Aleph Alpha Blog
TFree-HAT 7B vorgestellt: Tokenizer-freie Modelle mit Top-Tier-Multilingualität
Wir freuen uns, etwas Frisches aus unserem Research Lab zu teilen. Den größeren Kontext dazu, warum wir überhaupt tokenizer-freie Modelle bauen, findest du hier.
Erst kürzlich haben wir zwei neue tokenizer-freie Modelle veröffentlicht, die auf unserer Hierarchical-Autoregressive-Transformer-Architektur (HAT) basieren:
- TFree-HAT-Pretrained-7B-Base, von Grund auf auf Englisch und Deutsch vortrainiert
- Llama-TFree-HAT-Pretrained-7B-DPO, ein nachtrainiertes Modell auf Basis der Base-Version
Diese Modelle bauen auf vorherigen Arbeiten aus dem April auf, in denen ein Llama-3.1-8B-Backbone nachträglich mit der HAT-Architektur ausgestattet wurde. Mit diesen 7B-Modellen haben wir erstmals erfolgreich die HAT-Architektur durchgängig end-to-end trainiert – und sie damit weiter als architektonischen Fortschritt etabliert, wie Modelle Text verarbeiten und verstehen.
In ihrer 7B-Größe sind sie für Deployment-Einschränkungen gemacht – etwa für On-Device-Verarbeitung, lokales Deployment oder andere Aufgaben, die effiziente Textkompression erfordern.
Diese Modelle liefern:
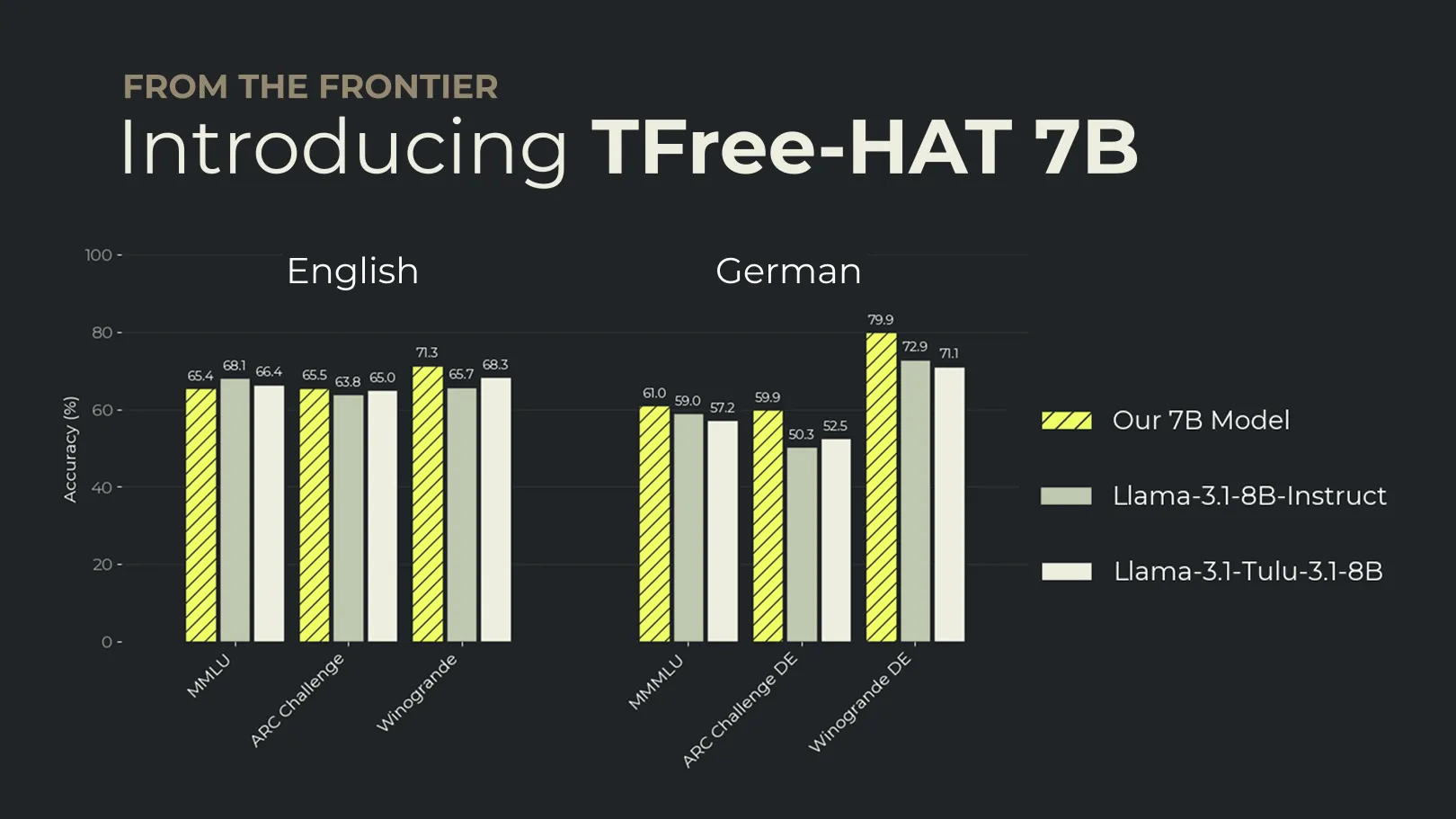
- Außergewöhnliche Deutsch-Performance in dieser Größenklasse: schlägt Llama 3.1 8B in 67% der gemessenen deutschen Benchmarks und liegt im Englischen gleichauf.
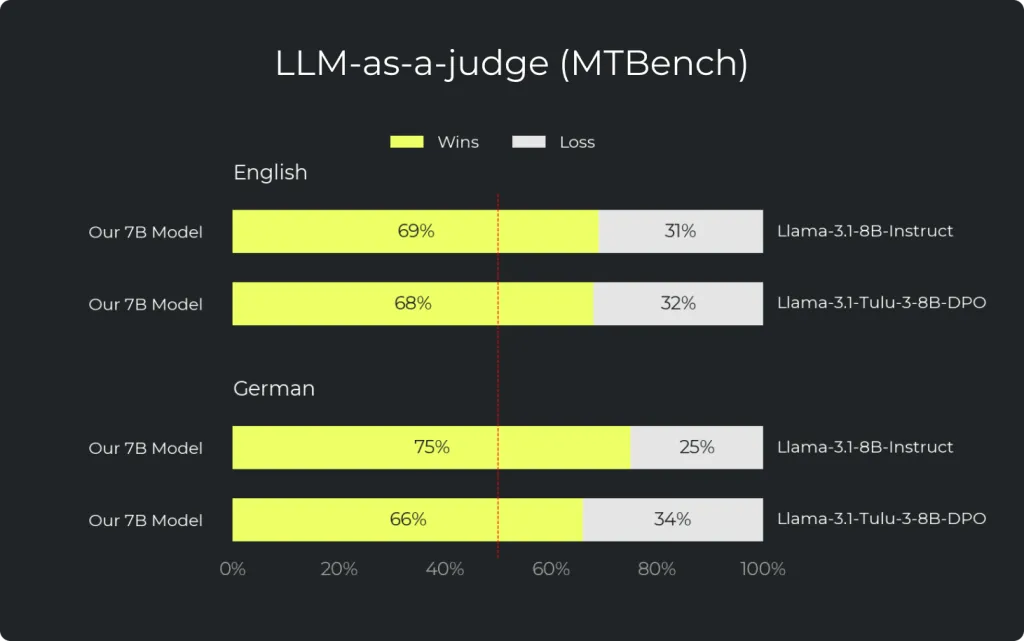
- Spitzenleistung in LLM-as-a-Judge-Settings: Antworten des 7B-DPO-Modells werden in 69% der englischen und 75% der deutschen Fälle den Antworten von Llama 3.1 8B vorgezogen.
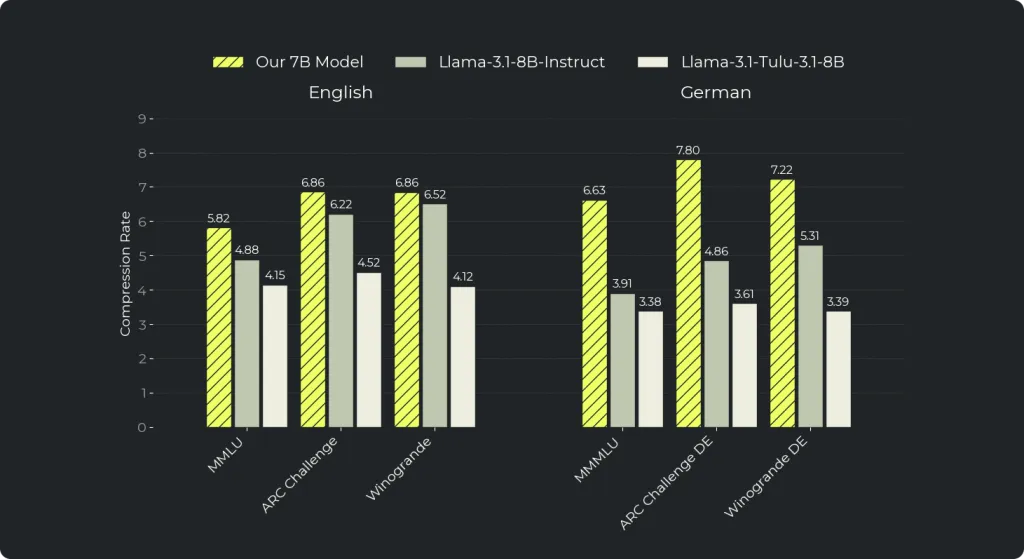
- Bessere Sequenzkompression: HAT verarbeitet Sprache in ganzen Wörtern statt in kleineren Subwort-Stücken, wodurch HAT denselben Text in weniger Schritten versteht (also mit einer höheren Kompressionsrate). Diese höhere Kompression eröffnet Spielraum für effizientere Inferenz – etwa 40% weniger FLOPs im Deutschen gegenüber einer Baseline.
Wie sich diese reduzierten FLOPs in tatsächlich verbesserte Latenz/Durchsatz übersetzen lassen, hängt stark von der Inferenz-Implementierung und der Hardware ab. Damit die Community mit T-Free forschen und entwickeln kann, veröffentlichen wir eine work-in-progress (Fork-)vLLM-Implementierung als Open Source, die T-Free-Modelle unterstützt und in der relevante Kennzahlen wie Latenz und Durchsatz gemessen werden können.
Zusätzlich haben wir 200 Pre-Training-Checkpoints über den Trainingsverlauf hinweg veröffentlicht – zur weiteren Untersuchung und Nutzung durch die Community, etwa zur Analyse der Lerndynamik. Sie sind in der Model Card des Base-Modells zu finden.
Im Folgenden umreißen wir, was TFree-HAT besonders macht, wie es performt und wie du heute damit bauen kannst.
Randnotiz: Das DPO-Modell wurde mit Llama 3.3 für das Filtering feinjustiert. Gemäß der Llama-Lizenz haben wir das Modell mit dem llama-Präfix benannt.
Warum tokenizer-frei?
Tokenisierung – also wie wir Text in Stücke zerlegen (Subwort-Vokabular) –
begünstigt häufig Englisch, sodass andere Sprachen und Schriften in viele winzige Teile
zerhackt werden. In ressourcenarmen Sprachen und Nischendomänen (z.B. Recht, Fertigung)
werden geläufige Begriffe in seltene Teilstücke zerlegt, Sequenzen werden länger,
Rechenkosten steigen und Bedeutung wird unschärfer. Diese Zerstückelung schadet sowohl dem
Lernen als auch der Generierungsqualität. Unterm Strich: ein eingebauter Sprach- und
Domänen-Bias, der LLMs ineffizienter, teurer und weniger verlässlich macht, wo Daten knapp
sind.
Unsere Architektur ersetzt das große, feste Subwort-Vokabular durch einen
Byte-Level-Encoder und -Decoder rund um ein Word-Level-Backbone. Dieses Design reduziert die
Gesamtparameteranzahl von 8B auf knapp unter 7B, indem sowohl die Embedding- als auch die
Sprachmodell-Kopf-Matrizen kleiner werden. Weil Bytes universell sind, passt sich das Modell
nahtlos an neue Sprachen und Domänen an – ohne die oben beschriebenen
Tokenisierungs-Probleme.
Wir messen diese Effizienzgewinne über die Kompressionsrate – die durchschnittliche Anzahl Bytes, die pro Sequenzposition repräsentiert werden. Eine höhere Rate bedeutet: Das Modell verarbeitet mehr Text in weniger Schritten, was sich direkt in geringeren Compute-Anforderungen niederschlägt. Der Vorteil von HAT gegenüber Standard-Tokenisierung zeigt sich am stärksten in ressourcenarmen Sprachen und spezialisierten Domänen, in denen traditionelle Tokenizer Text in unverhältnismäßig kleine Stücke zerlegen. In unseren Evaluierungen erreichte HAT im Durchschnitt 40% bessere Kompression im Deutschen und 16% bessere Kompression im Englischen verglichen mit Llama 3.1 8B – ein Beleg sowohl für die Fähigkeit, anspruchsvolle Sprachen effizient zu verarbeiten, als auch für die Überlegenheit in High-Resource-Settings.
Benchmarks
Wir evaluieren alle Modelle mit derselben Harness und denselben Einstellungen, um Äpfel-mit-Äpfeln-Vergleichbarkeit zu gewährleisten. Wir haben unser DPO-Modell gegen Llama 3.1 8B Instruct und Llama Tulu 3.1 8B über insgesamt 28 englische und deutsche Benchmarks verglichen. Die vollständigen Evaluationsergebnisse stehen in den entsprechenden Model Cards: Base-Evaluationen, DPO-Evaluationen.
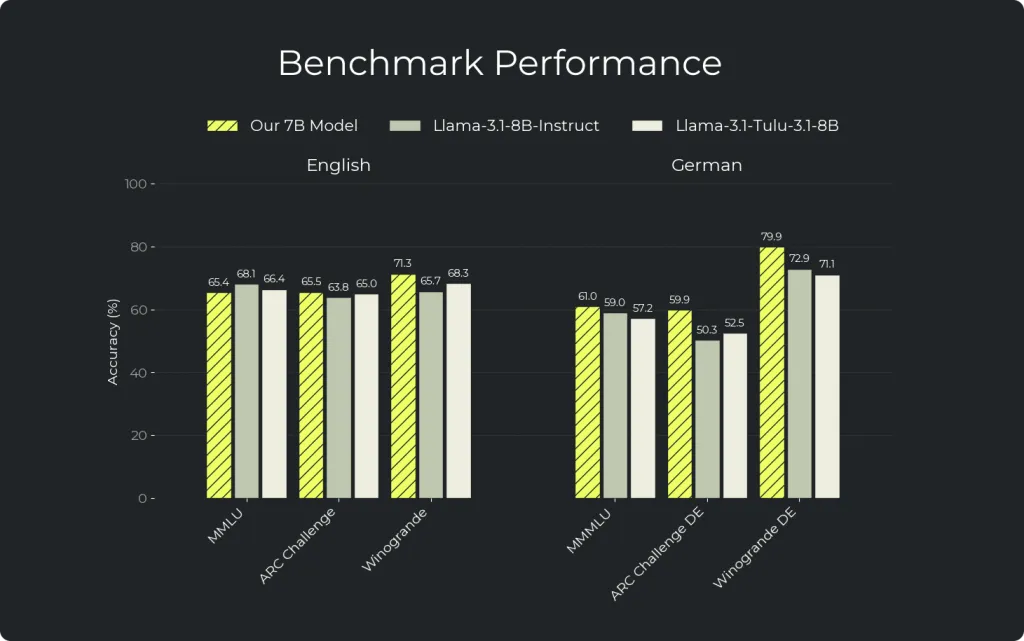
Die Zahlen beziehen sich auf das DPO-Modell.
Die Ergebnisse zeigen, dass unser DPO-Modell Llama 3.1 7B Instruct in 67% der deutschen Benchmarks übertrifft und im Englischen auf Augenhöhe liegt.
LLM-as-a-Judge (MTBench)
Unsere Modelle zeigen starke Performance auf MTBench, einem Benchmark, der mit FastChat aufgebaut ist und Modell-Hilfreichkeit über paarweise Vergleiche bewertet. In diesen Evaluationen werden Antworten des 7B-DPO-Modells in 69% der englischen und 75% der deutschen Fälle den Antworten von Llama 3.1 8B vorgezogen.
Loslegen
Um diese Modelle zugänglich zu machen, bieten wir zwei Inferenz-Implementierungen an: Hugging Face und vLLM. Der folgende Abschnitt beschreibt, wie du unsere Modelle zum Laufen bringst. Hinweis: Hugging Face ist vor allem für Testzwecke gedacht, während vLLM eine Hochleistungs-Inferenz-Implementierung ist, die die HAT-Architektur besser nutzt.
Hugging Face
Weights und Safetensors:
- Base: Aleph-Alpha/Llama-TFree-HAT-Pretrained-7B-Base
- DPO: Aleph-Alpha/Llama-TFree-HAT-Pretrained-7B-DPO
Wir stellen ein Inferenz-Modul bereit, das mit Hugging Face Transformers kompatibel ist. Für die besten Ergebnisse empfehlen wir, die Transformers-Bibliothek auf Version 4.46.3 zu pinnen. Bevor du das untenstehende Beispiel ausführst, stelle sicher, dass das hat-splitter-Package in deiner Umgebung installiert ist.
pip install 'hat-splitter>=0.1.9' 'transformers==4.46.3' torch
pip install flash_attnLade die Modellgewichte herunter und führe die Inferenz mit folgendem Beispiel aus:
import torch
from transformers import AutoModelForCausalLM
INPUT = "When was Rome founded?"
MODEL_ID = "Aleph-Alpha/Llama-TFree-HAT-Pretrained-7B-DPO"
model = AutoModelForCausalLM.from_pretrained(
trust_remote_code=True,
pretrained_model_name_or_path=MODEL_ID,
attn_implementation="flash_attention_2",
).to("cuda", torch.bfloat16)
input_ids, cumulative_word_lengths = model._prepare_input(INPUT, add_llama_template=True)
model_output = model.generate(
input_ids,
cumulative_seq_lengths_per_word=cumulative_word_lengths,
max_new_tokens=300,
use_cache=False,
)
print("Prompt: ", INPUT)
print("Completion: ", model_output.completion_text)vLLM Fork
Eine Hochleistungs-Inferenz-Implementierung ist auf dem vLLM-Fork von Aleph Alpha verfügbar. Diese Implementierung ist auf Batched-Inferenz optimiert. Bitte beachte, dass sie sich noch in aktiver Entwicklung befindet.
1. Voraussetzungen
- GPU: NVIDIA-GPU, mindestens 20 GB VRAM
- Python: 3.12.
2. Klonen und installieren
git clone https://github.com/Aleph-Alpha/vllm vllm-hat
cd vllm-hat
# Create and activate a 3.12 virtual env
uv venv -p 3.12
source .venv/bin/activate
# Tell vLLM to skip local compilation and use prebuilt CUDA wheels
export VLLM_USE_PRECOMPILED="1"
# Finally, install in editable mode
uv pip install -eBeide Checkpoints werden unter der Open Aleph License für Forschung und Bildung ausgeliefert. Probier unsere Modelle heute aus. Wir freuen uns auf dein Feedback.