
Aleph Alpha Blog
Quality Diversity durch KI-Feedback
Sprachmodelle tragen implizite Verteilungs-Biases aus ihren Trainingsdaten, die bestehende Normen verstärken können.
Sieh dir unser aktuelles Update zu dieser Arbeit hier an.
Eine bearbeitete Fassung des QDAIF-Blogposts, ursprünglich veröffentlicht hier in Zusammenarbeit mit CarperAI und StabilityAI.
In dieser Arbeit machen wir einen Schritt in Richtung Bewältigung unerwünschter Biases,
indem wir Sprachmodelle dazu befähigen, Outputs mit einem breiteren Spektrum von
Attributmerkmalen zu erzeugen, die von Nutzer:innen vorgegeben werden. Das gelingt, indem
wir Sprachmodelle ihre eigenen Outputs bewerten und modifizieren lassen.
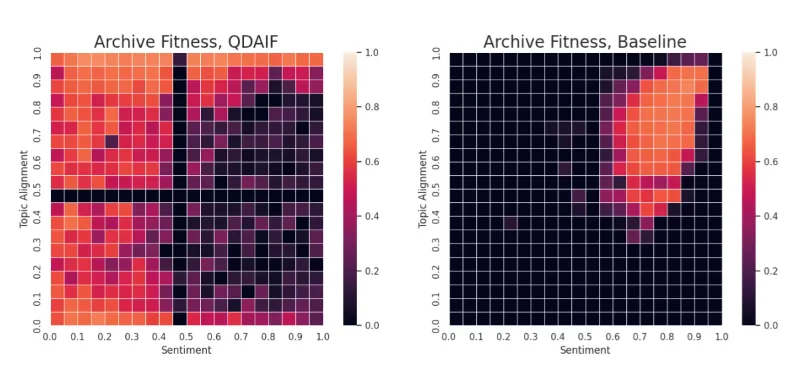
Abbildung 1: QDAIF erhöht die Diversität generierter Outputs über nutzerseitig spezifizierte Merkmale. Maps zeigen die höchste Qualitätsbewertung pro Nische im spezifizierten Merkmalsraum (Sentiment vs. Themenausrichtung). Links: mit QDAIF. Rechts: ohne QDAIF. Die Attribut- und Qualitätsmetriken werden von unseren Luminous-Modellen bewertet. Schwarze Zellen sind ungefüllt. Das QDAIF-Sampling (links) startet von Zero-Shot-Film-Reviews, während die Baseline (rechts) von handgeschriebenen Film-Reviews ausgeht. Die Anzahl der Inferenzschritte ist für beide auf 2000 fixiert.
Einführung
Sprachmodelle tragen implizite Verteilungs-Biases aus ihren Trainingsdaten, die bestehende Normen verstärken können. In dieser Arbeit machen wir einen Schritt in Richtung Bewältigung unerwünschter Biases, indem wir Sprachmodelle dazu befähigen, Outputs mit einem breiteren Spektrum von Attributmerkmalen zu erzeugen, die von Nutzer:innen vorgegeben werden. Das gelingt, indem wir Sprachmodelle ihre eigenen Outputs bewerten und modifizieren lassen.
Wir freuen uns, eine vielseitige Methode vorzustellen: „Quality Diversity through AI Feedback“ (QDAIF). Sie erlaubt Nutzer:innen, ein breites Spektrum hochwertiger, kreativer Inhalte aus Sprachmodellen zu samplen. Durch unsere Kollaboration (mit Pionier:innen im Bereich der Open-Ended-AI) wurden Luminous-Modelle erfolgreich in eine Output-Sampling-Pipeline integriert, die Texte in Domänen wie Filmrezensionen und Kurzgeschichten verfeinert. Ergebnisse mit unseren Modellen zeigen wir in unseren Experimenten zum Schreiben von Filmrezensionen. Qualitative Beschreibungen von Outputs unserer QDAIF-Pipeline in Film- und Kurzgeschichten-Schreiben findest du im ergänzenden Material des Blogs.
Quality Diversity durch KI-Feedback
QDAIF ist als Design von drei zentralen Forschungssträngen inspiriert: Quality-Diversity-Algorithmen (QD), Evolution Through Large Models (ELM) und KI-Feedback.
Im Sinne evolutionärer Suche optimiert QD nicht auf eine einzelne Ziel-Lösung, sondern auf eine diverse Menge optimaler Lösungen (typischerweise für einen handcodierten Bereich von Attributmerkmalen). ELM und seine Folgearbeit, Language Model Crossover (LMX), nutzen gelernte Priors aus menschlichem Wissen, um Texte intelligent zu verfeinern – ob mathematische Ausdrücke, natürliche Sprache oder Python-Programme. LMX nutzt insbesondere In-Context-Learning aus Allzweck-Sprachmodellen und kann die Optimierung mit MAP-Elites – einem einfachen QD-Algorithmus – verbessern. OpenELM, eine aktive Open-Source-Bibliothek von CarperAI, ist auf ELM-Forschung zugeschnitten und wird auch von einigen unserer Forscher:innen mit Beiträgen unterstützt.
KI-Feedback ist ein komplementärer Forschungstrend, bei dem LMs nach Feedback zu Training, Evaluation oder Problemlösungsfähigkeiten anderer LMs gefragt werden. Constitutional AI nutzt LM-generierte Kritiken, Verfeinerungen und Präferenzen über Textvervollständigungen, um Modelle auf Hilfsbereitschaft und Harmlosigkeit zu finetunen. Es ist mittlerweile auch möglich, LMs ihre eigenen Outputs bewerten zu lassen – ausgehend davon, dass es einfacher ist, Text auf eine bestimmte Qualität zu bewerten, als Text dieser Qualität zu generieren. Self-refine folgt der Idee der iterativen Verfeinerung, um LM-Outputs für Dialog-Aufgaben zu verbessern.
QDAIF kombiniert Quality Diversity (QD), ELM und KI-Feedback, um die Kreativität von LMs zu erweitern. Wir spezifizieren zunächst Qualitäts- und Attributmerkmale und legen fest, wie wir ein LM dafür prompten. Dann wählen wir einen LM-basierten Variationsoperator und seeden den Algorithmus mit Anfangslösungen. Anschließend erstellen wir aus den Attributmerkmalen eine Map und starten eine MAP-Elites-Schleife:
- Erzeuge Nachkommen mit dem Sprachmodell-Variationsoperator.
- Bewerte Nachkommen anhand der KI-Feedback-Maße auf Qualität und Attributmerkmal.
- Ersetze die Lösung jeder Zelle in der Map durch die bessere.
Mit der Zeit füllt sich die Map mit diversen und qualitativ hochwertigen Lösungen. Das funktioniert ausschließlich auf Basis von KI-Feedback und macht handcodierte quantitative Qualitätsmaße oder Attributmerkmale überflüssig.
Für die in diesem Blog beschriebenen Experimente haben wir OpenELM eingesetzt.
Ergebnisse zum evolutionären Kreativ-Schreiben
Wir zeigen die Vielseitigkeit von QDAIF anhand von Demos im Film-Review- und Kurzgeschichten-Schreiben.
Filmrezensionen
Wir haben MAP-Elites auf eine Kreativ-Schreib-Umgebung angewendet, in der die Aufgabe darin besteht, Filmrezensionen für den späten 1980er-Actionfilm „Die Hard“ zu evolvieren. Qualität messen wir über die Kosinus-Ähnlichkeit zwischen den Embeddings eines Referenzstrings („Movie review for the film ‚Die Hard‘“) und der generierten Rezension – mit dem Luminous-Explore-13B-Embedding-Modell – als eine Art KI-Feedback darüber, ob der erzeugte Text eine realistische Rezension ist. Diversität untersuchen wir bzgl. des Sentiments/Attributs der erzeugten Rezension (z.B. wie positiv oder negativ sie ist), indem wir ein Instruction-tuned-Modell luminous-supreme-control prompten, das allgemeine Sentiment des Rezensionstextes zu bewerten, und einen Score aus Log-Wahrscheinlichkeiten von „positive“ und „negative“ berechnen.
Wir nutzen unsere Luminous-Modelle als Sprachmodell-Variationsoperator mit LMX-Crossover, wobei jeder Prompt aus mehreren Beispiel-Rezensionen in folgender Form besteht:
Here is a random example of a review for the movie „Die Hard“:
{review}\\n###\\n
Wir vergleichen unsere QDAIF-Ergebnisse mit einer einfachen Baseline, die Rezensionen einfach über einen festen, handgeschriebenen 3-Shot-Prompt sampelt. Anschließend messen wir Qualität und Diversität jeder Generation der Baseline auf dieselbe Weise, befüllen eine Map, berechnen QD-Scores (definiert als Summe der besten Lösungs-Fitness-Scores über alle Zellen der Map) und vergleichen mit QDAIF.
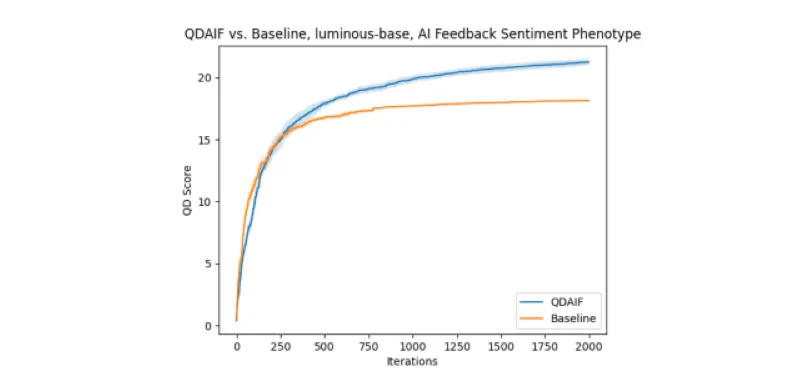
Abbildung 2: QD-Score-Verlauf vergleichbarer Läufe in der Domäne Film-Reviews. Mittelwert und Standardfehler sind je Setup über 5 Seeds gemessen.
Wir sehen deutliche Unterschiede im resultierenden Korpus generierter Rezensionen zwischen QDAIF und der Baseline. Erstens zeigt Abbildung 2, dass QDAIF den QD-Score der Map stärker verbessert als die Baseline – besonders bei mehr Evolutionsschritten. Zusätzlich zeigen wir oben einige interessante qualitative Ergebnisse aus den von QDAIF entdeckten Rezensionen, die die Optimierungsdynamik veranschaulichen. Subjektive Beschreibungen roher Beispiel-Rezensionen findest du im ergänzenden Material.
Interessanterweise sehen wir, dass die generierten Rezensionen in manchen Fällen konvergieren – sie werden dem Referenzstring zur Fitness-Definition („Movie review for the film ‚Die Hard‘“) ähnlicher, statt eine echte Rezension zu sein:
Bin-Index 19/20 (positives Sentiment), Iteration 500:
„This is review for the movie Die Hard.“
Das ist eine Form von Reward-Hacking, bei dem die Optimierung der Fitness-Funktion nicht mit dem eigentlichen Ziel übereinstimmt, Texte zu erzeugen, die realistischen Filmrezensionen ähneln.
Um zu untersuchen, wie sich unser Film-Review-Setup auf zusätzliche Diversitätsachsen verallgemeinert, haben wir auch Experimente mit zwei Diversitätsachsen gefahren – mit einer zusätzlichen Achse, die bewertet, ob die generierte Rezension sich auf Filmcharaktere konzentriert. Die Gesamtzahl der Nischen in der resultierenden Map ist deutlich höher als im 1D-Fall (400 vs. 50).
| Methode | QD-Score |
|---|---|
| Baseline | 41,97 ± 0,92 |
| QDAIF | 135,98 ± 7,06 |
Tabelle 1: QD-Score-Vergleich aus den am Ende der Suche erhaltenen 2D-Archiven. Mittelwert und Standardfehler sind je Setup über 5 Seeds gemessen. QDAIF übertrifft die Baseline deutlich beim Entdecken hochwertiger Samples über einen breiteren Raum entlang der Maße Sentiment und Rezensions-Themenausrichtung.
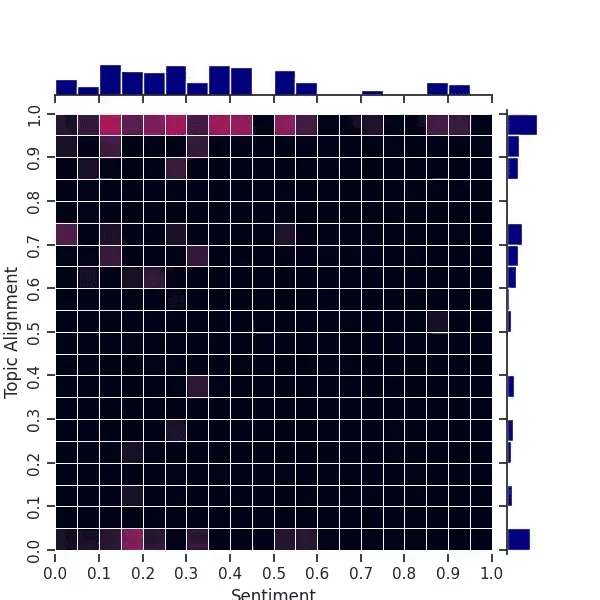
Abbildung 3: Eine Animation, wie sich die Fitness der Map im Verlauf der Zeit auf unserer 2D-Film-Review-Aufgabe verbessert. Das „Kreuz“-Muster in der Mitte ist ein Artefakt unserer Nutzung von KI-Feedback für Sentiment und Themenausrichtung. Das Archiv startet mit leeren schwarzen Bins.
Um Attribut-Feedback für diese neue Dimension zu erhalten, prompten wir das Instruction-Modell, zu bewerten, ob sich die Rezension auf Filmcharaktere konzentriert (Antwort entweder „yes“ oder „no“). Analog zum Review-Sentiment berechnen wir die normalisierte Wahrscheinlichkeit, eine Antwortoption (z.B. „yes“) für diesen Prompt vorherzusagen, um den Score zu ermitteln.
Die gesamte Map zu erkunden ist in diesem Fall schwieriger, weil die 2-dimensionale Map mehr Bins (400) hat. Dennoch zeigt die Animation in Abbildung 3, dass QDAIF mit MAP-Elites die Map weiterhin erfolgreich mit hochwertigen Beispielen füllt. Abbildung 1 und Tabelle 1 zeigen, wie QDAIF mehr hochwertige Film-Review-Nischen findet als eine reine Fitness-Optimierungs- Baseline, die nicht sinnvoll auf Diversität zwischen den Samples optimiert.
Kurzgeschichten
Um die Flexibilität von QDAIF zur Verfeinerung kreativer Texte zu zeigen, haben wir Läufe zur Evolution von Kurzgeschichten mit variierendem Sentiment durchgeführt. Aus Auszügen im ergänzenden Material zeigen wir Beispiele zur Aufgabe, Kurzgeschichten mit „einem misstrauischen Spion und einem reichen Politiker“ zu schreiben:
Bin-Index 2/20 (negatives Sentiment), Iteration 100:
„The political world was highly suspicious of the politician. He was well-known for his political maneuvering and for his questionable dealings. The government was always suspicious of his actions, but they knew that he was hard to catch. He was a very shrewd person and he knew how to quickly disappear from sight.“
Bin-Index 2/20 (negatives Sentiment), Iteration 400:
„The politician and the spy were waging war on each other. The politician had hired the spy to spy on the spy. The politician wanted to stay in office and make money. The spy was at the same time trying to get money out of the rich politician. The spy was also trying to get the politician arrested.“
Bin-Index 19/20 (positives Sentiment), Iteration 200:
„She was a rich politician, and I was a spy. She had a fortune, and knew it. I wanted to find out how she got her wealth, and whether or not she was hiding any dirty secrets. I was able to get some information about her in my investigation. I was about to find out some interesting information!“
Im ersten Beispiel fehlen Bezüge zum gewünschten Spion-Charakter. Trotzdem entdeckt eine spätere Iteration eine Kurzgeschichte, die der gewünschten Domäne stärker entspricht – mit wiederholten Bezügen zu beiden Charakteren. Phrasen wie „highly suspicious“ und „waging war“ in den ersten beiden Beispielen haben negative Konnotationen, während Phrasen wie „I was able to“ im dritten Beispiel wahrscheinlich eine positive Konnotation tragen. Auch hier sehen wir, dass QDAIF ein diverses Set kreativer Texte mit unterschiedlichen Sentiments aufdeckt und gleichzeitig die Fitness-Funktion nutzt, um Geschichten subjektiv interessant zu verfeinern.
Fazit
Quality Diversity durch KI-Feedback (QDAIF) ist als neue Methode gezeigt, die evolutionäre Suche nutzt, um LMs zu helfen, ihre eigenen Biases zu überwinden – und ihre Outputs erfolgreich verfeinert, sodass Samples über ein gewünschtes Spektrum von Attributmerkmalen entdeckt werden. Zusätzlich zur Verbesserung der LM-Baseline-Fähigkeiten halten wir es für möglich, QDAIF anzupassen, um Finetuning-Daten für LM-Self-Improvement zu erzeugen.
Wir planen, diese Arbeit zu einer Publikation weiterzuentwickeln – kommt bald! Ergänzendes Material zu diesem Post findest du hier.
Für Ergebnisse unserer Kollaborationspartner:innen zu QDAIF-Anwendungen im Bereich der Lyrik-Evolution empfehlen wir den Original-Blogpost.
Danksagungen
Wenn diese bearbeitete Fassung des Blogposts (mit zusätzlichen Ergebnissen von Aleph Alpha) nützlich für deine Arbeit war, zitiere bitte sowohl die Original- als auch die bearbeitete Version mit:
H. Bradley, A. Dai, J. Zhang, J. Clune, K. Stanley, J. Lehman. (May 2023). Quality Diversity through AI Feedback. CarperAI Blog. https://carper.ai/quality-diversity-through-ai-feedback/
A. Dai, R. Baldock, K. Oostermeijer, H. Teufel, M. Bellagente, H. Bradley, J. Zhang, J. Clune, K. Stanley, J. Lehman. (May 2023). Quality Diversity through AI Feedback. Aleph Alpha Blog Edit. /quality-diversity-through-ai-feedback
Diese Arbeit war eine Zusammenarbeit zwischen CarperAI, Stability AI und Aleph Alpha. Wir danken den Mitgliedern aus dem Aleph-Alpha-Research-Team, die zu den Experimenten und zur technischen Arbeit mit Aleph-Alpha-Modellen beigetragen haben:
- Koen Oostermeijer (Visualisierungen und Analyse)
- Marco Bellagente & Hannah Teufel (Beiträge und technischer Support für OpenELM)
- Souradeep Nanda & Jan Zierstek (allgemeines Feedback und Guidance)
Wir würdigen die Arbeit der Kollaborationspartner:innen in dieser Joint-Work:
- Herbie Bradley & Joel Lehman für die Leitung des gesamten QDAIF-Vorhabens
- Jenny Zhang, Jeff Clune & Kenneth Stanley für ihre Arbeit am Vorantreiben von QDAIF
Autor:innen: Andrew Dai, Robert Baldock*, Koen Oostermeijer*, Hannah Teufel*, Marco
Bellagente*, Herbie Bradley, Jenny Zhang, Jeff Clune, Kenneth Stanley, Joel Lehman
*Mitwirkung am Schreiben der Aleph-Alpha-Version des Blogposts