
Aleph Alpha Blog
T-Free: Hierarchische autoregressive Transformer für Sprach-Fairness und Souveränität
Ein Gamechanger für ressourcenarme Sprachen und Out-of-Distribution-Finetuning
Unser Ziel bei Aleph Alpha Research ist es, robuste und leistungsfähige Sprachmodelle zu bauen, die sich einfach und effizient an viele unterschiedliche Sprachen, Domänen und Use-Cases anpassen lassen. Ein Aspekt, der diese Anpassbarkeit behindert, ist der Einsatz von Tokenizern mit starren, vorab gefitteten Vokabularen. Deshalb arbeiten wir an vokabular-freien Sprachmodellen. Diese Forschungsrichtung fassen wir unter dem Namen „T-Free“ zusammen, der unser erstes peer-reviewtes Paper war, das wir vor etwa einem Jahr auf der EMNLP 2024 vorgestellt haben.
In diesem Blogpost schauen wir uns einen tokenizer-freien Ansatz genauer an, den wir in einem aktuellen Paper vorgeschlagen und Hierarchical Autoregressive Transformers (HAT) genannt haben. Wir zeigen insbesondere, wie ein solches Modell auf Englisch vortrainiert und effizient an das Lernen einer neuen, zuvor ungesehenen Sprache angepasst werden kann.
Unser HAT-Modell erreicht beim englischen Pre-Training und beim finnischen Continued Pre-Training vergleichbare Evaluationsergebnisse wie ein tokenizer-basiertes Modell – und ist während der Inferenz im Englischen 18% effizienter und im Finnischen 200% effizienter.
Subwort-Tokenizer und ihre Probleme
In der computergestützten Sprachmodellierung bezeichnet Tokenisierung den Prozess, einen Textabschnitt in Einheiten zu zerlegen, die ein Modell verarbeiten kann. Zwei grundlegende Ansätze sind Tokenisierung auf Zeichen-Ebene [Fußnote: Zeichen können sich auf unterschiedliche Basis-Alphabete beziehen. Eine gängige Wahl, die wir unten übernehmen, ist die Verwendung roher UTF-8-Bytes.] und auf Wort-Ebene. Während die zeichenweise Tokenisierung die „atomaren“ Einheiten von Text nutzt und sich über eine kleine Vokabulargröße freuen kann, führt sie zu langen Sequenzen mit hohen Rechen- und Speicherkosten. Umgekehrt führt wortweise Tokenisierung zu kurzen Sequenzen, leidet aber unter extrem großen Vokabularen und der Unfähigkeit, Out-of-Vocabulary-Wörter zu verarbeiten.
State-of-the-Art-Modelle nutzen sogenannte Subwort-Tokenizer, die als Kompromiss zwischen diesen beiden Extremen entstanden sind. Gängige Subwort-Tokenizer wie Byte Pair Encoding (BPE) werden auf einem Referenz-Textkorpus gefittet und bauen ein Subwort-Vokabular, das diesen Text optimal komprimiert. Ein gefitteter Subwort-Tokenizer ist im Grunde eine riesige Vokabular-Datei, gegen die ein Eingabetext gematcht wird, um eine Folge von Token-IDs zu erzeugen. Damit diese Sequenz in ein Modell gespeist werden kann, wird jedes Token über eine große Embedding-Lookup-Tabelle eingebettet. Dieser Prozess ist in Abbildung 1 veranschaulicht.
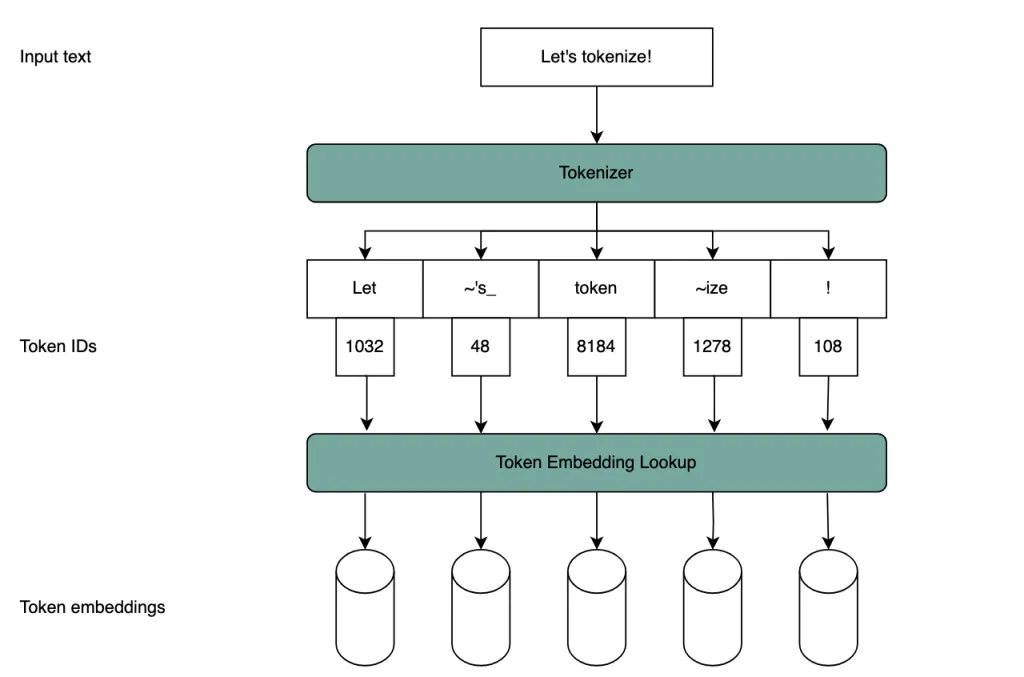
Abbildung 1: Schema tokenizer-basierter Modelleingaben. Der Tokenizer segmentiert den Text, indem er ihn gegen sein festes Vokabular matcht. Jedes Token hat eine eindeutige ID, mit der eine Embedding-Lookup-Tabelle abgefragt wird.
Subwort-Tokenizer haben jedoch mehrere Nachteile. Erstens nutzen aktuelle Modelle routinemäßig Vokabulargrößen von Hunderttausenden. Da die Embedding-Matrix und der Output-Head eines Modells mit der Vokabulargröße skalieren, werden Modelle extrem groß. Beim 8B-Modell der Llama-3-Familie mit einer Vokabulargröße von 128k machen diese Matrizen etwa 13% des Gesamt-Parameter-Footprints aus. Zweitens können Rechtschreibfehler oder Varianten zu drastisch unterschiedlichen Token-Sequenzen für semantisch nahe Eingaben führen und damit die Modellperformance verschlechtern.
Der wohl wichtigste Nachteil: Ein Tokenizer wird in einem separaten Schritt gefittet und ist nicht Teil des End-to-End-Lernprozesses des Modells. Das kann problematisch werden, wenn ein vortrainiertes Modell auf Text aus anderen Domänen oder Sprachen angewendet oder dort feinabgestimmt wird, auf die der Tokenizer nicht abgestimmt ist. Wendet man z.B. einen auf englischen Daten gefitteten Tokenizer auf eine neue Sprache an, wird er Schwierigkeiten haben, Text effizient und in semantisch sinnvollen Einheiten darzustellen. Eine Ausprägung davon ist die Kompressionsrate des Tokenizers – die durchschnittliche Anzahl an Text-Bytes, die er in ein einzelnes Token bündelt. Abbildung 1 zeigt dieses Phänomen am Beispiel von Englisch und Deutsch.
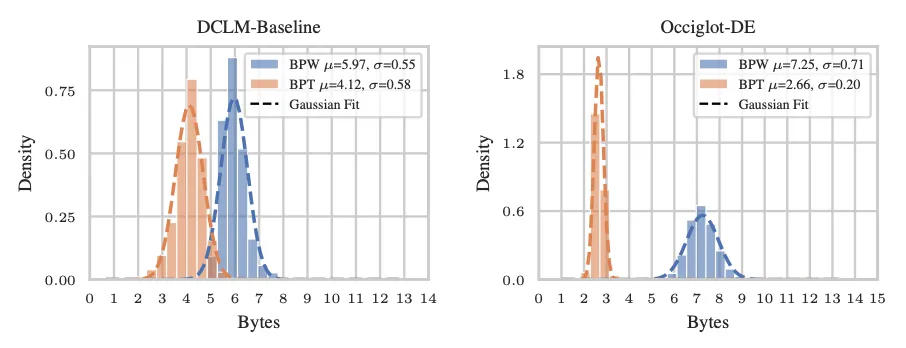
Abbildung 2: Bytes pro Wort (BPW) und Bytes pro Token (BPT) auf dem englischen DCLM-Baseline-Datensatz und dem deutschen Occiglot-DE-Datensatz. Während die Kompressionsrate des Tokenizers drastisch sinkt, steigt die durchschnittliche Anzahl Bytes pro Wort sogar an.
Hierarchical Autoregressive Transformers
Um diesen Mängeln zu begegnen, arbeitet Aleph Alpha Research an Modellen, die nicht auf separat gefittete Tokenizer angewiesen sind. Der hier vorgestellte Ansatz wurde Hierarchical Autoregressive Transformer (HAT) genannt und in einem aktuellen Paper präsentiert.
Hinweis: Tokenizer-freie Architekturen sind ein aktives Forschungsthema bei Aleph Alpha. Für die in diesem Blogpost gezeigten Experimente verwenden wir eine verbesserte Variante der im oben genannten Paper vorgeschlagenen Architektur.
Die Architektur des Hierarchical Autoregressive Transformers kombiniert Byte-Level- und Wort-Level-Verarbeitung. Wir teilen den Text zunächst nach einer einfachen Splitting-Regel in Wörter – wir orientieren uns an der Unicode-Standarddefinition eines Wortes. Die Bytes innerhalb jedes Wortes werden von einem kleinen Encoder-Modul verarbeitet, das sie auf ein Wort-Embedding abbildet. Die resultierende Sequenz von Wort-Embeddings wird dann von einem größeren Backbone-Modell verarbeitet. Dieser Prozess ist in Abbildung 3 veranschaulicht.
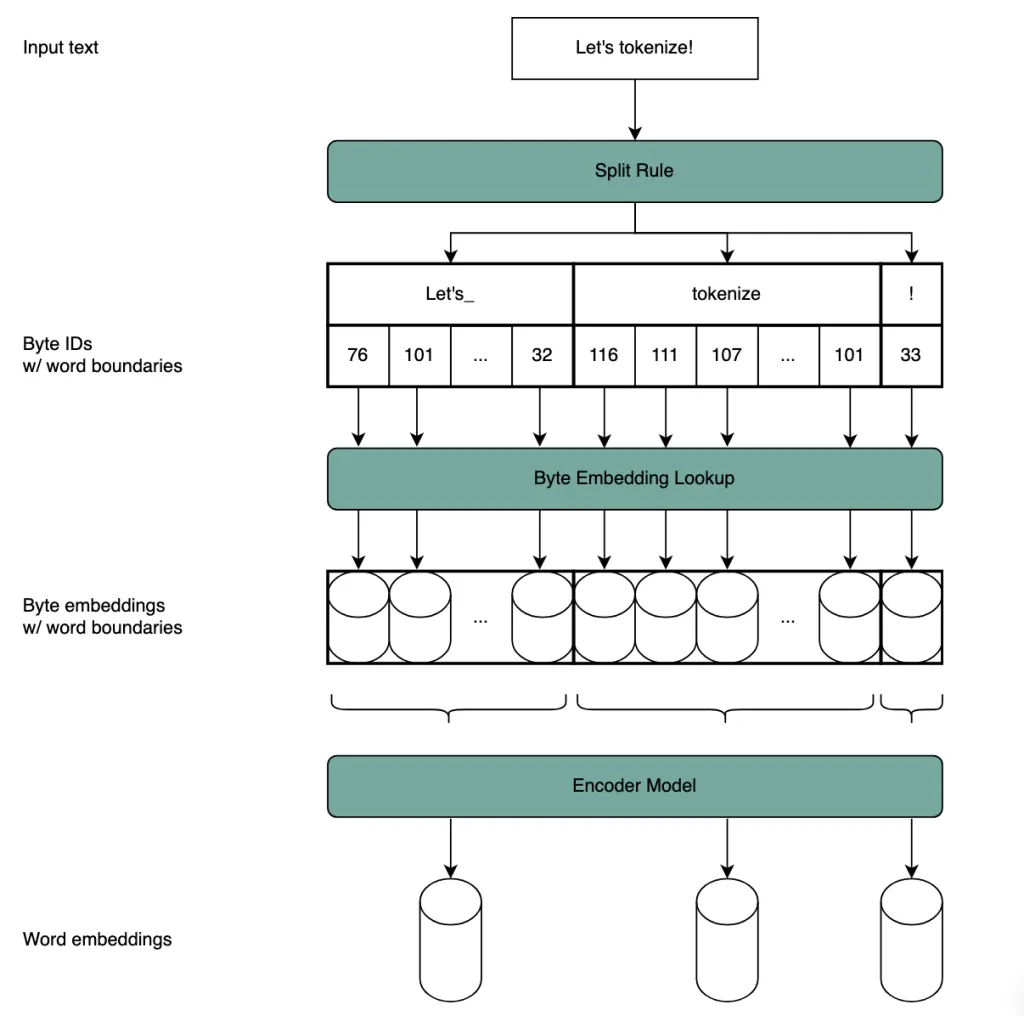
Abbildung 3: Unser Hierarchical Autoregressive Transformer beruht nicht auf einem (Sub-)Wort-Vokabular. Stattdessen wird der Text auf Basis einer einfachen Splitting-Regel in Wörter segmentiert. Jedes Byte wird separat eingebettet, anschließend wird die Sequenz von Bytes innerhalb jedes Wortes durch ein kleines Encoder-Modell geleitet, um ein Wort-Embedding zu erzeugen.
Die Outputs des Backbones werden als abstrakte „prädiktive“ Wort-Embeddings behandelt und durch ein weiteres kleines, zeichenbasiertes Decoder-Modul zurück in Zeichen dekodiert. Die zeichenbasierten Module sind sehr klein und haben weniger Parameter als die Token-Level- Embedding- und Output-Head-Komponenten, die sie ersetzen. Encoder, Backbone und Decoder sind Transformer-Modelle, und das gesamte System lässt sich End-to-End trainieren – ohne festen, vortrainierten Tokenizer.
Das Modell operiert auf rohen UTF-8-Bytes als Basis-Alphabet, mit einer winzigen Vokabulargröße von nur 256. HAT kann jedes Wort über diesem Basis-Alphabet einlesen und ausgeben.
Pre-Training
Für diese Demo haben wir ein hierarchisches Transformer-Modell mit 7 Milliarden Parametern auf dem englischen DCLM-Baseline-Datensatz vortrainiert. Das Backbone der Architektur ist ein Standard-Decoder-only-Transformer, der weitgehend dem Llama-3-Design folgt. Er hat 32 Layer, 32 Query-Heads und 8 Key-Value-Heads.
Wir haben dieses Modell auf rund 1,9 Billionen Wörtern DCLM-Daten trainiert, was ca. 2,3 Billionen Tokens mit einem konventionellen Tokenizer entspricht. Das Kontextfenster umfasst 3072 Wörter, das Äquivalent von rund 3720 Tokens. Das Trainings-Rezept folgt etablierten Standards mit dem AdamW-Optimizer und linearem Warm-up gefolgt von einem Cosine-Decay-Schedule.
Beachte: Dieses Modell ist deutlich günstiger zu trainieren als ein 7B-Parameter-Modell mit einem konventionellen Subwort-Tokenizer. Das Backbone unserer hierarchischen Architektur, das den Großteil des Compute beansprucht, operiert auf der Wort-Ebene – einer gröberen Einheit als Subwort-Tokens. Während ein typischer Tokenizer etwa 4 Bytes pro Token verarbeitet, erzeugt unsere Wort-Splitting-Regel auf englischem Text im Durchschnitt mehr als 5 Bytes pro Wort. Das heißt: Obwohl unser Modell das Äquivalent von 2,3 T Tokens an Daten gesehen hat, sind dabei nur die Kosten für das Training eines tokenizer-basierten Modells ähnlicher Größe auf 1,9 T Tokens angefallen.
Das resultierende Modell schneidet auf gängigen Pre-Training-Evaluationen gut ab, siehe Tabelle 1. Es erreicht z.B. einen Score von 59,4% auf dem MMLU-Benchmark. Zum Vergleich zeigen wir Werte des Apple-DCLM-7B-Modells – ein vergleichbares Open-Source-Modell, das auf 2,5 T Tokens trainiert wurde (und damit rund 30% mehr Compute als unser Modell verbraucht hat) – auf einer Kombination aus DCLM-Baseline sowie Math- und Code-Datensätzen (die wir nicht verwendet haben). Wir berichten außerdem Werte für Llama-3.1-8B sowie für Metas Byte Latent Transformer (BLT), einen aktuellen Vorschlag für eine Byte-Level-Architektur. Unser Modell liegt insgesamt auf vergleichbarem Niveau.
| Llama-3.1-8B | Apple-DCLM-7B | Meta BLT-Entropy-8B* | HAT-7B (pre-trained) | |
|---|---|---|---|---|
| Pre-Training-Daten | Proprietär (>15T Tokens) | DCLM-Baseline + Math + Code (2,5T Tokens) | Proprietär (1T Tokens äquivalent) | DCLM-Baseline (2,3T Tokens äquivalent) |
| Bytes pro Token/Wort | 4,56 | 4,35 | 4,5 | 5,28 |
| MMLU (5-shot) | 0,656 | 0,62 | 0,574 | 0,594 |
| ARC Challenge (25-shot) | 0,583 | 0,602 | 0,521 | 0,613 |
| GPQA (1-shot) | 0,292 | 0,319 | - | 0,279 |
| HellaSwag (10-shot) | 0,815 | 0,812 | 0,806 | 0,815 |
| Winogrande (5-shot) | 0,69 | 0,691 | - | 0,7 |
Die Tabelle listet außerdem die Kompressionsraten der Modelle auf: HAT erreicht 5,28 Bytes/Wort gegenüber 4,35 Bytes/Wort beim Apple-DCLM-Modell. Beim Deployment würde das HAT-Modell damit rund 18% Rechenkosten einsparen!
Werte entnommen aus dem Meta-Paper Byte Latent Transformer: Patches Scale Better Than Tokens
Lass uns Finnisch lernen!
Um die Finetunability unserer tokenizer-freien Architektur zu zeigen, bringen wir unserem Modell Finnisch bei! Wir haben Finnisch als Beispiel für eine relativ ressourcenarme Sprache gewählt, die sich deutlich vom Englischen unterscheidet. Wie oben besprochen ist eine solche Sprachaneignung wegen der statischen Natur des Tokenizer-Vokabulars eine erhebliche Herausforderung für tokenizer-basierte Modelle.
Für diese Sprachaneignungs-Phase gehen wir in zwei Schritten vor: Continued Pre-Training und Instruction-Finetuning.
Continued Pre-Training
Zuerst führen wir ein Continued Pre-Training (CPT) auf einem 2:1-Mix aus dem finnischen Teil des FineWeb2-Datensatzes und (englischen) DCLM-Baseline-Daten durch. Die finnischen Daten umfassen insgesamt 18 B Wörter, wir machen zwei Durchläufe. Das Trainingsbudget für diese Phase beträgt nur 54 B Wörter – weniger als 3% des Pre-Training-Budgets. Ergebnisse auf einer Reihe finnischer Pre-Training-Evaluationen sind in Tabelle 2 dargestellt. Zusätzlich zu Llama-3.1-8B und Apple-DCLM-7B vergleichen wir mit Viking-7B – einem ähnlich großen Open-Source-Modell, das mehrsprachig von Grund auf auf Englisch, Finnisch und anderen nordischen Sprachen trainiert wurde.
| Eval-Task | Llama-3.1-8B | Viking-7B | Apple-DCLM-7B (CPT'ed) | HAT-7B (CPT'ed) |
|---|---|---|---|---|
| ARC-Fin (25-shot) | 0,387 | 0,355 | 0,471 | 0,453 |
| MMLU-Fin (5-shot) | 0,483 | 0,262 | 0,508 | 0,443 |
| FinBench Classification (3-shot) | 0,635 | 0,584 | 0,607 | 0,663 |
| FinBench OpenQA (3-shot) | 0,595 | 0,434 | 0,622 | 0,572 |
| FinBench Reasoning (3-shot) | 0,636 | 0,555 | 0,677 | 0,578 |
| FinBench Math (3-shot) | 0,807 | 0,269 | 0,543 | 0,374 |
Insgesamt erwerben sowohl das Apple-DCLM-Modell als auch unser HAT-Modell laut diesen Benchmarks erfolgreich finnische Sprachfähigkeiten. Beide übertreffen Viking-7B, das von Grund auf mehrsprachig trainiert wurde. HAT ist in Math und teils in Reasoning-Tasks schwächer, was wir auf das Fehlen von Math und Code in unseren Pre-Training-Daten zurückführen.
Instruction-Finetuning
In der zweiten Phase feintunen wir das Modell auf einer Kombination aus englischen und finnischen Instruction-Finetuning-Daten. Ergebnisse auf englischen und finnischen Evaluations-Tasks sind in Tabelle 3 dargestellt. Wir wenden auch hier das identische Vorgehen als Vergleichspunkt auf das Apple-DCLM-7B-Modell an. Vergleichbare Instruction-getunte finnische Open-Source-Modelle sind uns nicht bekannt. Auf diesen generativen Evaluations-Tasks übertrifft das HAT-Modell das tokenizer-basierte Apple-DCLM-Modell durchgängig.
| Eval-Task | Apple-DCLM-7B (finetuned) | HAT-7B (finetuned) |
|---|---|---|
| MT-Bench Fin (Single-Judgement) | 2,72 | 2,98 |
| Finnstructable* avg | 0,554 | 0,684 |
| Finnstructable grammar | 0,88 | 0,96 |
| Finnstructable quality | 0,1 | 0,35 |
Finnstructable ist ein interner Benchmark für Instruction-Following auf Finnisch, mit Instruktionen, die von GPT-4 generiert und bewertet werden.
Inferenz-Effizienz
Das Apple-DCLM-Modell in einem finnischen Use-Case einzusetzen, wäre massiv ineffizient. Die Kompressionsrate des Tokenizers fällt von 4,35 Bytes pro Token im Englischen auf 2,68 Bytes pro Token im Finnischen. Im Gegensatz dazu steigt die Kompressionsrate unseres wort-basierten HAT-Modells auf 7,96 Bytes pro Wort im Finnischen – aufgrund der längeren durchschnittlichen Wortlängen. Das bedeutet: Für ein gegebenes finnisches Dokument verarbeitet das HAT-Modell im Schnitt eine fast 3-mal kürzere Sequenz als das tokenizer-basierte Modell. Das ergibt eine 3-fache Reduktion bei Rechenkosten und Activation-Memory-Verbrauch. Vergleicht man umgekehrt Modelle mit identischen Kontextgrößen in Tokens bzw. Wörtern, deckt das wort-basierte Modell 3-mal mehr effektiven Kontext ab (gemessen in Bytes).
| Apple-DCLM-7B | HAT-7B | |
|---|---|---|
| EN: Bytes pro Token/Wort | 4,35 | 5,28 |
| FIN: Bytes pro Token/Wort | 2,68 | 7,96 |
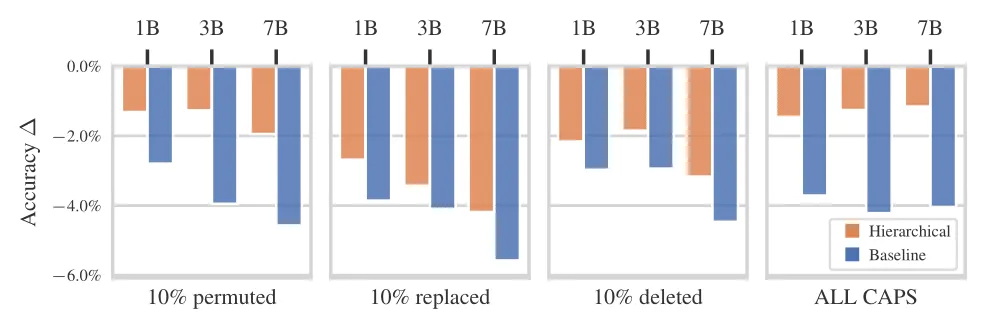
Robustheit
Zusätzlich zur verbesserten Inferenz-Effizienz ist das HAT-Modell laut unserem Paper auch deutlich robuster gegenüber Störungen der Eingabe (unvollständige Wörter, Tippfehler) als tokenizer-basierte Modelle. Wir messen das, indem wir Störungen auf die Prompts ausgewählter Evaluations-Tasks anwenden und die Veränderung der durchschnittlichen Genauigkeit gegenüber der Performance jedes Modells auf dem Originalprompt erfassen. Zu den Störungen gehören das Permutieren, Randomisieren oder Löschen von 10% der Zeichen pro Wort sowie das Umwandeln des Prompts in Großbuchstaben.
Fazit
Wir haben die Hierarchical-Autoregressive-Transformer-(HAT)-Architektur vorgestellt – einen tokenizer-freien Ansatz zur Sprachmodellierung. Wir haben gezeigt, wie diese auf Englisch vortrainierte Architektur effektiv feinabgestimmt werden kann, um eine zuvor ungesehene Sprache zu erlernen, dabei aber durch hohe Kompressionsraten effizient bleibt. Wir glauben, dass tokenizer-freie, End-to-End-trainierte Ansätze wie der hier vorgestellte ein vielversprechender Weg zu robusteren und anpassungsfähigeren Sprachmodellen sind.