesetzt. Das Layout des Modells wurde auf Durchsatz optimiert.
| Modell | GPUs | Pipeline-parallel size | Model-parallel size | Data-parallel size | Batch size | Micro-batch size |
|---|---|---|---|---|---|---|
| Pharia-1-LLM-7B | 256 | 2 | 1 | 128 | 1024 | 1 |
Wir haben kein Activation-Checkpointing eingesetzt, weil andere Memory-Reduktions-Techniken (PP, kleine Micro-Batch-Size) bei uns zu besserem Durchsatz geführt haben.
Insgesamt haben wir folgende Step-Dauern und durchschnittliche MFU erreicht:
| Modellname | Ø Step-Dauer | Ø MFU |
|---|---|---|
| Pharia-1-LLM-7B | 8,6s (A100) · 3,6s (H100) | 0,66 (A100) · 0,5 (H100) |
Die Pre-Training-Loss-Kurven für die beiden Trainings-Phasen des Pharia-1-LLM-7B-Basismodells sind in den folgenden Abbildungen dargestellt. Sie zeigen einen Rolling-Median über den Per-Batch-Trainings-Loss mit einer Fenstergröße von 200 Steps. Der Einbruch des Loss bei rund 350k Steps ist die Folge einer Ad-hoc-Reduktion der Learning Rate.
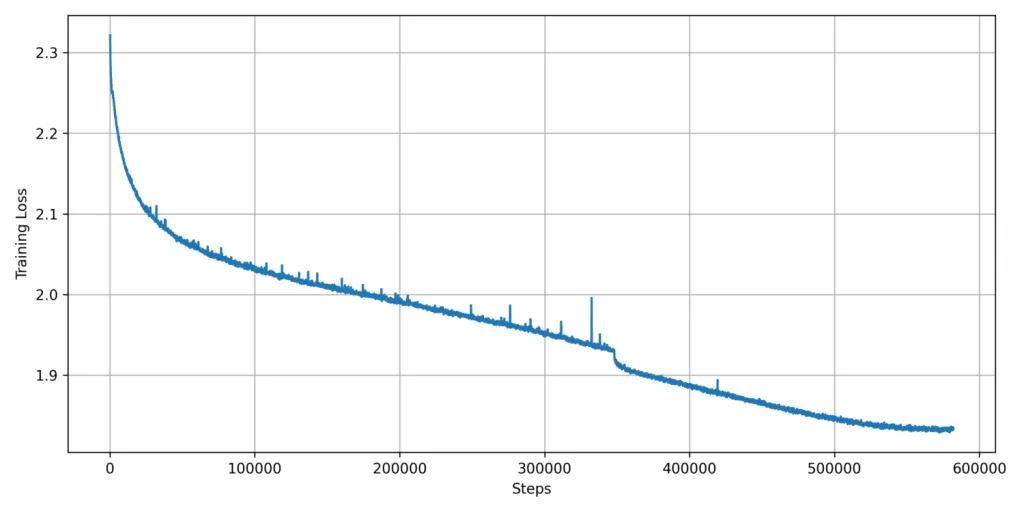
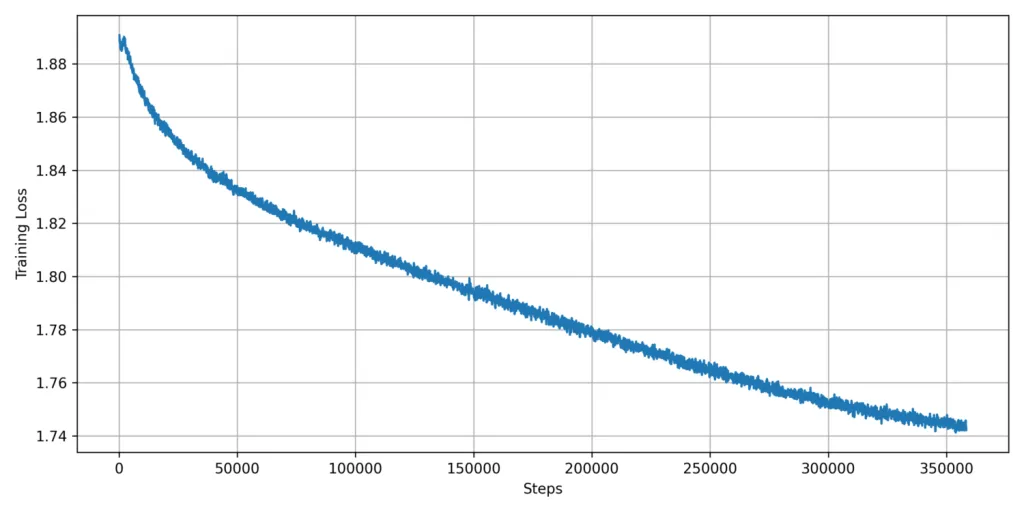
Fine-Tuning
Wir haben Pharia-1-LLM-7B-control für Instruction-Following mit einem Full-Model-Fine-Tuning-Ansatz optimiert. Wir haben mit einer Curriculum-Strategie trainiert: Das Modell wurde zunächst auf einer Mischung von Instruction-Datensätzen trainiert – einschließlich source-available, selbst erstellten und beschafften proprietären Datensätzen. Für optimale Performance über Sprachen hinweg haben wir Fine-Tuning-Daten für Englisch, Deutsch, Spanisch und Französisch berücksichtigt. Die Instruktionen umfassten sowohl Multi-Turn- als auch Single-Turn-Interaktionen. Um die Daten auf das absolute Minimum zu beschränken, das nötig ist, um performante Modelle zu trainieren, wurden alle Metadaten (z.B. EXIF) sowie andere potenziell personalisierbare Informationen zu den Personen, die die Daten erstellt haben, früh in unserer Datenpipeline entfernt.
| Pharia-1-LLM-7B-control | |
|---|---|
| Learning-Rate-Schedule | Warmup: linear über 100 Steps · Max-Wert: 1,0e-6 · Decay: Cosine auf 5e-09 |
| Batch Size | 256 |
| Train Steps (Anzahl Epochen) | 12500 (~ 5) |
| Datensatzgröße | ~ 640.000 |
Das resultierende Modell wurde weiter mit einer Curriculum-Strategie feinabgestimmt – mit schwierigeren Instruktionen am Ende des Trainings. Hier haben wir eine Mischung aus hochwertigen proprietären Datensätzen ausschließlich auf Englisch verwendet.
| Pharia-1-LLM-7B-control | |
|---|---|
| Learning-Rate-Schedule | Warmup: linear über 100 Steps · Max-Wert: 5,0e-7 · Decay: Cosine auf 5e-09 |
| Batch Size | 8 |
| Train Steps (Anzahl Epochen) | 1200 (3) |
| Datensatzgröße | 3.200 |
Die für das Instruction-Fine-Tuning verwendeten Daten enthalten source-available, kommerziell nutzbare Datensätze sowie selbst erstellte und beschaffte proprietäre Datensätze.
Im Rahmen unseres anstehenden Model-Suite-Releases stellen wir zwei verschiedene Varianten des 7B-Modells vor.
Pharia-1-LLM-7B-control-aligned ist ein Instruction-getuntes Modell, das zusätzlich durch menschliche und LLM-Präferenzen verfeinert wurde. Im Alignment-Prozess haben wir KTO mit einer Learning Rate von 1e-6 und einem Beta-Parameter von 0,1 eingesetzt. Im ersten Training haben wir beobachtet, dass das Modell teilweise Repetitions produzierte. Um das zu adressieren, haben wir generierte Samples mit Repetitions herausgefiltert und sie als negative Präferenzen in den Daten-Mix aufgenommen. Zusätzlich haben wir einen Safety-Datensatz eingebunden, der dem Modell hilft, unsichere Prompts abzulehnen, indem sichere Antworten als positive Beispiele und unsichere Antworten des Pharia-1-LLM-7B-control-Modells als negative Beispiele behandelt werden.
Pharia-1-LLM-7B-control ist das Instruction-getunte Modell ohne Präferenz-Alignment. Diese Variante hat kein zusätzliches Safety-Training durchlaufen. Wir haben festgestellt, dass der KTO-Schritt das Modell wortreichere, generischere Antworten produzieren ließ. Das KTO-alignte Modell reagierte zudem weniger gut auf spezifische Instruktionen wie das Einhalten einer gewünschten Output-Länge – auch wenn es in gängigen Instruction-Tuning-Benchmarks verbesserte Scores zeigte. Wir glauben, das liegt am zunehmenden Einsatz synthetischer Daten in den Datensätzen und der Tendenz von LLM-basierten Evaluationsmethoden, Wortreichtum zu bevorzugen.
Das Pharia-1-LLM-7B-control-aligned-Modell mit seinem Präferenz-Alignment und Safety-Training eignet sich gut für konversationelle Use-Cases, in denen Klarheit, Sicherheit und die Einhaltung der Nutzer:innen-Intention entscheidend sind. Seine verfeinerten Antworten machen es ideal für interaktive Anwendungen wie Chatbots oder virtuelle Assistenten. Auf der anderen Seite glänzt Pharia-1-LLM-7B-control ohne das zusätzliche Alignment bei Aufgaben wie Extraktion und Zusammenfassung, bei denen oft direktere und weniger wortreiche Outputs bevorzugt werden.
Evaluation
Evaluation in Generative AI (GenAI) ist aufgrund der mehrdeutigen Natur von Sprache von Haus aus komplex. Anders als in anderen KI-Bereichen, in denen Aufgaben klar definierte Metriken haben, ist Sprache subjektiv und offen für mehrere Interpretationen. Das macht es schwer, standardisierte Evaluationsmetriken zu erstellen, die die Performance von GenAI-Modellen zuverlässig beurteilen. Mehrdeutigkeit in Sprache bedeutet, dass derselbe Output je nach Kontext oder Bewertungsmethode unterschiedlich bewertet werden kann – das macht den Evaluationsprozess, insbesondere automatisiert, alles andere als trivial. Selbst bei klaren Evaluationskriterien zeigt sich, dass menschliche Annotator:innen Bestimmtheit und Länge stärker gewichten als Faktentreue und Wahrhaftigkeit.
Evaluationen leiden zudem an mehreren Schwächen, die sich auf Training und Architektur der
Modelle zurückführen lassen und zu mangelnder Robustheit von Evaluations-Scores führen. Die
Performance eines Modells hängt oft stark von kleinsten Implementierungsdetails ab. Dazu
zählen Details zur Komposition des Prompts, zur Reihenfolge der Antworten und zum
Positions-Bias des Modells, der Bias durch Few-Shot-Beispiele, die Wahl der
Evaluationsmetrik und sogar Details der Inferenz-Engine. Alzahrani, Alyahya et al. zeigen z.B., dass eine Änderung der Reihenfolge der Antwortoptionen im MMLU-Benchmark zu einem
signifikanten Genauigkeitsabfall von bis zu 8 Prozentpunkten führen kann.
Beim
Vergleich von Evaluations-Scores mit Ergebnissen anderer Modelle sollte man zudem bedenken,
dass Evaluationsdaten in manchen Fällen in die Pre-Training- oder sogar Fine-Tuning-Daten
gesickert sein können, sodass Modelle auf zuvor gesehene Beispiele overfitten. Hinweise
darauf liefern Zhang et al.,, die einen Datensatz erstellt haben, der Komplexität und Stil des populären
GSM8K-Benchmarks spiegelt – und festgestellt haben, dass einige Modelle auf ihrem Datensatz
bis zu 13 Prozentpunkte schlechter abschneiden als auf GSM8K. Dieses Maß an Noise macht ein
echtes Urteil über die Eignung eines Modells inhärent schwierig.
Außerdem sind Aufgaben in GenAI oft schlecht definiert oder nicht repräsentativ für Real-World-Szenarien. Viele bestehende Evaluationsaufgaben für GenAI bilden die Komplexität und Variabilität realer Use-Cases nicht angemessen ab. Diese Diskrepanz zwischen Testfällen und tatsächlichen Anwendungen führt dazu, dass Modelle nach Kriterien bewertet werden, die beim Einsatz in Real-World-Szenarien möglicherweise gar nicht relevant sind. Die Performance auf diesen Aufgaben sagt also nicht zwingend etwas über die Nützlichkeit eines Modells in praktischen Anwendungen aus. In der folgenden Tabelle geben wir je ein Beispiel aus MMLU und Alpaca Eval als typische Diskrepanzen zwischen Benchmark-Evaluations-Aufgaben und entsprechenden Real-World-Use-Cases:
| LLM-Use-Case | Beispiel-Evaluations-Task | Quelle des Beispiel-Tasks | Pendant in einem realen Use-Case | Erläuterung |
|---|---|---|---|---|
| Domänenspezifisches logisches Schließen | Which statement best explains the purpose of Hart's distinction between 'being obliged' and 'having an obligation'? Output is expected to be one of: 'It demonstrates the difference between the internal and the external aspect of a rule.', 'It refutes the natural lawyer view of the role of morality in law', 'It explains the nature of power-conferring rules.', 'It illuminates the concept of a rule.' | MMLU | You are given a legal text and a contract closed between (party_a) and (party_b). Reason step by step to determine whether the contract actually fulfills the requirements stated in the legal text. Legal text: (legal_text); Contract: (contract) | Domänenspezifische Reasoning-Aufgaben stützen sich oft auf Weltwissen, das das Modell beim Training erworben hat. In der Praxis wollen Anwendungen aber immer einen oder mehrere Kontexte einspeisen, um das Reasoning zu fundieren und Halluzinationsrisiken zu reduzieren. Solche Evaluations-Beispiele sind aber schwer zu bekommen: Sie stützen sich oft auf proprietäre Daten (z.B. Verträge), die Branchen schützen. Selbst wenn solche Daten verfügbar sind, ist tiefes Domänenwissen notwendig, um saubere, nützliche Instruktions-Szenarien zu konstruieren. Das ist meist ein Haupt-Kostenfaktor bei Datenerstellung und -beschaffung. Die Evaluation ist ressourcenintensiv, weil der Output nur durch Domänenexpert:innen verifiziert werden kann. Ein LLM als Judge reicht in solchen Fällen nicht aus. |
| Summarization | Summarize the article you have been given in a brief manner. Mathematics and art are related in a variety of ways. [...] | Alpaca Eval | (document); Given the above document, write a summary which has no more than 3 sentences long that also satisfies the following constraints: (list_of_constraints) | Evaluations-Frameworks, die auf die Bewertung allgemeiner Instructability ausgelegt sind, neigen dazu, die Vielfalt an Anforderungen und Constraints zu ignorieren, die Nutzer:innen an die Completion stellen wollen. Hauptgründe: Schwierigkeit, an solche Fälle heranzukommen, weil entsprechende Anforderungen von den vorgebenden Organisationen geschützt sein können. Hohe Kosten für die Konstruktion solcher Samples. Komplexität, ein Evaluationskriterium festzulegen, das den erreichten Erfolg granular misst. Zusätzliche Komplexität und Kosten, um sauber zu bewerten, ob alle Anforderungen/Constraints tatsächlich erfüllt wurden. |
Selbst wenn Aufgaben klar definiert sind, sind die Kriterien für „gutes Modellverhalten“ kontextabhängig und oft unklar. In GenAI kann sich das, was einen „guten“ oder „korrekten“ Output ausmacht, je nach Use-Case oder Nutzererwartungen deutlich unterscheiden. Diese Kontextsensitivität erschwert es, einen allgemein akzeptierten Standard für Modellperformance zu etablieren. Folglich wird die Wahl eines geeigneten Datensatzes für die Evaluation zur kritischen Aufgabe – er muss Kontext und Ziele der geplanten Anwendung präzise abbilden. Außerdem wird die Sicherstellung der Datensatz-Qualität noch wichtiger: Schwächen im Datensatz – z.B. Biases, fehlende Diversität, Misalignment mit dem geplanten Use-Case, Fehler oder Samples, die ohne weiteren Kontext keinen Sinn ergeben – können zu irreführenden Evaluations-Ergebnissen führen und letztlich die Performance des Modells in Real-World-Szenarien begrenzen.
Das gilt besonders für das Benchmarking vortrainierter Modelle: Pre-Training-Benchmarks sollen die Fähigkeit eines Modells messen, Muster aus großen Datenmengen zu lernen. Sie spiegeln jedoch nicht wider, wie gut das Modell nach dem Fine-Tuning auf spezifischen Aufgaben performt – und sind unzuverlässige Indikatoren für die Performance fein abgestimmter Modelle. Fine-Tuning passt das Modell an die in Real-World-Szenarien erforderlichen Use-Cases an, und sein Erfolg hängt stark von aufgaben- und domänenspezifischen Daten und Zielen ab.
Pharia-1-7B-control und Pharia-1-7B-control-aligned wurden gegen ähnlich große, weight-available mehrsprachige Modelle in mehreren Sprachen evaluiert – namentlich Mistrals Mistral-7B-Instruct-v0.3 und Metas llama-3.1-8b-instruct. Die Ergebnisse dieser Evaluationen findest du in der Model Card.