
Aleph Alpha Blog
Wörter sind nicht leicht (… für LLMs): Universelles Text-Encoding für dynamische, mehrsprachige Alphabete – revolutioniert Effizienz und Effektivität von LLM-Training und -Inferenz
Universelles Text-Encoding für dynamische, mehrsprachige Alphabete – revolutioniert Effizienz und Effektivität von LLM-Training und -Inferenz
Motivation
Die bemerkenswerten Fortschritte von Large Language Models (LLMs) ziehen regelmäßig Aufmerksamkeit auf sich, während sie zu wertvollen Begleitern im Alltag werden – und gleichzeitig auf Durchbrüche jenseits einfacher Sprachvervollständigung zusteuern. Über die Standardaufgaben für Chatbots hinaus, die die meisten Angebote inzwischen zuverlässig lösen können, ist die erfolgreiche Anwendung auf spezifischere Probleme und ressourcenarme Sprachen nach wie vor schwer umzusetzen. Damit werden Fragen der Sprach-Fairness und der Domänenspezialisierung zentral für eine faire und skalierbare Wertschöpfung. Die bevorzugte Branchenlösung für solche Herausforderungen ist trotzdem nach wie vor: in noch mehr Compute zu investieren – und noch größere Modelle zu bauen, was Kosten und Datenbedarf an einen Punkt treibt, der in vielen Fällen unmöglich wird. Wir haben eine Architektur-Innovation entwickelt, die diese Punkte mit einem grundlegend anderen Ansatz zur Textmodellierung adressiert.
Entscheidende erste Schritte beim Bau von LLMs sind die Tokenisierung – die Diskretisierung von Text – sowie das Einbetten der resultierenden Tokens in eine numerische Repräsentation. In diesem Blogpost stellen wir ein neues Paradigma für die Tokenisierung vor, das LLM-Training und -Inferenz signifikant verbessert und neue Fähigkeiten für schnelleren Sprach-Transfer von Large Language Models freisetzt.
Kurz gesagt zeigen wir, dass unsere Innovation „T-Free“ Folgendes erreicht:
- Günstigeres Training und günstigere Inferenz für LLMs: bis zu 50% Reduktion der Trainings-[1] und Inferenzkosten[2] im Vergleich zu SOTA-Tokenizern von LLama3 oder NeMo-Tekken,
- Bessere semantische Kodierung von Sprache: kleinere Embedding-Matrizen und Vokabulare, die Synergien zwischen Wörtern nutzen,
- Schnelleres und flexibleres Cross-Lingual-Transfer-Learning: kein festes Vokabular mehr nötig, dadurch effizienteres Training mehrsprachiger Modelle auf zuvor ungesehenen Sprachen.
Von Wörtern zu Zahlen
LLMs sind eine bestimmte Art künstlicher neuronaler Netze, die auf einem riesigen Textkorpus trainiert werden. Die Trainingskosten eines größeren – und damit leistungsfähigeren – Modells mit mehreren Milliarden Parametern übersteigen leicht mehrere hundert Millionen Dollar (Stand 2024). Die notwendigen Akquisitions- und Personalkosten erhöhen das nochmals deutlich. Der erste Schritt beim Training dieser Modelle ist die Umwandlung natürlicher Sprache in eine Repräsentation, die das Large Language Model verarbeiten kann.
Kernidee
Die Kernidee, Wörter in eine maschinenlesbare Repräsentation zu überführen, ist überraschend einfach: Wir bauen zunächst ein Dictionary, zerteilen den Text nach den Regeln dieses Dictionarys in kleinere Stücke – sogenannte Tokens[3] – und ordnen jedem Token eine eindeutige Identifikationsnummer zu (Index im Dictionary). Ein Beispiel für die Verarbeitungsschritte bei einer LLM-Vorhersage zeigt Abb. 1. Aktuelle Ansätze bauen dieses Dictionary mit statistischen Methoden auf einem Referenz-Textkorpus und verfolgen das Ziel, die Gesamtzahl der auf diesem Korpus erzeugten Tokens zu minimieren – beschränkt durch die Vokabulargröße, also die Anzahl der verfügbaren Tokens. Diese Beschränkung ist notwendig, weil die Vokabulargröße direkt die Parameteranzahl des LLM beeinflusst.
In gewisser Weise ist diese Dictionary-Erstellung schon ein Pre-Training vor dem eigentlichen Modelltraining – denn das Dictionary hängt allein vom verwendeten Referenzkorpus ab und bleibt danach fest. Auf die Optimierung des Vokabulars kann viel Aufwand verwendet werden – schließlich bestimmt es, was das LLM überhaupt verstehen kann – doch das Ergebnis zeigt sich erst nach einem vollständigen Modelltraining.
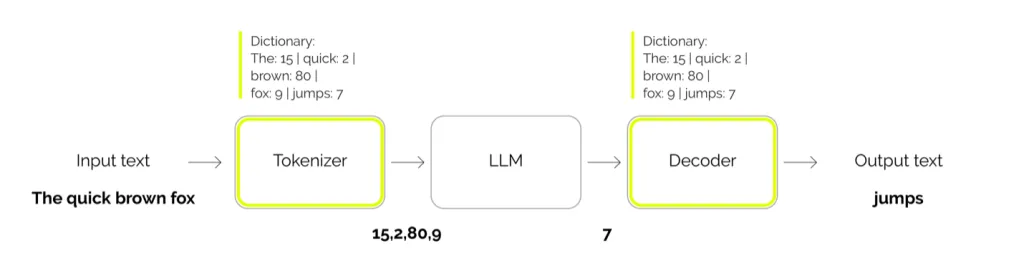
Abb. 1 Verarbeitungs-Pipeline von LLMs: Der Eingabetext wird vom Tokenizer in eindeutige numerische Identifier zerlegt, die das LLM verarbeitet, um wiederum einen solchen Identifier vorherzusagen – das nächste (Sub-)Wort.
Schwächen
In Abb. 1 ist jedes Wort durch genau eine ID repräsentiert. Das ist meist der Idealfall, weil wir so sicherstellen, dass unabhängige Wörter unabhängige Nummern erhalten und damit unabhängig voneinander von Grund auf trainiert werden. Die Vokabulargröße ist jedoch begrenzt, weil im LLM eine trainierte Parametermatrix nötig ist, um die Token-Nummern in verarbeitbare State-Vektoren umzuwandeln. Deshalb können wir nicht ganze Wörter so kodieren, wie sie sind, sondern müssen so weit wie möglich kleinere Bestandteile für mehrere Wörter wiederverwenden. Wenn das Referenzkorpus z.B. zu wenig „üblicher englischer Sprache“ enthielt – weil es (wie üblich) hauptsächlich von deutschen Websites zusammengetragen wurde –, könnte der folgende Satz (Unterstrich bedeutet Leerzeichen):
„The_quick_brown_fox_jumps_over_the_lazy_dog.“
so zerteilt werden:
„The“, „_qu“, „ick“, „_br“, „own“, „_f“, „o“, „x“, „_jump“, „s“, „_over“, „_the“, „_lazy“, „_dog“, „.“
mit 15 Tokens.
In diesem Beispiel besteht die Token-Repräsentation für „_jumps“ aus „_jump“ und „s“. Man könnte argumentieren, dass das wünschenswert sei, weil ein sauberes Präfix erzeugt wurde, das sich zur Bildung vieler Wortvarianten wie „_jump“, „_jumps“, „_jumping“ usw. wiederverwenden lässt, während der vollständige Wortstamm das Präfix bleibt.
Zu beachten ist allerdings, dass Leerzeichen und Groß-/Kleinschreibung explizit im Dictionary kodiert werden. Varianten wie „the“, „The“ und „_The“ landen als (fast) Duplikate darin und verbrauchen wertvolle Vokabular-Einträge. Sie erhalten unabhängige Nummern und werden damit trotz ihrer engen semantischen Bedeutung unabhängig voneinander von Grund auf trainiert.
Außerdem wurden auch „quick“, „brown“ und „fox“ in mehrere Tokens zerlegt! Das passiert immer dann, wenn Wörter im Referenzkorpus, mit dem der Tokenizer kompiliert wurde, nicht häufig genug vorkamen. Das Wort „fox“ wurde sogar in drei Tokens zerteilt: „_f“, „o“ und „x“. Das Modell muss dann lernen, diese Tokens wieder zu einem Wort zusammenzusetzen. Außerdem brauchen wir die dreifache Verarbeitungsleistung, um dieses zerteilte Wort zu verarbeiten – zu verstehen oder vorherzusagen.
Der rein statistische Ansatz wählt auch Zeichenketten aus, die im Referenzkorpus eine Anomalie sind und aus objektiver Sicht keinen Sinn ergeben. In einem älteren OpenAI-Tokenizer zeigt sich das deutlich an Tokens wie: „ SolidGoldMagikarp“, „_RandomRedditor“, „rawdownloadcloneembedreportprint“, „?????-?????-“, „ÃÂÃÂÃÂÃÂÃÂÃÂÃÂÓ, „ÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÓ, „ TheNitrome“, „ TheNitromeFan“. Es wurde zudem gezeigt, dass die Nutzung dieser Tokens zu Fehlern, Halluzinationen, Sicherheitsverletzungen und Missverständnissen zu verwandten Inhalten führt[4].
Logischerweise gilt: Je mehr Tokens eine Sprache für einen gegebenen Text benötigt, desto weniger effizient arbeitet das Modell auf ihr – bis hin zu dem Punkt, an dem es sie womöglich gar nicht mehr verstehen kann. Der Extremfall buchstabenweiser Tokens kommt mit einer deutlichen Performance-Verschlechterung (Compute-Bedarf und Benchmark-Evaluationen) und ist weiterhin aktive Forschung[5].
Zusammengefasst wird das LLM trainiert, eine hochdimensionale Mustererkennungs-Aufgabe zu lösen, in der jedes Token eine völlig neue und unabhängige Dimension des zu lösenden Problems ist. Manche Wörter werden in mehrere Subwörter zerlegt, weil sie beim Bau des Dictionarys nicht relevant genug waren, andere tauchen mehrfach auf – mit nur geringen typografischen Unterschieden. Beides verlangt vom LLM spezielle Fähigkeiten: das eine, um Wort-Splits zusammenzuführen und gemeinsam als eines zu verstehen, das andere, um Beinahe-Duplikate als gleich zu erkennen. Schwächen in der Auswahl der Vokabular-Einträge bestimmen direkt die maximal erreichbare Sprachverarbeitungs-Performance des später trainierten LLM. Das Vokabular wird ausschließlich auf Basis von Statistik gesammelt und entspricht keineswegs der bekannten wissenschaftlich-linguistischen Relevanz. Ist das Modell einmal trainiert, ist es schwierig, das Vokabular zu verändern – z.B. wenn man auf Use-Cases wie weitere spezifische Sprachfähigkeiten optimieren oder neue Sprachen ergänzen will.
Einfluss des Dictionarys
Das Dictionary diktiert, wie ein Modell Sprache interpretiert und „denkt“. Auf Architekturebene beeinflusst es zudem die Dimensionen der ersten und letzten Schicht eines LLM – Embedding und Head (wir besprechen sie unten mit Abb. 3 und 5). Sie wandeln, grob gesagt, die Token-Identifikationsnummer in reellwertige Repräsentationen um und zurück. In aktuellen State-of-the-Art-Modellen wird eine bijektive 1:1-Abbildung zwischen diesen Repräsentationen verwendet, und die zugehörigen Matrizen haben die Dimension Vokabulargröße × Hidden-Size des Modells. Sie sind die größten Matrizen im Sprachmodell und tragen deshalb maßgeblich zum Gesamt-Parameter-Count und zu rechnerischen (In-)Effizienzen bei. Daher werden sie – und implizit das Dictionary – massiv eingeschränkt. Für Modelle mit „begrenzten Fähigkeiten“ reicht ein Vokabular mit 16k oder 32k Einträgen. In der Ära des Allzweck-Allrounders enthalten aktuelle State-of-the-Art-Modelle aber Vokabulare jenseits von 250k Einträgen. Diese beiden Schichten summieren sich dann auf bis zu 6 Mrd. Parameter[6] – nur dafür, Token-IDs in Hidden-States und zurück zu wandeln. Das sind 75% der Größe eines kompletten LLama3-8B, das auch noch all das andere kann.
T-Free: Unsere einheitliche Alternative zu klassischen Tokenizern
Wie beschrieben geht im zuvor diskutierten klassischen Ansatz viel Potenzial verloren. Insbesondere wollen wir i) die Zahl unabhängig trainierter Redundanzen im Vokabular reduzieren, ii) Transfer-Learning zwischen ähnlichen Wörtern verbessern und nicht alles von Grund auf lernen, als gäbe es keinerlei Korrelation zwischen Wörtern, und iii) Flexibilität für künftige Use-Cases ermöglichen – z.B. dass die Performance nicht drastisch einbricht, wenn das Training mit Sprachen oder Wortverteilungen fortgesetzt wird, die ursprünglich nicht geplant waren. Dafür schlagen wir „Tokenizer-Free“ vor – einen neuen Ansatz, der diesen Schwächen begegnet. Wir vergleichen den klassischen und den T-Free-Ansatz in Abb. 3.
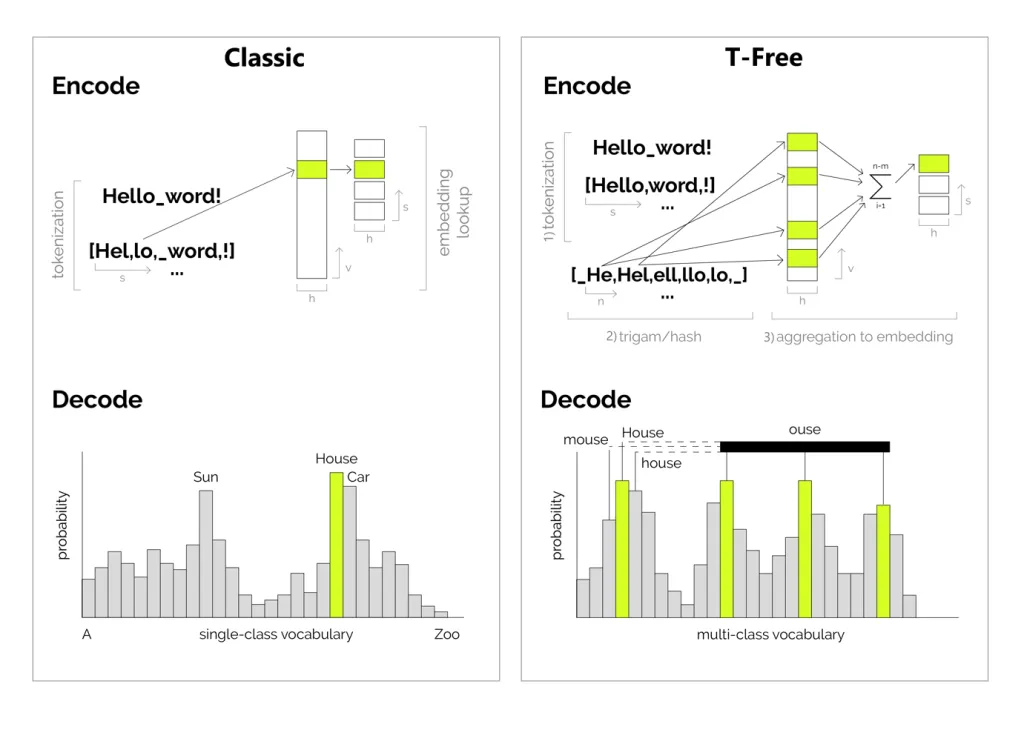
Abb. 3: Klassischer Tokenizer mit bijektivem Vokabular-Mapping (links) vs. T-Free mit Multi-Class-Vokabular (rechts) – für Encoding (oben) und Decoding (unten) von Text.
Encode
Als ersten Schritt im Encoding (oben rechts) teilen wir den Eingabetext an Nicht-Buchstaben. So bekommen wir genau ein Embedding pro Wort – unabhängig von Schreibvarianten – was unserer natürlichen Erfahrung näherkommt. Da wir nun deutlich mehr mögliche Wörter haben als Einträge in der Embedding-Schicht (für die wir zeigen, dass eine Vokabulargröße v ≈ 16k genügt), müssen wir die bijektive Abbildung zwischen Vokabular und Embedding-Schicht auflösen, die diese sonst zwingt, dieselben Dimensionen zu haben. Als Lösung betrachten wir die Kodierung eines Wortes als Mischung aus w ≈ 50 zufälligen Embeddings[7].
Da wir nun ein größeres Vokabular als die Embedding-Matrix haben, kommt es naturgemäß zu Überlappungen in den Mustern auf der Embedding-Schicht. Um das Training zu booten und ordentliches Sprachenlernen zu gewährleisten, modellieren wir eine robuste Hash-Funktion zwischen Wörtern, die eine Überlappung relativ zur Ähnlichkeit sicherstellt – „ähnlichere“ Wörter überlappen also stärker als andere. Als Ähnlichkeitsmaß nutzen wir einen byte-basierten Ansatz, um Universalität zu gewährleisten. Konkret bauen wir, wie in Schritt 2 gezeigt, alle Zeichen-Triplets eines Wortes. Es gibt insgesamt n = Wortlänge solche Triplets, und wir bilden jedes auf m ≈ 10 Embeddings ab. Dadurch werden gemeinsame Stämme oder Endungen wie „jump“ oder „ing“ immer auf dasselbe Set an Embedding-Aktivierungen abgebildet. Außerdem erzwingen wir eine 20%ige Überlappung der Aktivierungen mit den kleingeschriebenen Varianten. So teilen beliebige Groß-/Kleinschreib-Varianten eines Wortes mindestens 20% Aktivierungen mit der Kleinbuchstaben-Form. Wir haben festgestellt, dass diese Konfigurationen die Konvergenz von Training und Evaluations-Performance beschleunigen.
Das endgültige Embedding (Schritt 3) wird zur Aggregation aller dieser Werte – die Summe des gesamten aktiven Musters mit w = n × m Einträgen.
Decode
Analog zum oben beschriebenen Schema ändern wir auch das Vorhersageziel des Modells von Single- auf Multi-Class. Statt das Modell mit einem Mono-Signal direkt auf den jeweiligen Vokabular-Eintrag des nächsten Wortes zu trainieren, legen wir das Trainings-Signal auf alle w Aktivierungen des Musters des nächsten Wortes. Das kann zu robusterem Training und Recall-Verhalten führen, weil einzelne Ausreißer sich mitteln und nicht direkt zu katastrophal falschen Wort-Completions führen. Im Gegensatz zu klassischen Tokenizern finden wir unter den „höchsten“ wahrscheinlichen Vorhersagen erneut mehr ähnliche Wörter, wie im unteren Teil von Abb. 3 gezeigt.
T-Free-Forschungsergebnisse
Komprimierte Embedding-Schicht
Unsere Experimente zeigen, dass wir die Embedding-Schicht auf nur 8k Einträge reduzieren und in den meisten Evaluationen einer umfangreichen Benchmark-Suite trotzdem eine verbesserte Modell-Performance erzielen können, wenn man ein 3B-Modell-Pretraining mit T-Free gegen ein klassisches Tokenizer-Training mit 64k-Vokabular auf denselben Daten vergleicht. Einen Sweep über die nötige Vokabulargröße zeigt Abb. 4.
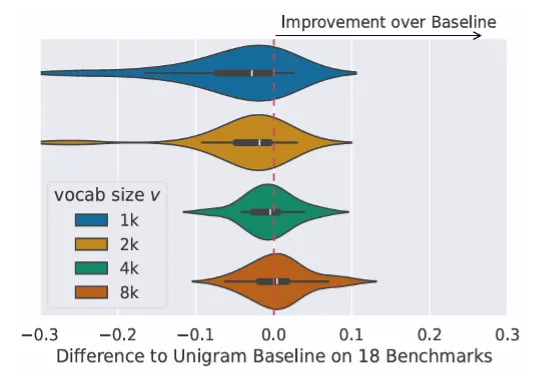
Abb. 4: Relative Performance-Differenz eines 3B-T-Free-Modells (8k-Vokabular) zu einem 64k-klassischen Tokenizer. Während ein Vokabular mit 1k Einträgen unzureichend scheint, verbessert sich T-Free bei einer Größe von 8k deutlich.
Das ist ein entscheidender Schritt in Richtung parameter-armer Modelle – die insbesondere für den jüngsten Trend, kleinere LLMs „on-the-edge“ einzusetzen, gebraucht werden. In dieser Experimentreihe haben wir die gesamten Trainingskosten halbiert[8]. Wie Abb. 5 zeigt, lässt sich der Parameter-Count zwar deutlich reduzieren, die durchschnittliche Einzeltoken-Inferenzzeit bleibt aber wegen der etwas komplexeren Decoding-Strategie in etwa gleich.
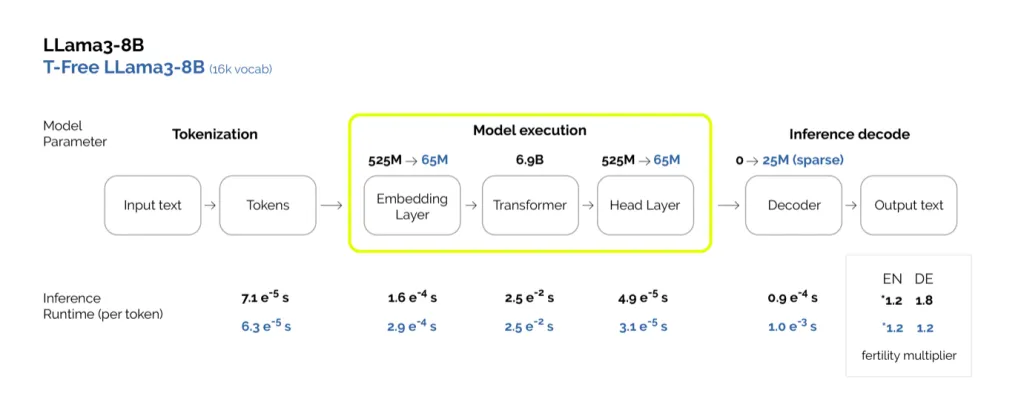
Abb. 5: Parameter-Count- und Inferenz-Laufzeit-Vergleich von LLama3-8B mit einer T-Free-Variante (16k-Vokabular).
Per Design keine Duplikate
Unsere Wortkodierung unterscheidet sich per Design grundlegend von der klassischer Tokenizer. In Tabelle 1 zeigen wir die große Überlappung von Beinahe-Duplikaten im Vokabular klassischer Tokenizer. Obwohl dieses Vokabular essenziell für Modellperformance und Gesamt-Parameter-Count ist, wird seiner Auslastung nach wie vor wenig Aufmerksamkeit geschenkt. Unser Ansatz hat per Design keine expliziten bijektiven Einträge, die nur für ihr Vokabular-Gegenstück aktiv sind – damit ist die Embedding-Schicht voll ausgelastet. Wir haben keine Duplikate mehr. Außerdem teilen Wörter Synergien durch ihre Schreibweise, und mindestens 20% der Aktivierungen werden – unabhängig von beliebigen Schreibvarianten – innerhalb desselben Wortes geteilt.
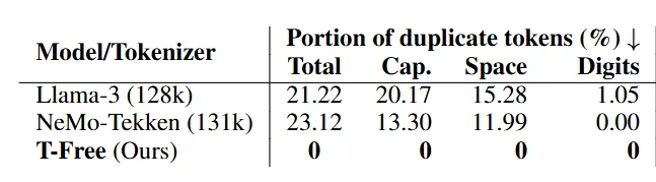
Tab. 1: Beinahe-Duplikat-Statistiken prominenter klassischer Tokenizer und unseres T-Free-Ansatzes.
Niedrigste Fertility über Sprachen hinweg, anpassungsfähiger an neue Sprachen – bessere Wiederverwendbarkeit
In Abb. 5 zeigen wir außerdem, dass die Fertility – also die durchschnittliche Anzahl finaler Embeddings, die zur Repräsentation eines Wortes nötig sind – über Sprachen hinweg bei unserem T-Free-Ansatz am niedrigsten bleibt. Die Performance state-of-the-art-Tokenizer hängt stark von der Verteilung des Referenzkorpus ab. Unterrepräsentierte Sprachen – etwa Deutsch oder Russisch in der Baseline des prominenten LLama3 – führen zu höheren Fertility-Werten und damit zu schlechterer Modellperformance: erhöhter Rechenaufwand (mehr nötige Iterationen) und reduzierte Verständnisfähigkeiten (wie zuvor beschrieben).
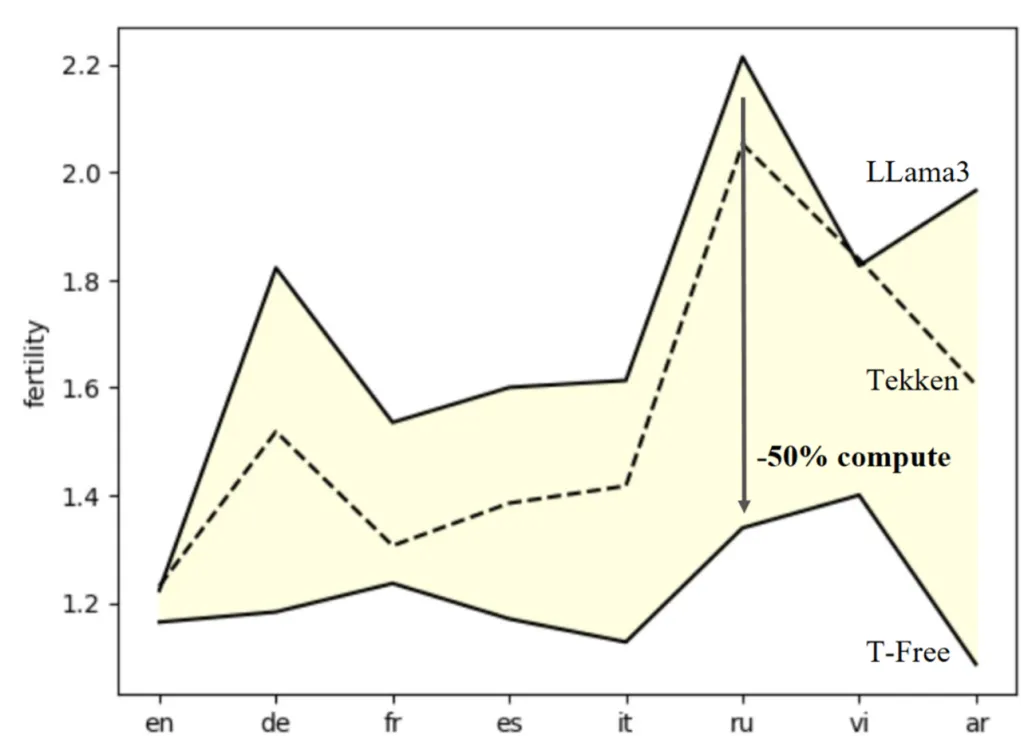
Abb. 5: Fertility-Statistiken (durchschnittliche Encoding-Länge pro Wort) für verschiedene Sprachen der state-of-the-art-Tokenizer LLama3 und NeMo-Tekken sowie unseres T-Free-Ansatzes.
Unser Ansatz benötigt keinen Referenzkorpus – das resultierende Modell ist damit weitgehend unverzerrt hinsichtlich seiner potenziellen Fähigkeiten. Diese Eigenschaft wird üblicherweise als „Sprach-Fairness“ bezeichnet. T-Free erreicht – selbst im Vergleich zu großen Vokabularen mit 256k Einträgen – in einigen Sprachen bis zu 50% Inferenz-Speedup durch die niedrigeren Fertility-Werte. In Abb. 5 sind die Werte des aktuellen LLama3 (128k; Meta) und NeMo-Tekken (131k; Mistral, Nvidia) visualisiert.
Um die Wirkung der vorigen Aussage zu zeigen, führen wir folgendes Transfer-Learning-Experiment durch: Wir trainieren Baseline-Modelle (mit T-Free und klassischer Tokenisierung) überwiegend auf englischen Daten und setzen das Training anschließend überwiegend auf deutschen Daten fort. In Abb. 6 sehen wir die – über mehrere Benchmarks gemittelten – Performance-Unterschiede: Out-of-the-Box performt T-Free (linke Hälfte) auf den deutschen Daten bereits (leicht) besser (orange). Im weiteren Training-Verlauf steigt seine Performance auf Deutsch rasch – besonders im Vergleich zum klassischen Ansatz. Obendrein fällt die Performance im Englischen (blau) – wenn überhaupt – nicht so drastisch ab wie beim Tokenizer-Ansatz, der einen klaren Abwärtstrend zeigt.
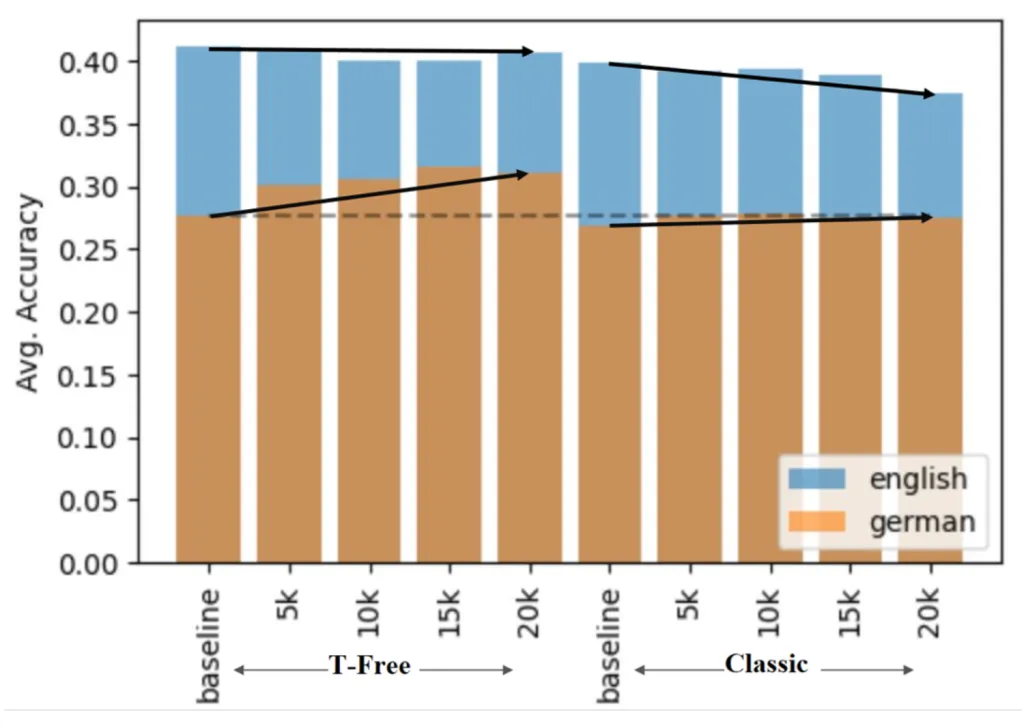
Abb. 6: Continued Pre-Training auf einem Englisch/Deutsch-Daten-Mix für Modelle, die zuvor nur auf Englisch trainiert wurden („Baseline“). T-Free passt sich besser an Deutsch an und behält die Englisch-Performance. Der klassische Tokenizer verliert – vermutlich aufgrund der Fertility-Unterschiede – an Performance im Englischen und passt sich langsamer an Deutsch an.
Open-Source-Forschung
Als Teil unserer Mission, öffentliche Forschung zu beschleunigen und zu fördern, sind wir fest entschlossen, reproduzierbaren Code und Modelle unter der Open-Aleph-Lizenz für Forschung und Bildung zu veröffentlichen.
Das vollständige Forschungspapier, Code und Modell-Checkpoint findest du hier:
2406.19223 (arxiv.org), Aleph-Alpha/trigrams (github.com).
Shout-out an alle Mitwirkenden – insbesondere unser kollaboratives Forschungs-Team #Lab1141 an der TU Darmstadt.
Fußnoten
[1] Nachgewiesen an einer 3B-Modell-Konfiguration im Paper.
[2] Basierend auf dem Vergleich der Fertility-Metrik.
[3] Der Prozess, Text in Tokens zu zerlegen, heißt „Tokenisierung“, die Einheit dafür „Tokenizer“.
[4] Quelle: https://www.lesswrong.com/posts/aPeJE8bSo6rAFoLqg/solidgoldmagikarp-plus-prompt-generation
[5] Z.B. Charformer, T. Yi et al. (https://arxiv.org/abs/2106.12672)
[6] Konfiguration von „command-R“.
[7] Aus der Kombinatorik lässt sich herleiten, dass es solche eindeutigen Muster gibt.
[8] Vgl. Abb. 4 des Papers.