
Aleph Alpha Blog
Alignment und Emotionen für Mensch und KI: Wenn wir KI vertrauen wollen, müssen wir ihr vielleicht wehtun
KI wird fast jeden Monat deutlich leistungsfähiger. Mit dieser neuen Tiefe und den transformativen Use-Cases denkt die Gesellschaft die Mensch-Maschine-Zusammenarbeit und ethisches Alignment neu.
KI wird fast jeden Monat deutlich leistungsfähiger. Mit dieser neuen Tiefe und den transformativen Use-Cases denkt die Gesellschaft die Mensch-Maschine-Zusammenarbeit und ethisches Alignment neu. Diese Diskussionen müssen ein breiteres Publikum und eine ganzheitliche Perspektive einbeziehen, und genau dabei taucht oft ein Missverständnis darüber auf, wie diese KI-Systeme funktionieren: Moderne große KI-Modelle zeigen beeindruckende Ergebnisse, aber sie haben keine Handlungsfähigkeit und vertreten keine Ansichten. Diese fehlende Handlungsfähigkeit wird zum Beispiel offensichtlich, wenn man versucht, Konsistenz in der Modellausgabe zu finden – sei es bei Fakten oder Meinungen. Fragt man Aleph Alphas Luminous-Modell nach den schönsten deutschen Städten, bekommt man selbst bei zwei sehr ähnlichen Prompts unterschiedliche Antworten. Natürlich ist das eine Frage, die sich gar nicht objektiv beantworten lässt – aus menschlicher Sicht ist das klar. Ein Sprachmodell kann nicht in Kategorien von subjektiv gelernten Mustern und objektiven Fakten denken: Eine Frage nach Grammatik, Stil, Geschmack oder Faktenwissen ist für das Sprachmodell nichts anderes – jeder Text, den es schreibt, ist gelernte Wahrscheinlichkeitsverteilung.

Diese Deep-Learning-Modelle zeigen alle ihre Fähigkeiten – richtig auf logische Situationen zu reagieren, Fragen zu beantworten, Zusammenfassungen zu schreiben – indem sie intern eine einzige Frage lösen: Was ist der wahrscheinlichste neue Text, der in einem gegebenen Kontext folgt? Die Antwort darauf beruht auf der Struktur und den Abhängigkeiten, die das Modell während seines Trainings gesehen hat. Diese Trainingsbeobachtungen enthalten alle Arten von Geschmack, veralteten Falschinformationen sowie beleidigende Sprache. Das Modell kann Dinge leicht aus dem Zusammenhang reißen – es ist nicht ausgeschlossen, dass Dokumente im Trainingsdatensatz, die die Schrecken des Zweiten Weltkriegs und des Nazi-Regimes beschreiben, dazu führen, dass das Modell das Wort „Nazi“ in einem Kontext verwendet, in dem wir das lieber nicht hätten.
Alignment-Forschung versucht, schlechte Ergebnisse zu verhindern und sicherzustellen, dass menschliche Präferenzen erfüllt werden. Ein Ansatz für Alignment und Sicherheit besteht darin, die Welt zu verändern, die diese Weltmodelle kennen – durch Filtern von Trainingsdaten oder Fine-Tuning des Modells, damit es sich stärker an unseren Zielen orientiert. Ich glaube, das kann in manchen Fällen helfen. Auf Dauer ist das aber der falsche Ansatz, der das Ziel nicht nur verfehlt, sondern auch neue Risiken einführt: Ein Modell, das noch nie etwas über Nazis gehört hat, wird nicht wissen, wie es sich verhalten soll, wenn es auf das Konzept stößt. Zusätzlich zwingt dieser Ansatz allen Nutzer:innen die Ideologie derjenigen auf, die das Modell bauen – ohne Transparenz darüber, wie das Weltbild und die Werte der Erbauer:innen die Modelle beeinflusst haben. Vielleicht weil die europäische Perspektive von Natur aus pluralistischer ist, glaube ich, dass verantwortungsvolle KI das Gegenteil tun sollte: transparent und nicht-ideologisch (so neutral und anpassbar wie möglich).
Starke Überzeugungen — locker gehalten
Große Sprach- oder multimodale Modelle sind begrenzte Weltmodelle: Sie modellieren die Welt der von Menschen erzeugten Sprache. Menschen erschaffen und nutzen ebenfalls Weltmodelle. Diese sind den riesigen KI-Modellen gar nicht unähnlich – sie verstehen Muster und Strukturen. Es gibt Hinweise darauf, dass unsere gesamte menschliche Wahrnehmung und unser Bewusstsein bloß das Output unserer individuellen Weltmodelle ist, beeinflusst durch sensorischen Input und gelernte Abhängigkeiten. Wir kennen unterschiedliche Vorlieben für deutsche Städte, und wir wären nicht überrascht, wenn ein Fremder mit voller Überzeugung behauptet, dass eine der oben genannten Städte „die schönste“ sei.
Für uns gibt es jedoch einen wesentlichen Unterschied zwischen Dingen, die wir für „wahrscheinlich“, „möglich“ oder „denkbar“ halten, und unseren Handlungen und Überzeugungen. In jeder Situation beurteilen wir unsere Handlungen und die Handlungen anderer nicht nach ihrer Wahrscheinlichkeit, sondern nach ihrer Richtigkeit und (deontologischen) Ethik.
Es ist denkbar, dass Menschen mit dem direkten Output ihres Weltmodells handeln. Mir gefällt hier die Analogie zum „System-1“-Denken. Vielleicht handeln wir, wenn wir betrunken oder unkonzentriert sind, einfach „instinktiv“ nach erlerntem Verhalten und Mustern. Diese Outputs des Weltmodells werden allerdings nicht nur durch Beobachtung aufgebaut, sondern auch durch unsere Handlungen und Gedanken. Ein menschliches Weltmodell ist viel mehr als alle Inputs/Beobachtungen der Vergangenheit. Jeder Mensch ist ein wesentlicher Teil seiner eigenen Welt – ein zentraler Aspekt des Weltmodells besteht darin, die Abhängigkeiten zwischen seinen Schöpfer:innen und der Umwelt zu lernen. Unser Weltmodell enthält die Ergebnisse vergangener Handlungen und Kräfte und macht sie habituell und verinnerlicht. Dieses Weltwissen umfasst erlernte und fest codierte emotionale Verbindungen zu Zuständen und Aktivitäten, die ähnlich wie wahrnehmungs- und faktenbasierte Muster abgerufen und geformt werden können.
Es gibt Kräfte jenseits reiner Wahrscheinlichkeitsschätzung in Menschen, die immer aktiv (und essenziell) sind und unsere Handlungen in jeder Situation beeinflussen. Schauen wir uns an, wie wir ein KI-System bauen könnten, das ein ähnliches Verhalten und ähnliche Handlungsfähigkeit zeigt – welche Puzzleteile bräuchten wir dafür?
Von der Landkarte zur Expedition
Machine-Learning-Forscher:innen haben erfolgreich Agenten gebaut, die auf Basis von Weltmodellen in einer moderat komplexen Umgebung handeln. Diese Agenten haben eine funktionale Komponente, die das Weltmodell nutzt, um zu planen, zu bewerten und vorherzusagen. Die Wertfunktionen, die das antreiben, müssen zumindest teilweise von außerhalb des Weltmodells kommen, das zwar Informationen über Werte, Normen und Emotionen enthält, sie aber nicht gewichtet.
Beispielsweise prompte ich Luminous mit einer unangenehmen Situation, und eine der möglichen Completions ist eher konfrontativ.

Wir würden vermutlich alle zustimmen, dass dieses Ergebnis möglich ist – aber ist es wünschenswert? Wenn wir Luminous fragen, können wir aus dem Weltmodell einige Informationen über die Verbindung zu Emotionen, Normen und möglichen Konsequenzen abrufen:

Die gelernte Verbindung zu menschlichen Werten kann einen wichtigen Input liefern, um die richtige Handlungsoption zu wählen (Pro und Kontra abwägen) – aber ein entscheidender Schritt fehlt: Das ist eine Variante des klassischen Sein-Sollen-Problems – das Weltmodell sagt uns, was ist (und sein könnte), hilft uns aber kaum dabei zu entscheiden, was wir anstreben sollten.
In der Realität sind die Linien verschwommen, das beste Modell menschlichen Verhaltens ist diskutabel, und es gibt viele gute Perspektiven darauf. Wenn ich überlege, wie ich menschliche Fähigkeiten und Kräfte in KI replizieren würde, ist diese Architektur vielleicht ein nützlicher erster Entwurf:
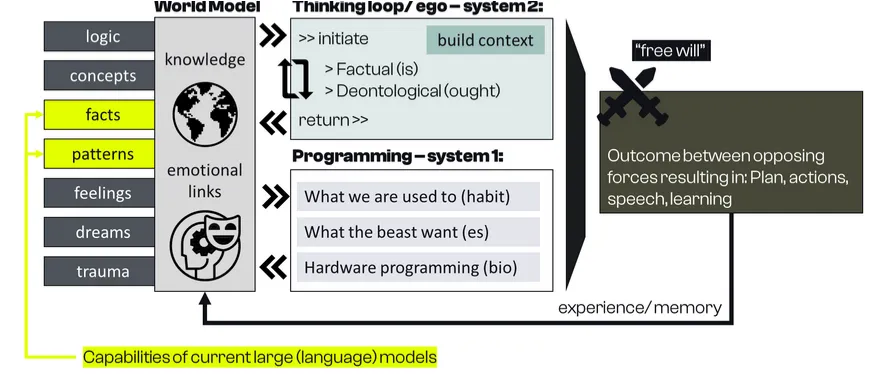
Vergleicht man diese Boxen mit Modellen wie Aleph Alphas Luminous oder GPT-3, lässt sich nur eine kleine Teilmenge in Reichweite dieser Modelle verorten (hier gelb markiert).
Bausteine des Vertrauens
Die Fähigkeiten großer (Sprach-)Modelle werden derzeit intensiv diskutiert – meist mit Fokus auf „Intelligenz“ und kognitive Fähigkeiten. Diese Diskussionen knüpfen in wesentlichen Punkten an die hier präsentierten Gedanken an. Das gezeigte Design kann eine Perspektive darauf liefern, welche funktionalen Bausteine fehlen und wie man etwas mit vergleichbarem Effekt bauen kann. Es gibt eine spannende Diskussion über emergente Eigenschaften – mit der Hypothese, dass AGI schlicht durch Skalierung von Systemen (ohne jedes Feature-Engineering) entstehen könnte. Angesichts der Erfahrungen mit Deep Learning der letzten Jahre erscheint das nicht unmöglich. Dieser Artikel plädiert nicht dafür, dass feature-engineerte Funktionalität der einzige Weg ist, den gewünschten Effekt zu erreichen. Diese Komponenten könnten sich auch nur als eine Art herausstellen, wie wir Funktionalität verstehen.
Gefühle
- Gefühle helfen uns, ein Werturteil für aktuelle oder mögliche zukünftige Zustände, unsere Handlungen und die Handlungen anderer zu bilden
- Das gilt wohl sogar für rational getriebene Werte und Ziele oder wohltätige Arbeit. Das antike Griechenland hatte ein interessantes Konzept für eine positive Emotion, die richtige Handlungen antreibt: Eudaimonie
- Emotionale Verbindungen scheinen zu kommen aus: a) Biologie/Evolution b) Kultur/Epigenetik c) persönlicher Erfahrung d) persönlicher Entwicklung
- Emotionale Bewertung wird stark von möglichen zukünftigen Ergebnissen getrieben. Die aktuellen Modelle enthalten dazu schon einiges an Wissen, daher könnte es möglich sein, ein emotionales Modul mit fest codierten menschenähnlichen Werten zu ergänzen
- Gefühle helfen nicht nur dabei, die richtige Handlung zu finden, sondern treiben auch den Aufbau und die Aktualisierung unseres Weltmodells – als Neugier und Liebe zur Kunst oder als Träume, die Szenarien wiederholen, denen wir (emotional) Aufmerksamkeit schenken sollten
Logik & konzeptuelles Denken
- Menschen scheinen ein Potenzial für symbolisches Schließen entwickelt zu haben. Wir haben Mathematik und Logik erfunden, um Probleme zu lösen, die mit Ähnlichkeiten und Beobachtung allein nicht zu lösen sind. Der rationale Verstand erzeugt ein Signal für sachliche Korrektheit
- Selbst kleine Kinder scheinen Beobachtungen und Gedanken in einen konzeptuellen Raum abbilden zu können, der logische Verarbeitung erlaubt
- Das ist gerade ein heiß diskutiertes Thema. Bei Aleph Alpha arbeiten wir derzeit an etwas (hoffentlich) Einzigartigem in diesem Bereich, das ich nicht spoilern möchte.
Denkschleife (Initiierung und Rückkehr)
- Es scheint einen Trigger zu geben, der eine System-2-„Denkschleife“ starten kann. Sobald der Prozess aktiv ist, baut das Weltmodell durch die Kombination von Wissen und Logik inkrementell neuen Kontext auf. Mit wachsender Kontextkomplexität sind Operationen möglich, die in einem einzelnen Forward-Pass/Gedanken nicht möglich wären. Für Gedanken, die die mentale Kapazität übersteigen, können Hilfsmittel wie ein Stück Papier oder ein Computer nützlich sein. Ein zusätzliches Kriterium kann uns sagen, wann ein Problem gelöst ist, ein Ergebnis zurückgeben und den Prozess beenden.
- Für Reinforcement-Learning-Agenten ist das in der Regel nicht optional. Sie planen ständig und für jede einzelne Handlung auf Basis erlernten Wissens. Das reduziert die Komplexität, erlaubt aber einige starke menschliche Eigenschaften nicht: a) schnelles, müheloses Handeln in einer ruhigen und harmlosen Situation b) dynamische Aufwand- und Zeitverteilung je nach Schwere der Entscheidung
„You're entering a world of pain“
Aktuelle große (Welt-)Modelle sind „nicht vertrauenswürdig“. Diese Modelle sind weder konsistente Wahrheitsmaschinen, noch handeln sie auf Basis irgendwelcher (deontologischer) Werte. Wenn wir ihnen ein Gespür dafür geben, was in der Welt und im Handeln wünschenswert ist, können wir ihnen viele der Verhaltensweisen beibringen, die für uns Menschen wesentlicher Bestandteil von Intelligenz sind. Kombiniert mit Wegen, iterativ zu „denken“ (Kontext rekursiv mit Hilfe gelernter Muster aufzubauen), würden gelernte Werte zuverlässige Navigation in einer komplexen Umgebung erlauben – geführt durch die Struktur im Weltmodell. Menschliche leitende Emotionen sind mit der wahrgenommenen und imaginierten Welt und dem Selbst verbunden, existieren auf einer anderen Abstraktionsebene – und erlauben es uns, selbst radikal neue Situationen weitgehend konsistent zu handhaben. Diese Werkzeuge zur Navigation von Möglichkeiten fehlen in den heutigen großen KI-Modellen. Kein Maß an Datenverteilungs-Shift wird das schlussendlich lösen: Wenn wir KI vertrauen wollen, müssen wir ihr vielleicht wehtun.
Autor: Jonas Andrulis (Gründer & CEO von Aleph Alpha)
Dieser Artikel wurde ursprünglich am 9. April 2022 auf http://andrulis.tech/index.html veröffentlicht.